pflowtts_pytorch
1.0.0
samples -Ordner an. Ljspeech vorgebliebener CKPT - DDRIVE LINK Multispeaker VCTK VCTK Present CKPT (1100 Epoche auf VCTK) - UmarmungfaceInoffizielle Implementierung des Papiers P-Flow: Eine schnelle und dateneffiziente Null-Shot-TTS durch Sprache, die von NVIDIA auffordert.
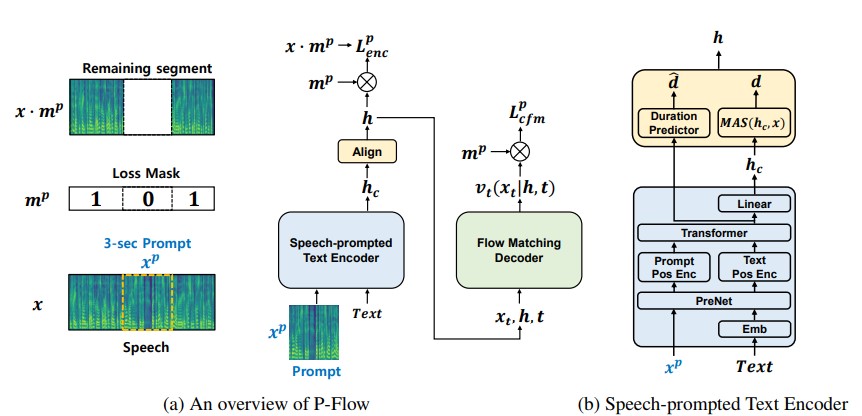
Während jüngste groß angelegte neuronale Codec-Sprachmodelle durch das Training von Tausenden von Daten von Daten eine signifikante Verbesserung der Null-Shot-TTs gezeigt haben, leiden sie unter Nachteilen wie mangelnder Robustheit, langsamer Abtastgeschwindigkeit ähnlich wie frühere autoregressive TTS-Methoden und die Abhängigkeit von vor ausgebildeten Nerven-Codec-Darstellungen. Unsere Arbeit schlägt P-Flow vor, ein schnelles und dateneffizientes Null-Shot-TTS-Modell, das Sprachaufforderungen für die Anpassung der Sprecher verwendet. P-FLOW umfasst einen Sprachentwickler für die Anpassung der Sprecher und einen Fluss, der generativen Decoder für eine qualitativ hochwertige und schnelle Sprachsynthese entspricht. Unser sprachversprechender Textcodierer verwendet Sprachaufforderungen und Texteingaben, um die Repräsentation des sprecher-konditionellen Textes zu generieren. Der Flow-Matching Generative Decoder verwendet die sprecher-konditionelle Ausgabe, um hochwertige personalisierte Sprache wesentlich schneller als in Echtzeit zu synthetisieren. Im Gegensatz zu den neuronalen Codec-Sprachmodellen trainieren wir P-F-F-F-F-F-F-F-F-Flow mit einer kontinuierlichen Mel-Repräsentation im Datensatz von Libritts. Durch unsere Trainingsmethode unter Verwendung von kontinuierlichen Sprachanträgen entspricht P-Flow mit der Leistung der Lautsprecher-Ähnlichkeit der großen TTS-Modelle mit Null-Shot-TTS mit zwei Größenordnungen weniger Trainingsdaten und hat mehr als 20 × schnellere Abtastgeschwindigkeit. Unsere Ergebnisse zeigen, dass P-Flow eine bessere Aussprache hat und in der Ähnlichkeit des Menschen und der Sprecher-Ähnlichkeit zu seinen jüngsten hochmodernen Gegenstücken bevorzugt wird, wodurch P-Flow als attraktive und wünschenswerte Alternative definiert wird.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsBleiben Sie im Root -Verzeichnis (klonen Sie natürlich zuerst das Repo!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceNehmen wir an, wir trainieren mit LJ -Sprache
data/LJSpeech-1.1 und bereiten Sie die Dateilisten so vor, dass sie auf die extrahierten Daten wie für Punkt 5 im Setup des NVIDIA Tacotron 2 Repo verweisen. 3a. Gehen Sie zu configs/data/ljspeech.yaml und ändern Sie
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3b. Helferbefehle für die Faulen
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} Aktualisieren Sie diese Werte in configs/data/ljspeech.yaml unter data_statistics -Schlüssel.
