DeepSpeed MII
v0.3.1





由DeepSpeed設計的開源Python圖書館MII介紹MII,旨在使強大的模型推斷民主化,重點是高通量,低潛伏期和成本效益。
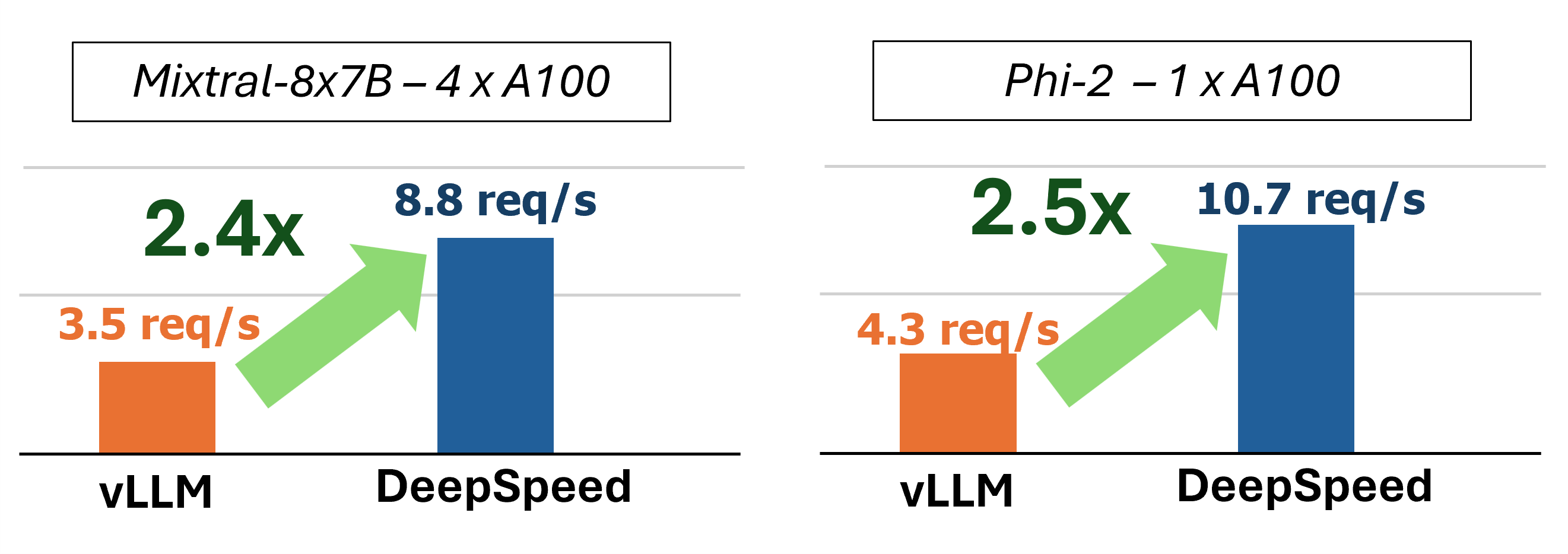
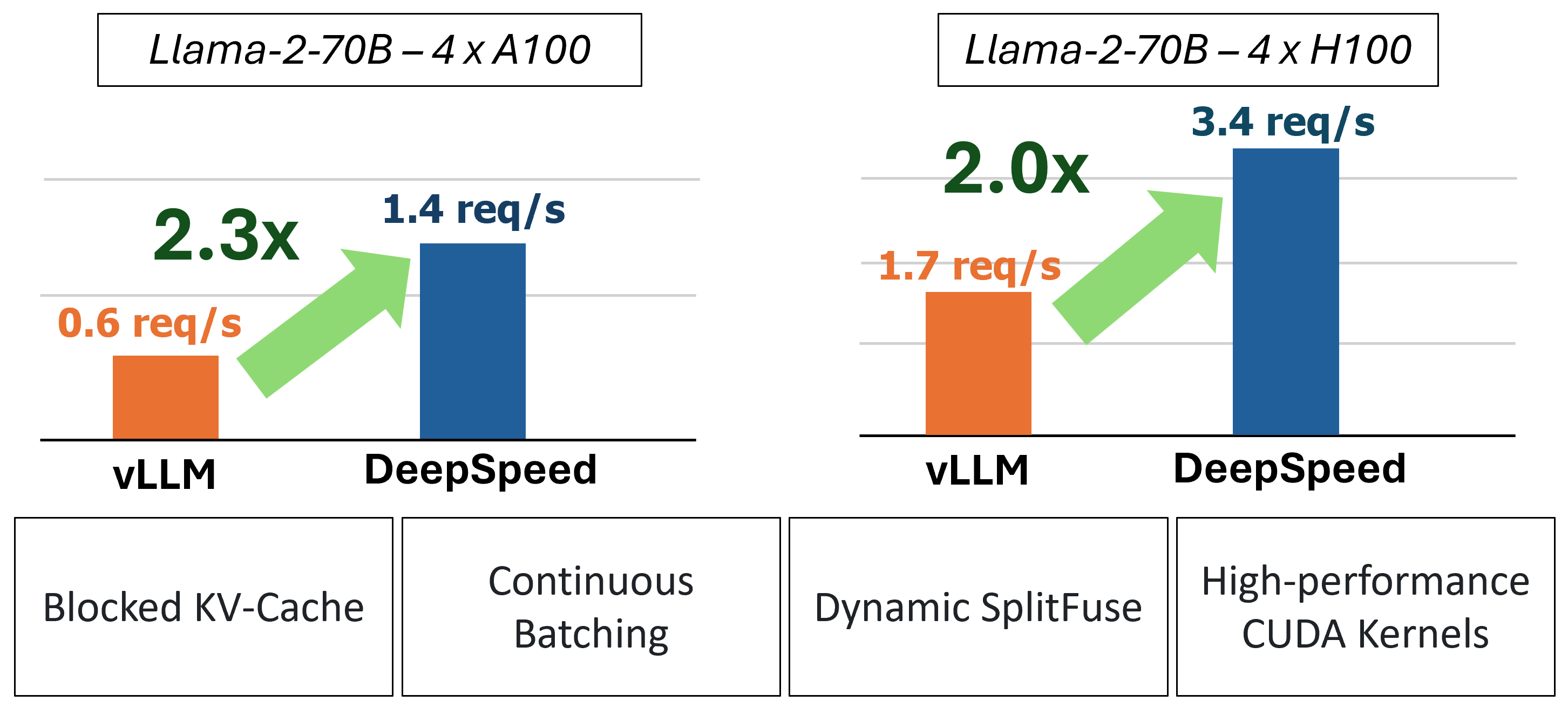
MII通過使用四種關鍵技術提供了加速的文本生成推斷:
要深入了解這些功能,請參考我們的博客,該博客還包括詳細的性能分析。
過去,MII引入了低延遲服務方案的幾個關鍵性能優化:
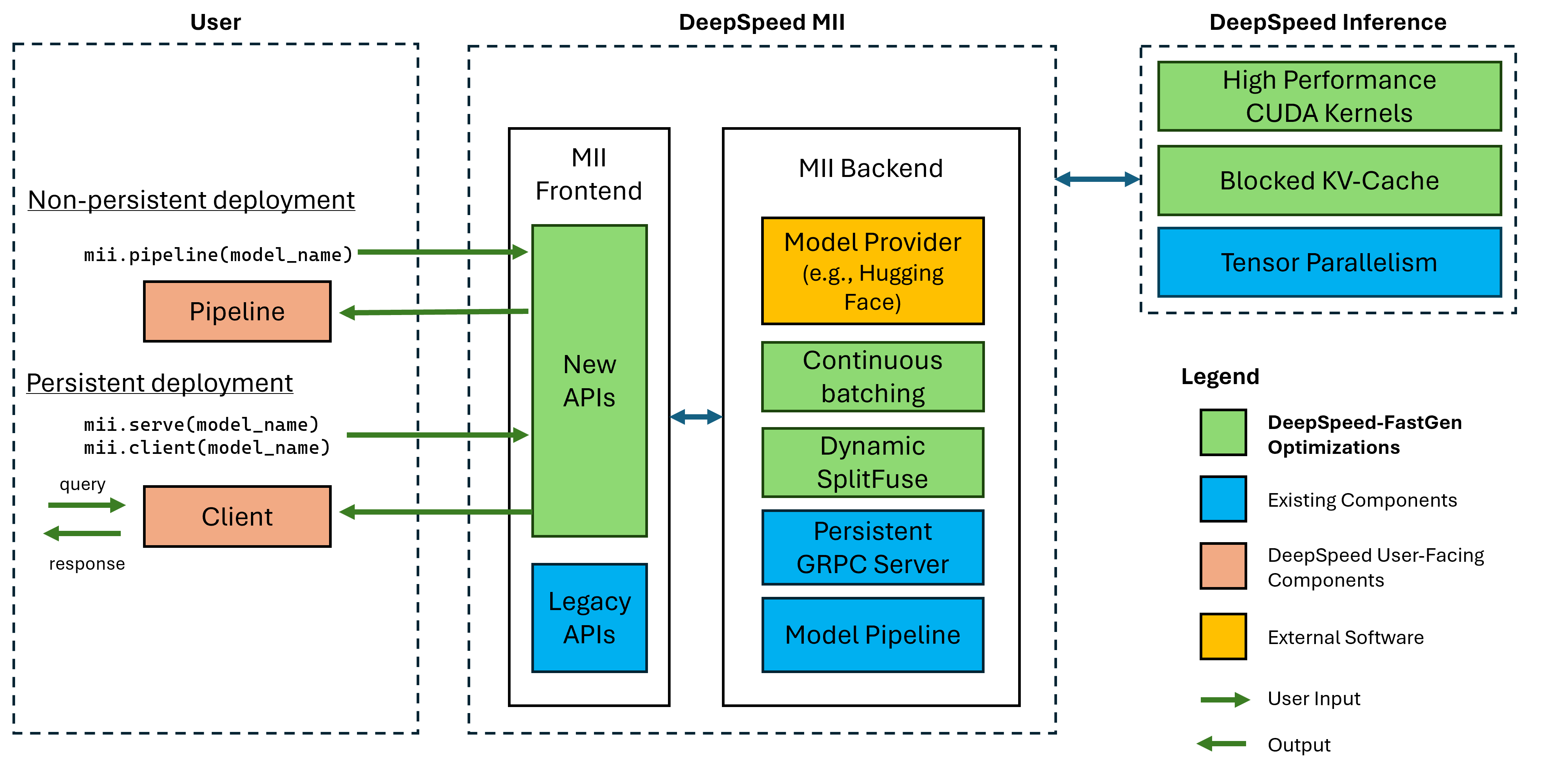
圖1:MII體系結構,顯示MII在部署之前使用DS-推導如何自動優化OSS模型。該圖中的DeepSpeed-Fastgen優化已在我們的博客文章中發表。
下層MII由深速推導提供動力。根據模型體系結構,型號大小,批處理大小和可用的硬件資源,MII會自動應用適當的系統優化集以最大程度地減少延遲和最大化吞吐量。
