pflowtts_pytorch
1.0.0
samples . LJSPEECH Pretended CKPT - GDRIVE LINK MULTIPLECKER VCTK Pretending CKPT (1100 EPOCH ON VCTK) - HUGGINGFACEНеофициальная реализация бумаги P-Flow: быстрое и эффективное TTS с нулевым выстрелом посредством речи NVIDIA.
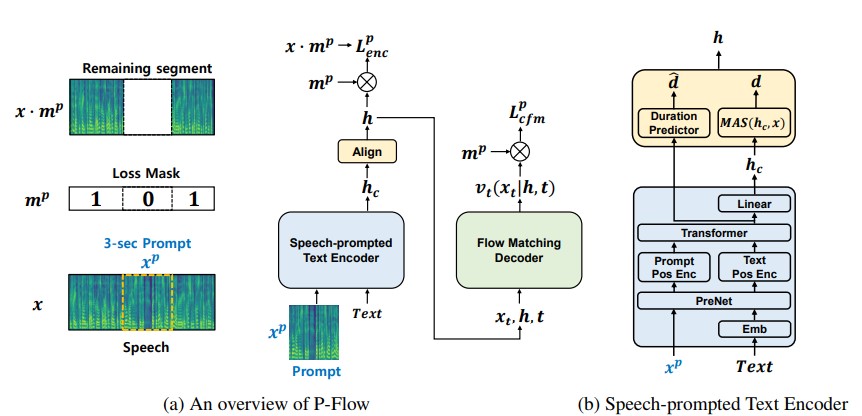
В то время как недавние крупномасштабные языковые модели нейронного кодека показали значительное улучшение с нулевым выстрелом, обучаясь на тысячи часов данных, они страдают от недостатков, таких как отсутствие устойчивости, медленная скорость отбора проб, аналогичную предыдущим методам авторегрессии TTS, и зависимость от предварительно обученных представлений о нейральном коде. Наша работа предлагает P-Flow, быструю и эффективную модель TTS с нулевым выстрелом, которая использует речевые подсказки для адаптации динамиков. P-Flow включает в себя речевой текстовый энкодер для адаптации динамика и генеративный декодер, соответствующий потоку для высококачественного и быстрого синтеза речи. Наш текстовый энкодер, выдвинутый речью, использует речевые подсказки и ввод текста для генерации кондиционерного представления текста. Генеративный декодер, соответствующий потоку, использует выходы динамиков для синтеза высококачественной персонализированной речи значительно быстрее, чем в режиме реального времени. В отличие от языковых моделей нейронного кодека, мы специально обучаем P-Flow на наборе данных Libritts, используя непрерывную мель-предложение. Благодаря нашему методу обучения с использованием непрерывных речевых подсказок, P-Flow соответствует производительности сходства динамиков крупномасштабных моделей с нулевым выстрелом TTS с двумя порядками меньше данных обучения и имеет более чем на 20 × более высокую скорость отбора проб. Наши результаты показывают, что P-Flow имеет лучшее произношение и предпочтительнее человеческого сходства и сходства динамиков с его недавними современными аналогами, таким образом определяя P-Flow как привлекательную и желательную альтернативу.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsОставайтесь в корневом каталоге (конечно, сначала клонировать репо!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceДавайте предположим, что мы тренируемся с речью LJ
data/LJSpeech-1.1 и подготовите списки файлов, чтобы указать на извлеченные данные, как для пункта 5, в настройке репозиции NVIDIA Tacotron 2. 3A. Перейдите в configs/data/ljspeech.yaml и изменить
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3B. Помощник командует ленивым
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} Обновите эти значения в configs/data/ljspeech.yaml под ключом data_statistics .
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101на пути вашего поезда и проверки файлов.