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101auf die Wege Ihres Zug- und Validierungsfilelisten.
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks für einen schnellen Trockenlauf- und Architekturtest des Modells. 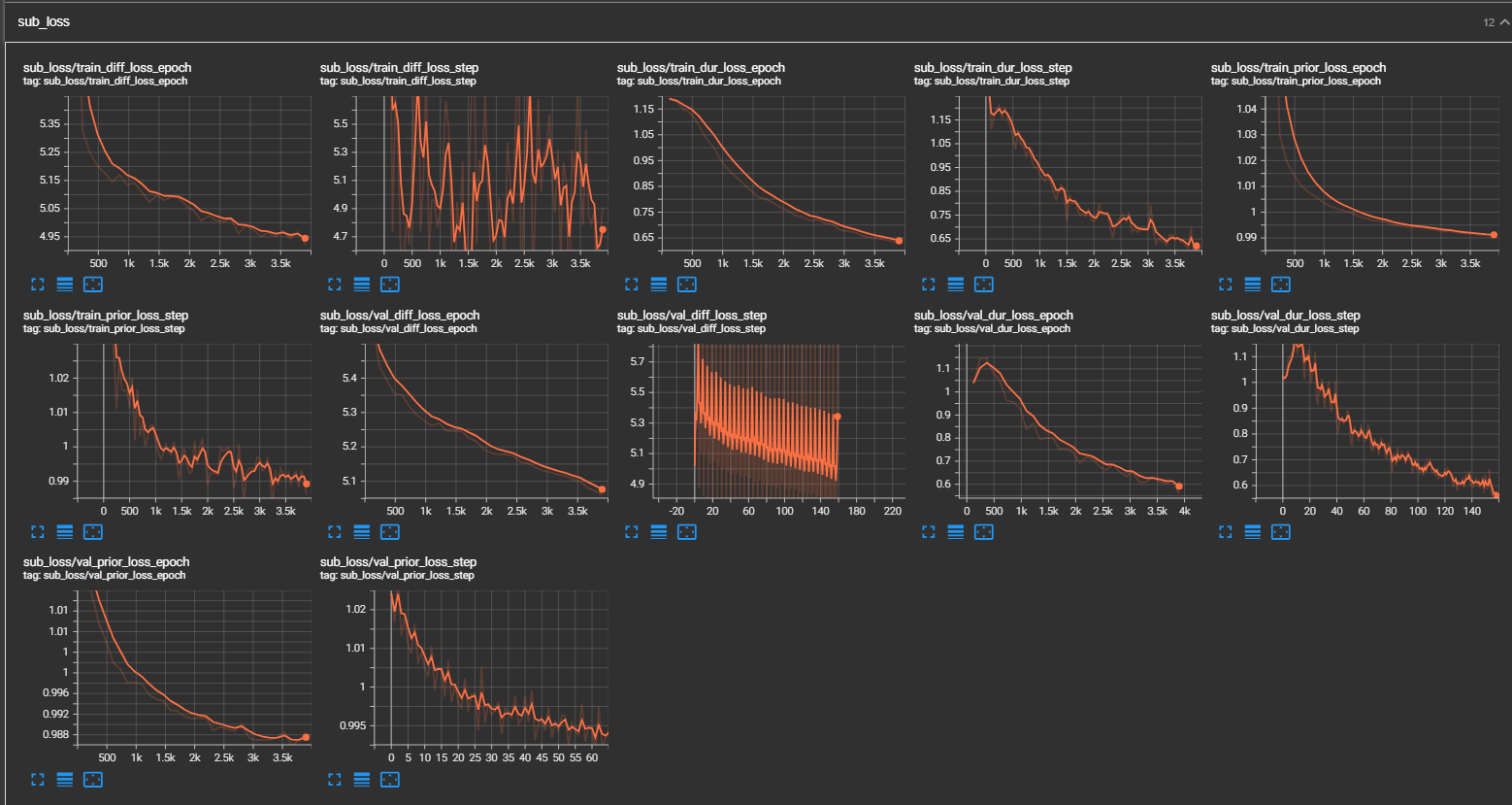
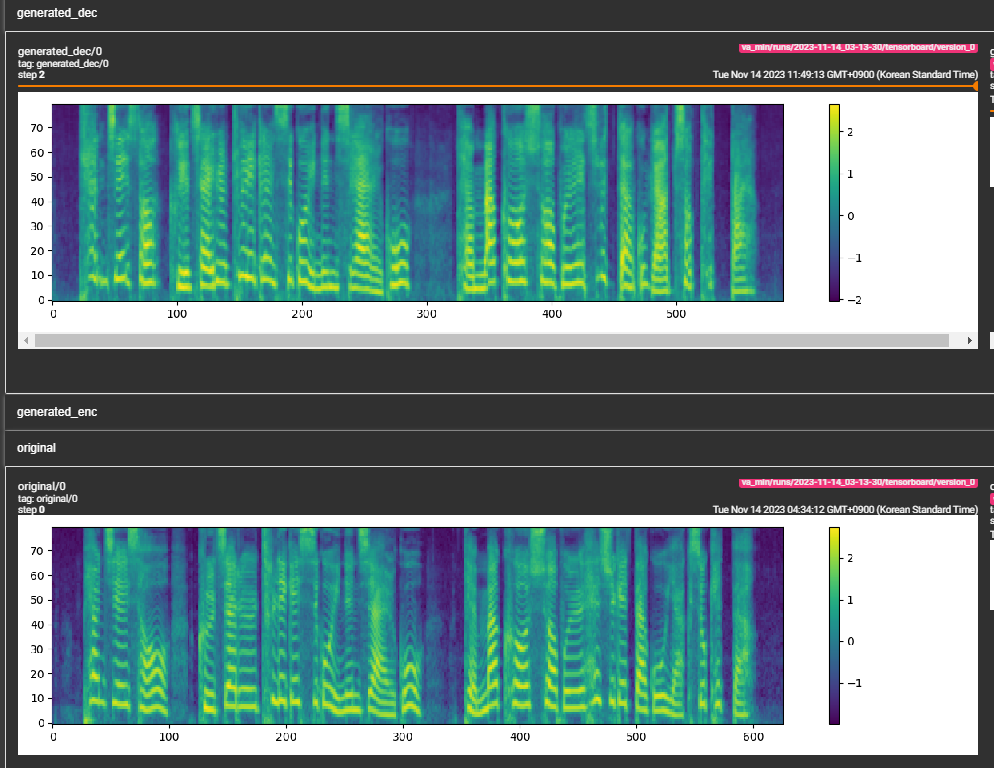
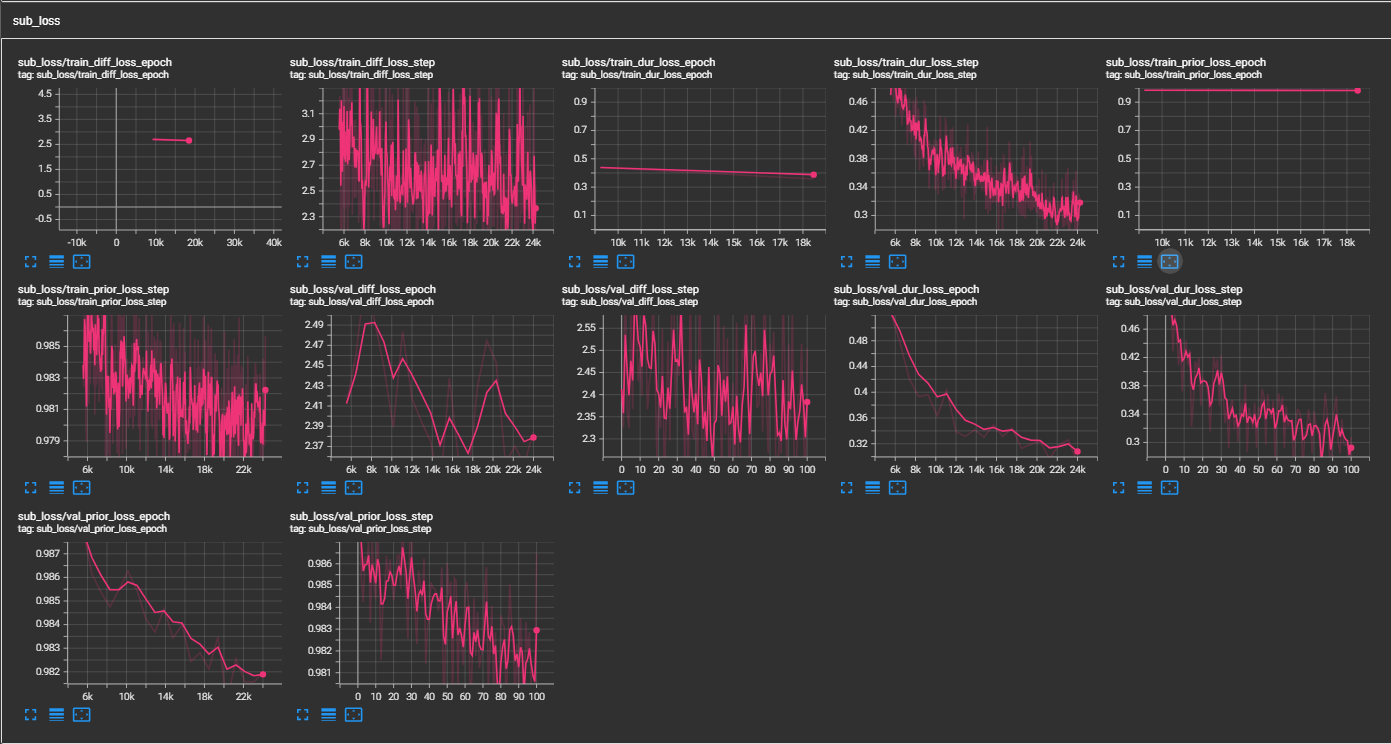
samples -Ordner an. (LJspeech für 300.000 Schritte) Papier empfiehlt 800.000 Schritte. min_sample_size (Standard ist 4S; so dass die Eingabeaufforderung mindestens 3s beträgt und die Vorhersage ist mindestens 1s), minimaler WAV -Beispielgröße (in Sekunden) hinzugefügt (in Sekunden), min_sample_size (Standard ist 4S;prompt_size