pflowtts_pytorch
1.0.0
samples . Ljspeech pretrained ckpt - gdrive link multispeaker vctk pretrained ckpt (1100 zaman di vctk) - huggingfaceImplementasi tidak resmi dari makalah P-flow: TT zero-shot yang cepat dan efisien melalui data yang diminta oleh NVIDIA.
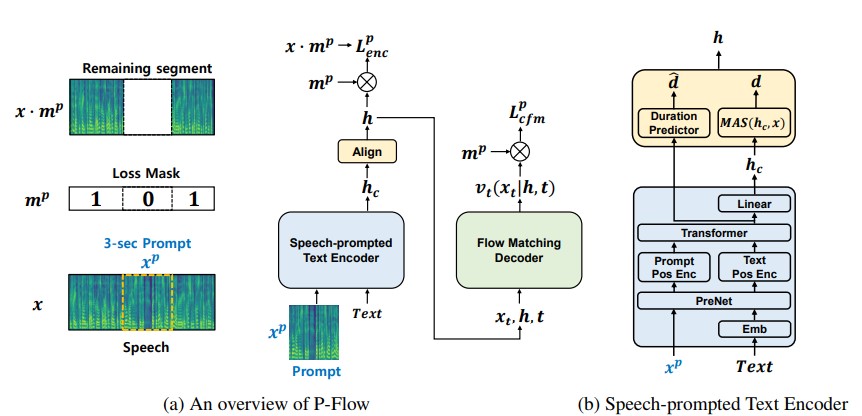
Sementara model bahasa codec saraf skala besar baru-baru ini telah menunjukkan peningkatan yang signifikan dalam TT nol-shot dengan melatih ribuan jam data, mereka menderita kelemahan seperti kurangnya ketahanan, kecepatan pengambilan sampel yang lambat mirip dengan metode TTS autoregresif sebelumnya, dan ketergantungan pada representasi codec saraf pra-terlatih. Pekerjaan kami mengusulkan P-FLOW, model TTS nol-shot yang cepat dan efisien data yang menggunakan petunjuk ucapan untuk adaptasi pembicara. P-FLOW terdiri dari encoder teks yang dikomplekskan untuk adaptasi speaker dan aliran decoder generatif yang cocok untuk sintesis wicara yang berkualitas tinggi dan cepat. Encoder teks yang diprompetikan oleh wicara kami menggunakan prompt ucapan dan input teks untuk menghasilkan representasi teks pembicara-kondisional. Decoder generatif yang cocok dengan aliran menggunakan output speaker-conditional untuk mensintesis ucapan pribadi berkualitas tinggi secara signifikan lebih cepat daripada secara real-time. Berbeda dengan model bahasa Codec Neural, kami secara khusus melatih P-FLOW pada dataset Libritts menggunakan representasi Mel yang berkelanjutan. Melalui metode pelatihan kami menggunakan permintaan ucapan terus menerus, P-FLOW cocok dengan kinerja kesamaan speaker dari model TTS nol-shot skala besar dengan dua urutan data pelatihan yang lebih sedikit dan memiliki lebih dari 20 × kecepatan pengambilan sampel yang lebih cepat. Hasil kami menunjukkan bahwa P-flow memiliki pengucapan yang lebih baik dan lebih disukai dalam kemiripan manusia dan kemiripan pembicara dengan rekan-rekan canggih baru-baru ini, sehingga mendefinisikan P-FLOW sebagai alternatif yang menarik dan diinginkan.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsTetap di direktori root (tentu saja klon repo terlebih dahulu!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceMari kita asumsikan kita berlatih dengan pidato LJ
data/LJSpeech-1.1 , dan siapkan daftar file untuk menunjuk ke data yang diekstraksi seperti untuk item 5 dalam pengaturan repo NVIDIA TACOTRON 2. 3a. Buka configs/data/ljspeech.yaml dan ubah
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3b. Perintah pembantu untuk malas
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} Perbarui nilai -nilai ini di configs/data/ljspeech.yaml di bawah kunci data_statistics .