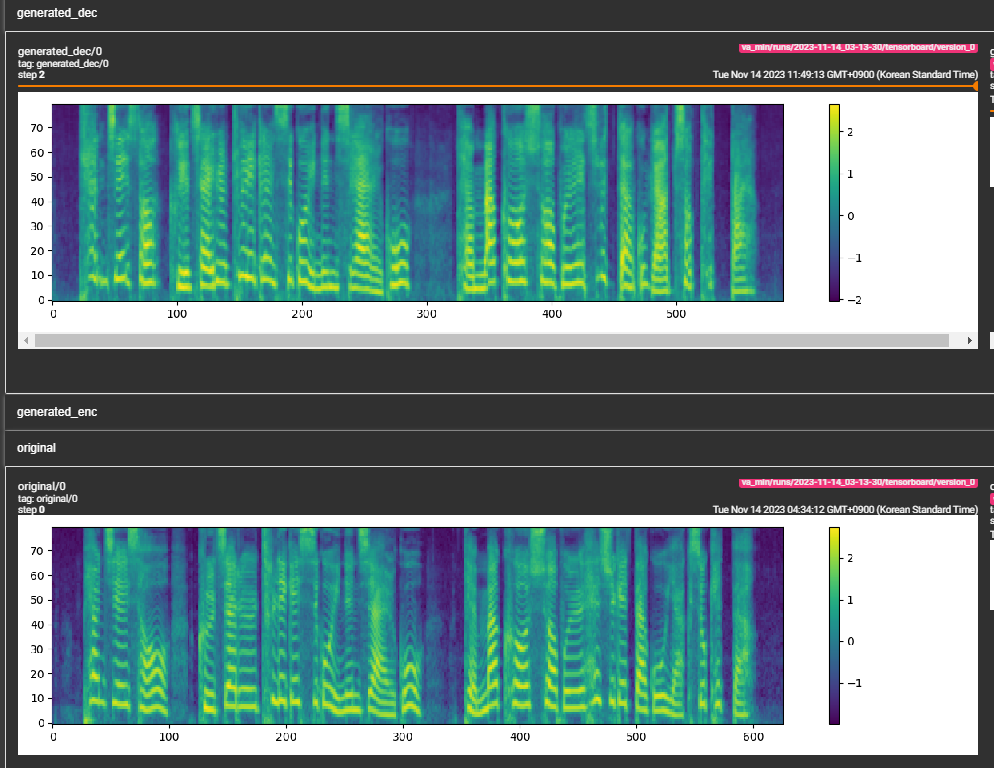
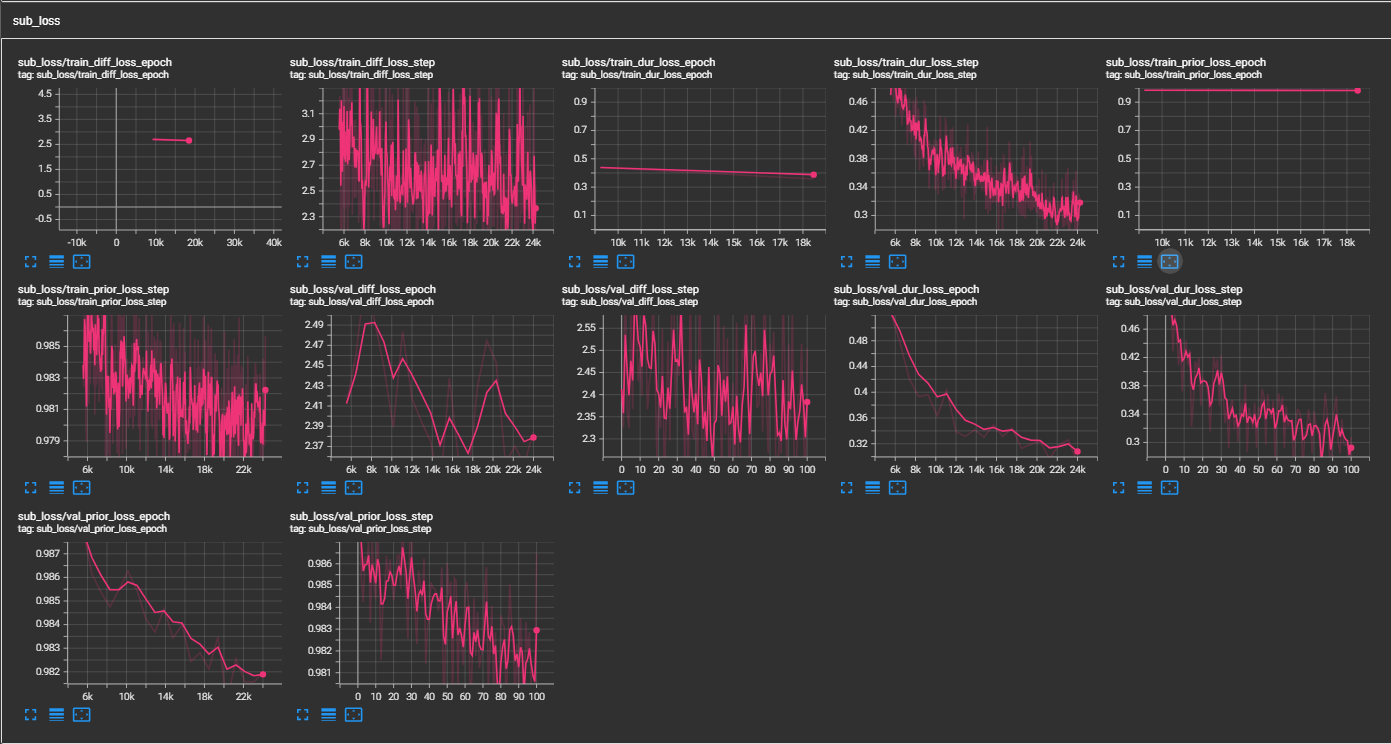
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks для быстрого сухого пробега и архитектурного тестирования модели. 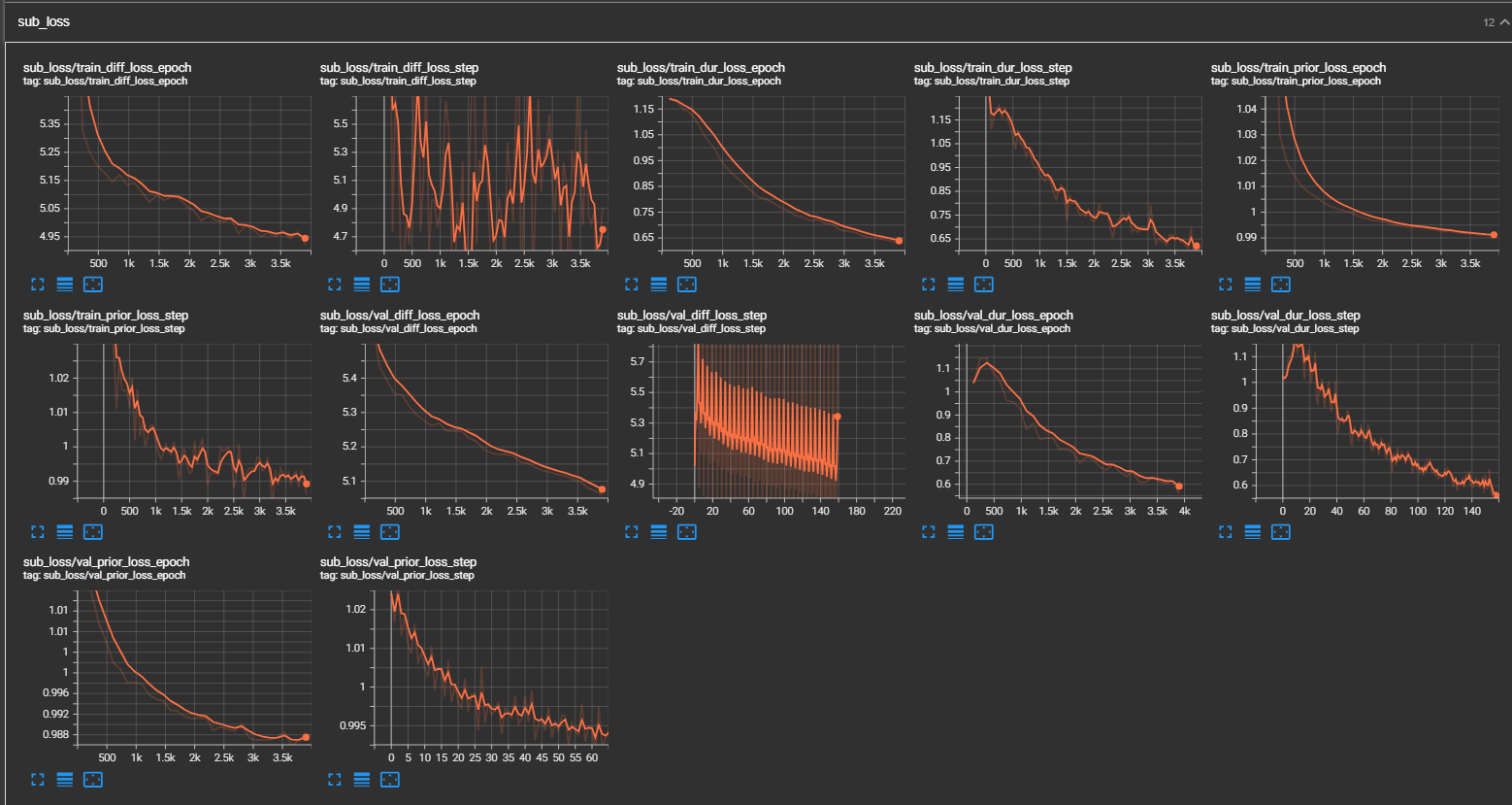
samples . (LJSPEECH, обученная для 300 тыс . min_sample_size (по умолчанию 4S; так, что подсказка не менее 3 с, а прогноз - не менее 1 с)prompt_size в configs (models/pflow.yaml) для управления размером подсказки. Это количество кадров MEL, которые будут использоваться в качестве приглашения из образца WAV при транинге. (По умолчанию ~ 3S; 3*22050 // 256 = 258; округлен до 264 в конфигурации)dur_p_use_log в конфигурации (модели/pflow.yaml), чтобы управлять, использовать ли журнал прогнозирования продолжительности или нет для расчета потерь. (По умолчанию неверно). Моя гипотеза заключается в том, что потери длительности журнала MSE не очень хорошо работают для более длительных паузов и т. Д. (Из -за характера логарифмической функции). Таким образом, мы просто e длительность журнала, прежде чем вычислять потерю. Альтернативный способ может использовать RELU вместо журнала.transfer_ckpt_path в конфигурации (Train.yaml) для управления пути CKPT для использования для обучения передачи. (По умолчанию нет), если нет, то модель обучается с нуля. Если нет ни одного, то модель загружается из пути CKPT и обучается с шага 0. В случае, если ckpt_path также не является ни одной, то модель загружается из ckpt_path и обучена на шаге, на которой она была сохранена. transfer_ckpt_path может обрабатывать несоответствия размера слоя между CKPT и моделью. export.py и inference.py для экспорта и проверки модели. (Аргунты самоуверны) 

