pflowtts_pytorch
1.0.0
samples 폴더를 확인하십시오. ljspeech 사전 상처 CKPT -GDRIVE 링크 멀티 스피커 vctk 사전 법 CKPT (VCTK의 1100 Epoch) - Huggingface논문 p- 흐름의 비공식적 구현 : Nvidia의 연설을 통한 빠르고 데이터 효율적인 제로 샷 tts.
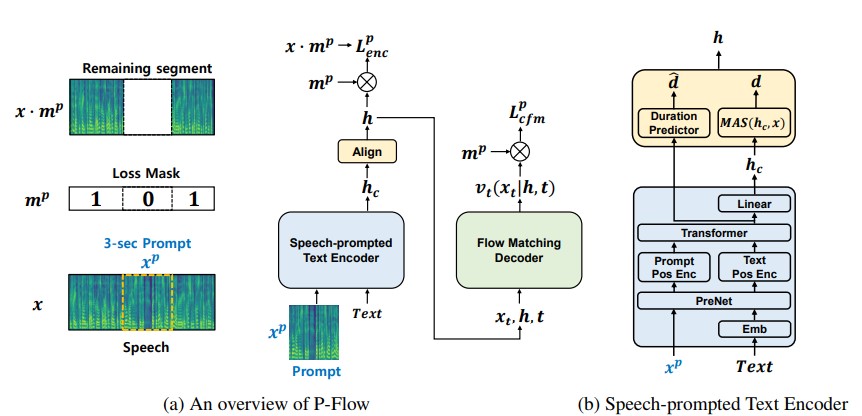
최근의 대규모 신경 코덱 언어 모델은 수천 시간의 데이터에 대한 교육을 통해 제로 샷 TTS가 크게 개선되었지만, 견고성 부족, 이전의자가 논쟁 TTS 방법과 유사한 느린 샘플링 속도 및 사전 훈련 된 신경 코덱 표현에 대한 의존과 같은 단점이 있습니다. 우리의 작업은 스피커 적응을 위해 음성 프롬프트를 사용하는 빠르고 데이터 효율적인 제로 샷 TTS 모델 인 p- 플로를 제안합니다. P- 플로우는 스피커 적응을위한 음성 배송 텍스트 인코더와 고품질 및 빠른 음성 합성을위한 유동 일치 생성 디코더로 구성됩니다. 우리의 연설 촉진 텍스트 인코더는 음성 프롬프트와 텍스트 입력을 사용하여 스피커 조건부 텍스트 표현을 생성합니다. 유동 일치 생성 디코더는 스피커 조건부 출력을 사용하여 실시간보다 훨씬 빠른 고품질 개인화 된 음성을 합성합니다. 신경 코덱 언어 모델과 달리, 우리는 특히 연속 Mel-representation을 사용하여 Libritts 데이터 세트에서 p- 플로우를 훈련시킵니다. 연속적인 음성 프롬프트를 사용하는 교육 방법을 통해 P- 플로우는 대규모 제로 샷 TTS 모델의 스피커 유사성 성능과 2 배의 훈련 데이터가 적고 20 배 이상 빠른 샘플링 속도를 가지고 있습니다. 우리의 결과 P- 흐름은 더 나은 발음을 가지고 있으며 최근 최첨단 대응 물과 인간의 유사성 및 스피커 유사성에서 선호되므로 P- 플로우를 매력적이고 바람직한 대안으로 정의합니다.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowtts루트 디렉토리에 머무르십시오 (물론 레포를 먼저 복제하십시오!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplace우리가 LJ 연설로 훈련하고 있다고 가정 해 봅시다
data/LJSpeech-1.1 로 추출한 다음 Nvidia Tacotron 2 Repo 설정에서 항목 5와 같이 추출 된 데이터를 가리 키도록 파일 목록을 준비하십시오. 3A. configs/data/ljspeech.yaml 로 이동하여 변경하십시오
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3B. 게으른 사람에 대한 도우미 명령
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} data_statistics 키에서 configs/data/ljspeech.yaml 에서이 값을 업데이트하십시오.
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101열차와 검증 파일리스트의 길에.
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks 확인하십시오. 
samples 폴더를 확인하십시오. (LJSpeech 300K 계단으로 훈련) 종이는 800K 단계를 권장합니다. min_sample_size (기본값은 4s이고 프롬프트가 3s 이상이고 예측이 최소 1s)에 추가 된 최소 WAV 샘플 크기 (초) 매개 변수가 추가됩니다.prompt_size 추가했습니다. 트랜 링의 WAV 샘플에서 프롬프트로 사용되는 MEL 프레임의 수입니다. (기본값은 ~ 3s; 3*22050 // 256 = 258; 구성에서 264로 반올림)dur_p_use_log 추가하여 지속 시간 예측의 로그를 사용할지 여부를 손실 계산에 사용하지 않는지 제어합니다. (기본값은 이제 거짓입니다) 내 가설은 로그 기간 MSE 손실이 더 긴 일시 정지 등에 잘 작동하지 않는다는 것입니다 (로그 함수의 특성으로 인해). 따라서 우리는 손실을 계산하기 전에 로그 지속 시간에 전원을 e 합니다. 대안적인 방법은 로그 대신 Relu를 사용할 수 있습니다.transfer_ckpt_path 추가했습니다. (기본값은 없음) 없으면 모델이 처음부터 훈련됩니다. 그렇지 않으면 모델은 CKPT 경로에서로드되고 0 단계에서 훈련됩니다. 경우 ckpt_path 도 없을 경우 모델은 ckpt_path 에서로드하고 저장된 단계에서 훈련됩니다. transfer_ckpt_path CKPT와 모델 간의 레이어 크기 불일치를 처리 할 수 있습니다. export.py 및 inference.py 의 인수를 사용하여 모델을 내보내고 테스트하십시오. (Arguemnts는 자기 설명 적입니다) 