hinzugefügt, um die Größe der Eingabeaufforderung zu steuern. Es ist die Anzahl der MEL -Rahmen, die als Eingabeaufforderung aus der WAV -Probe beim Übergang verwendet werden. (Standard ist ~ 3s; 3*22050 // 256 = 258; in Konfigurationen auf 264 abgerundet)dur_p_use_log hinzu, um zu steuern, ob das Protokoll der Dauer -Vorhersage verwendet werden soll oder nicht für die Berechnung des Verlustes. (Default ist jetzt falsch) Meine Hypothese ist, dass der MSE -Verlust des Protokolldauerns für längere Pausen usw. nicht gut funktioniert (aufgrund der Art der Protokollfunktion). Wir e also nur die logarithmischen Dauern mit Strom versorgt, bevor wir den Verlust berechnen. Alternativer Weg kann Relu anstelle von Protokoll verwenden.transfer_ckpt_path hinzu, um den Pfad des CKPT zu steuern, der zum Übertragungslernen verwendet werden soll. (Standard ist keine) Wenn keine, dann wird das Modell von Grund auf neu trainiert. Wenn nicht keine, wird das Modell aus dem CKPT -Pfad geladen und aus Schritt 0 trainiert. Für den Fall ist ckpt_path auch keine, dann wird das Modell von ckpt_path geladen und aus dem Schritt trainiert, bei dem es gespeichert wurde. transfer_ckpt_path kann die Schichtgröße nicht übereinstimmen, zwischen dem CKPT und dem Modell. export.py und inference.py , um das Modell zu exportieren und zu testen. (Die Argumente sind selbsterklärend) 

