pflowtts_pytorch
1.0.0
samples . LJSPEECH Pretraned CKPT - GDRive Link Multispeaker VCTK PretradosImplementación no oficial del documento P-Flow: un TTS de disparo cero rápido y eficiente en datos a través de la solicitud de habla por NVIDIA.
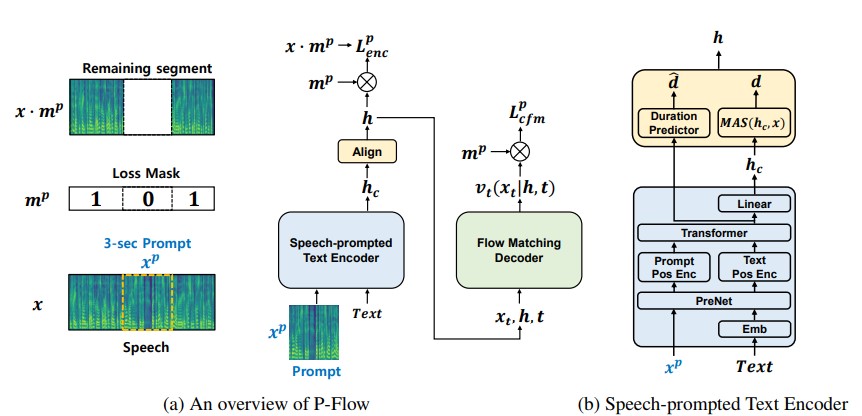
Si bien los recientes modelos de lenguaje de códec de códecs neural a gran escala han mostrado una mejora significativa en TTS de disparo cero mediante el entrenamiento en miles de horas de datos, sufren inconvenientes como la falta de robustez, la velocidad de muestreo lenta similar a los métodos TTS autorregresivos previos y la dependencia de las representaciones de códigos neurales previamente capacitados. Nuestro trabajo propone P-Flow, un modelo TTS de disparo cero rápido y eficiente en datos que utiliza indicaciones del habla para la adaptación del altavoz. P-Flow comprende un codificador de texto controlado por el habla para la adaptación de los hablantes y un decodificador generativo de flujo para la síntesis de voz rápida y de alta calidad. Nuestro codificador de texto prometido por el habla utiliza indicaciones del habla y la entrada de texto para generar una representación de texto condicional de los altavoces. El decodificador generativo que coincide con el flujo utiliza la salida condicional del altavoz para sintetizar el habla personalizada de alta calidad significativamente más rápido que en tiempo real. A diferencia de los modelos de lenguaje de códec neural, capacitamos específicamente a P-Flow en el conjunto de datos de Libritts utilizando una representación continua de MEL. A través de nuestro método de entrenamiento utilizando indicaciones continuas del habla, P-Flow coincide con el rendimiento de similitud del altavoz de los modelos TTS de disparo cero a gran escala con dos órdenes de magnitud menos datos de entrenamiento y tiene una velocidad de muestreo más rápida de 20 ×. Nuestros resultados muestran que P-Flow tiene una mejor pronunciación y se prefiere a la semejanza humana y la similitud de los oradores con sus recientes homólogos de última generación, definiendo así P-Flow como una alternativa atractiva y deseable.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsPermanezca en el directorio de la raíz (¡por supuesto, clona el repositorio primero!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceSupongamos que estamos entrenando con el discurso de LJ
data/LJSpeech-1.1 y prepare las listas de archivos para señalar los datos extraídos como para el elemento 5 en la configuración del repositorio Nvidia Tacotron 2. 3a. Vaya a configs/data/ljspeech.yaml y cambie
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3B. Comandos de ayuda para el perezoso
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} Actualice estos valores en configs/data/ljspeech.yaml en la tecla data_statistics .
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101a los caminos de su tren y validación filelistas.