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101ke jalur kereta kereta dan validasi Anda.
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks untuk pengujian cepat kering dan pengujian arsitektur model. 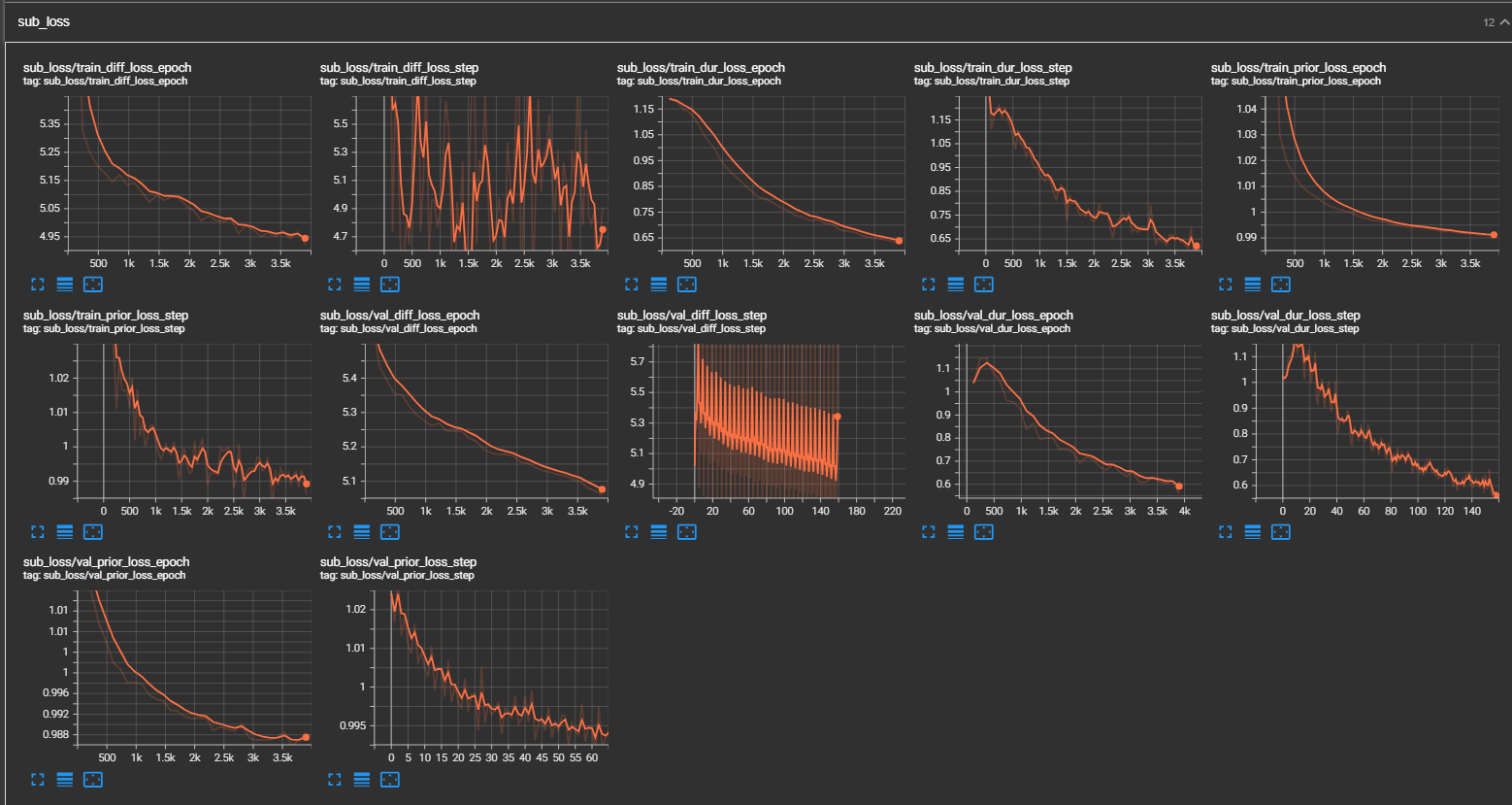
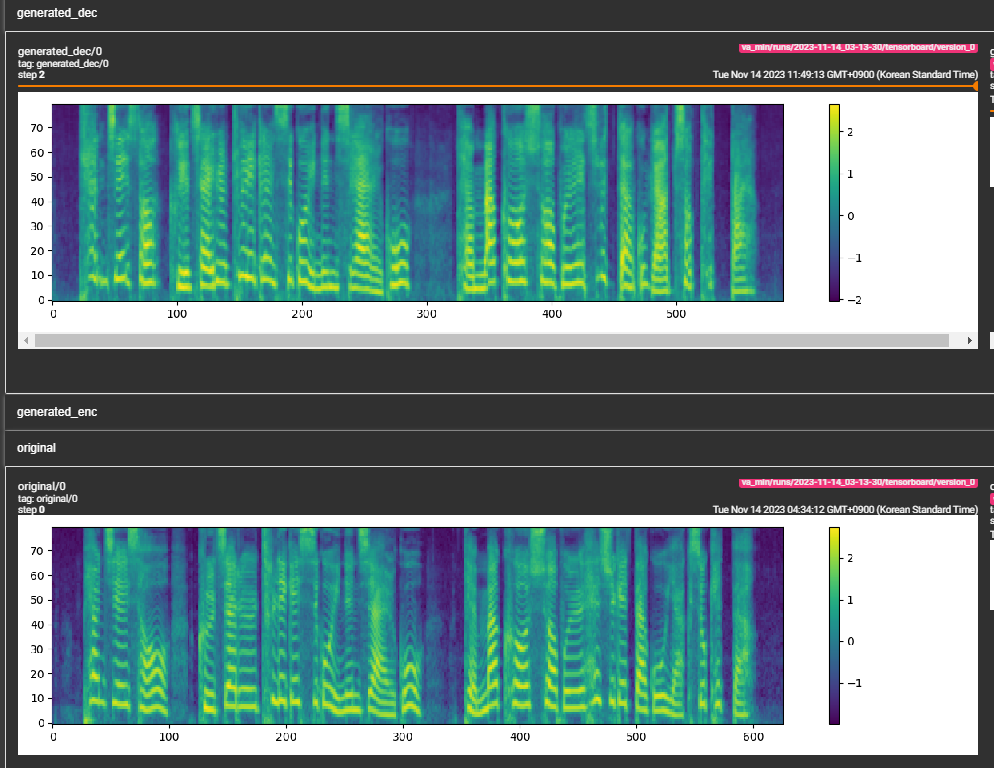
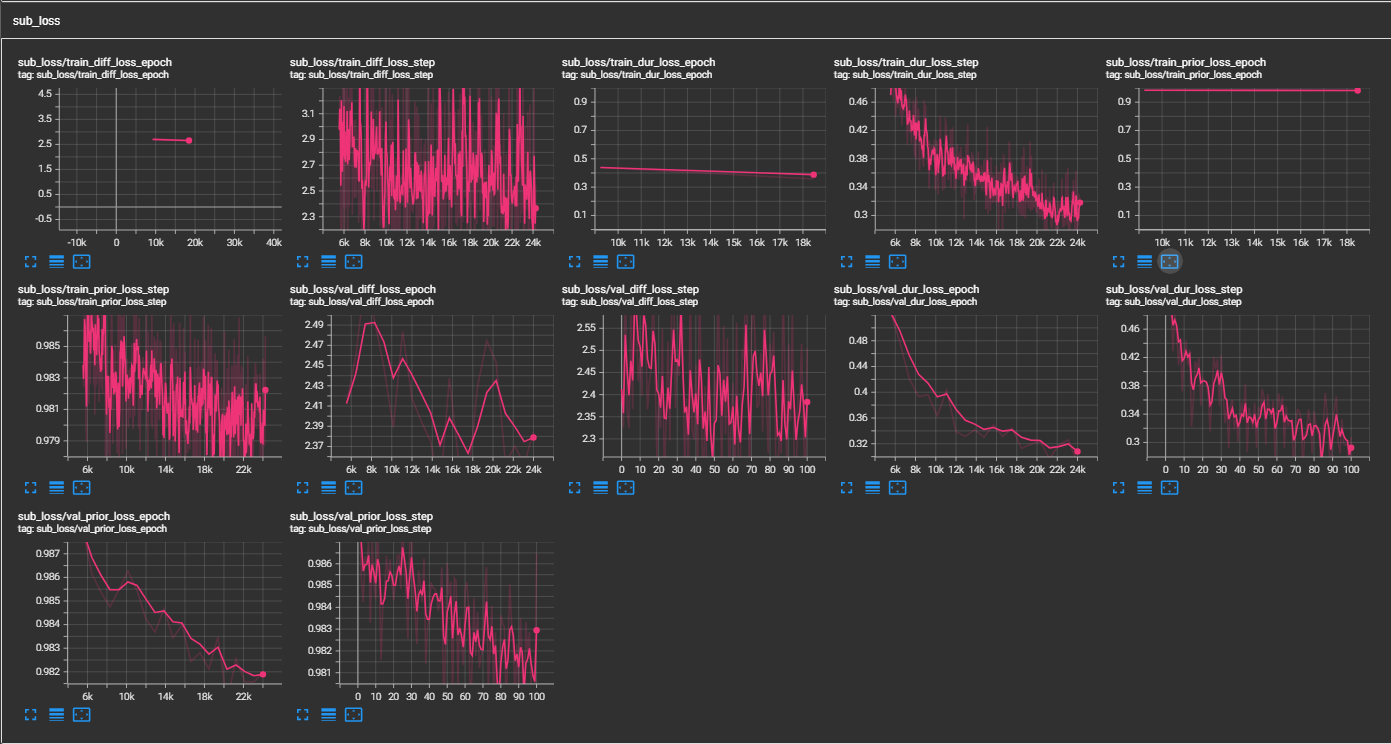
samples . (LJSPEECH yang dilatih untuk 300 ribu langkah) Kertas merekomendasikan 800 ribu langkah. min_sample_size (default adalah 4s; sehingga prompt setidaknya 3s dan prediksi setidaknya 1s)prompt_size di konfigurasi (model/pflow.yaml) untuk