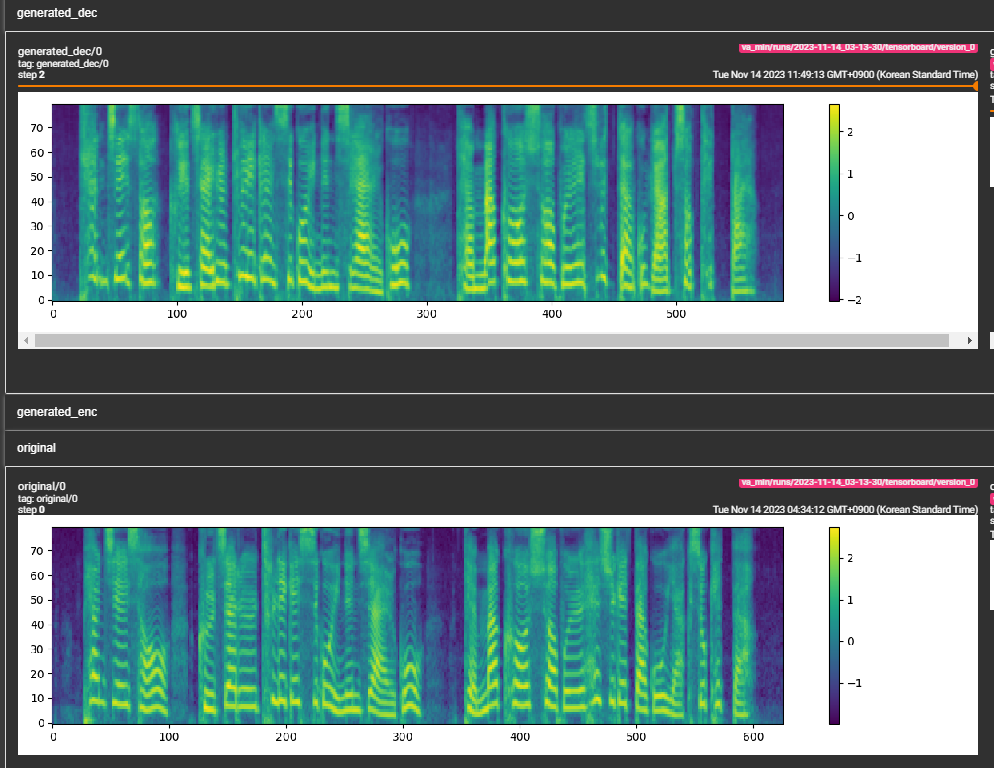
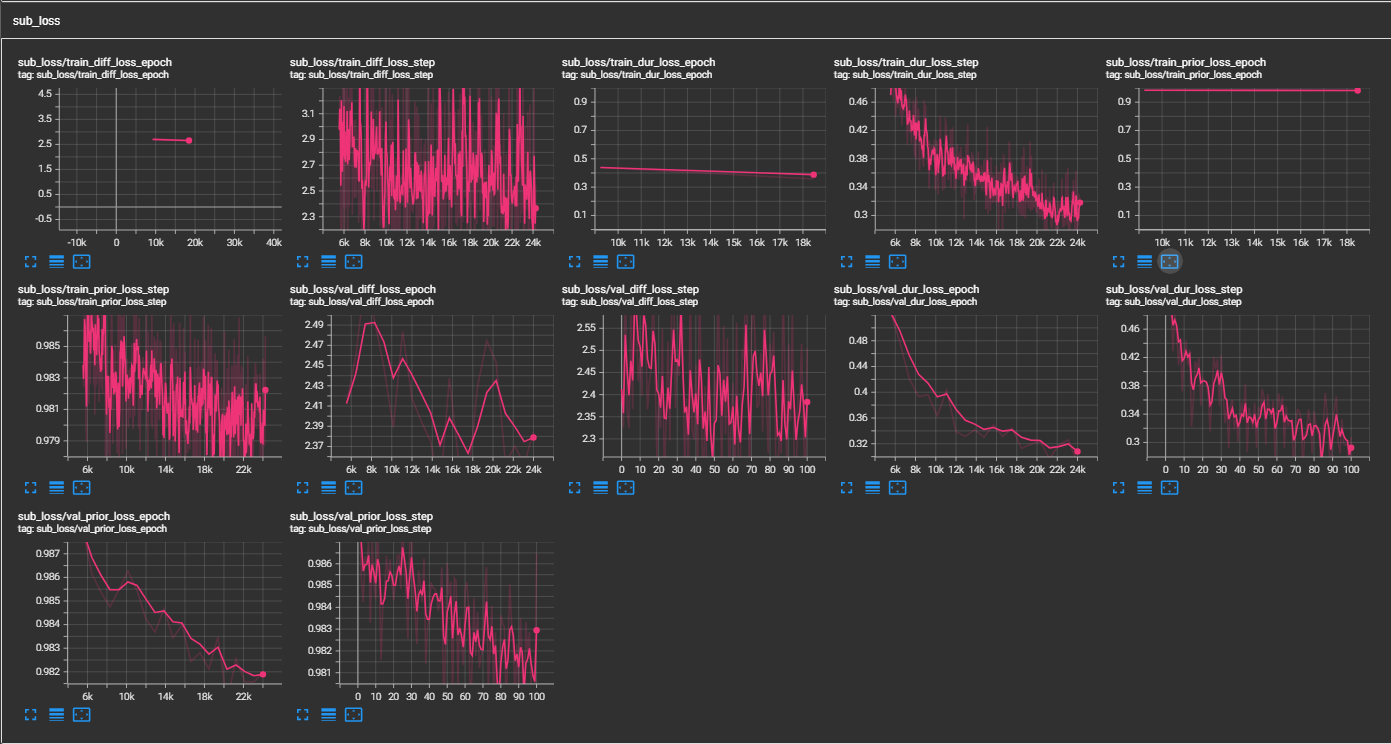
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks para una prueba rápida en seco y pruebas de arquitectura del modelo. 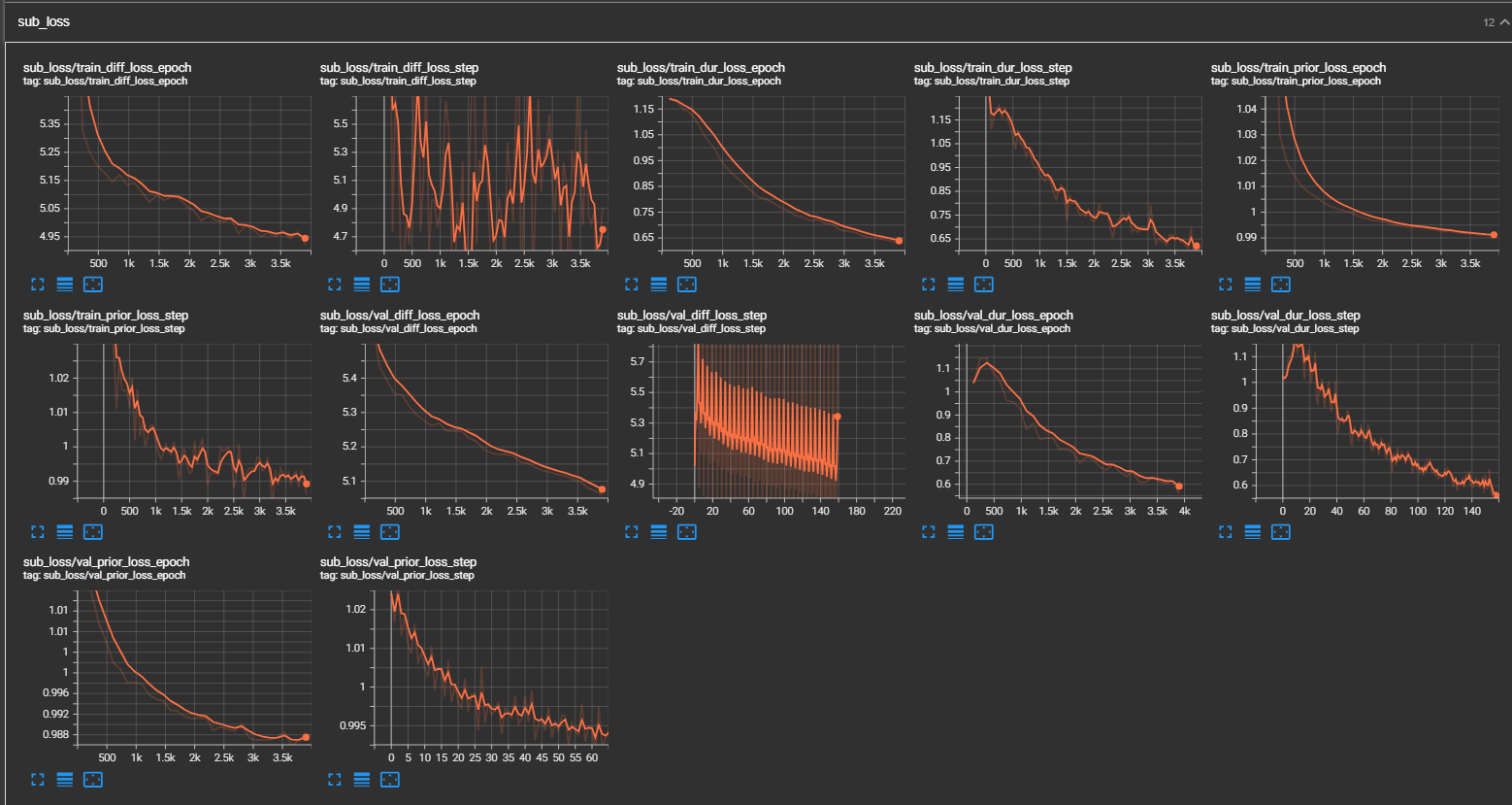
samples . (LJSpeech entrenado para 300k pasos) El papel recomienda 800k pasos. min_sample_size (el valor predeterminado es 4s; para que ese aviso sea al menos 3s y la predicción es al menos 1S)prompt_size en las configuraciones (modelos/pflow.yaml) para controlar el tamaño de la solicitud. Es el número de marcos MEL que se utilizarán como indicador de la muestra WAV en Traning. (El valor predeterminado es ~ 3s; 3*22050 // 256 = 258; redondeado a 264 en configuraciones)dur_p_use_log en las configs (modelos/pflow.yaml) para controlar si usar el registro de predicción de duración o no para el cálculo de pérdidas. (El valor predeterminado es falso ahora) Mi hipótesis es que la pérdida de MSE de duraciones log no funciona bien para pausas más largas, etc. (debido a la naturaleza de la función logarítmica). Por lo tanto, solo e las duraciones de los registros antes de calcular la pérdida. La forma alternativa puede ser usar Relu en lugar de log.transfer_ckpt_path en las configuraciones (trenes.yaml) para controlar la ruta del CKPT que se utilizará para el aprendizaje de transferencia. (predeterminado no es ninguno) si ninguno, entonces el modelo está entrenado desde cero. Si no es ninguno, entonces el modelo se carga desde la ruta CKPT y se entrena desde el paso 0. En caso de que ckpt_path tampoco sea ninguno, entonces el modelo se carga desde ckpt_path y se entrena desde el paso en el que se guardó. transfer_ckpt_path puede manejar los coincidencias de tamaño de la capa entre el CKPT y el modelo. export.py e inference.py para exportar y probar el modelo. (Los arguemnts se explican por sí mismos) 