mengontrol ukuran prompt. Ini adalah jumlah bingkai MEL yang akan digunakan sebagai prompt dari sampel WAV saat trans. (default adalah ~ 3s; 3*22050 // 256 = 258; bulat menjadi 264 dalam konfigurasi)dur_p_use_log di konfigurasi (model/pflow.yaml) untuk mengontrol apakah akan menggunakan log prediksi durasi atau tidak untuk perhitungan kerugian. (Default false sekarang) Hipotesis saya adalah bahwa durasi log kehilangan MSE tidak bekerja dengan baik untuk jeda lebih lama dll (karena sifat fungsi log). Jadi, kami hanya e daya pada durasi log sebelum menghitung kerugian. Cara alternatif dapat menggunakan Relu, bukan log.transfer_ckpt_path di konfigurasi (train.yaml) untuk mengontrol jalur CKPT yang akan digunakan untuk pembelajaran transfer. (Default tidak ada) jika tidak ada, maka model dilatih dari awal. Jika tidak, maka model dimuat dari jalur CKPT dan dilatih dari langkah 0. Dalam kasus, ckpt_path juga tidak ada, maka model dimuat dari ckpt_path dan dilatih dari langkah yang disimpan di. transfer_ckpt_path dapat menangani ketidakcocokan ukuran lapisan antara CKPT dan model. export.py dan inference.py untuk mengekspor dan menguji model. (Arguemnts jelas) 