MII目前支持八個流行模型架構的37,000多個型號。我們計劃在短期內添加其他模型,如果您需要支持的特定模型架構,請提出問題並告訴我們。當前的所有模型都在我們的後端均採用擁抱面孔,以提供模型權重和模型相應的令牌。對於當前版本,我們支持以下模型體系結構:
| 模特家庭 | 尺寸範圍 | 〜型號計數 |
|---|---|---|
| 鶻 | 7b -180b | 600 |
| 駱駝 | 7b -65b | 57,000 |
| Llama-2 | 7b -70b | 1200 |
| Llama-3 | 8b -405b | 1,600 |
| Mistral | 7b | 23,000 |
| 混合(MOE) | 8x7b | 2,900 |
| 選擇 | 0.1b -66b | 2,200 |
| PHI-2 | 2.7b | 1,500 |
| QWEN | 7b -72b | 500 |
| qwen2 | 0.5B -72B | 3700 |
MII傳統API支持超過50,000多種不同的模型,包括Bert,Roberta,穩定擴散以及其他文本生成模型,例如Bloom,GPT-J等。有關完整列表,請參閱我們的遺產支持的模型表。
DeepSpeed-MII允許用戶在僅幾行代碼中為受支持的模型創建非持久和持久部署。
Fasest入門的方法是我們的PYPI發布DeepSpeed-MII,這意味著您可以在幾分鐘之內通過:
pip install deepspeed-mii為了易於使用和在這個空間中許多項目所需的漫長的編譯時間的大幅度減少,我們通過一個名為DeepSpeed-Kernels的新圖書館分發了預編譯的Python車輪,覆蓋了我們的大多數自定義內核。我們發現,該庫在具有Compute功能8.0+(Ampere+),CUDA 11.6+和Ubuntu 20+的NVIDIA GPU的環境中非常便宜。在大多數情況下,您甚至不需要知道此庫存在,因為它是DeepSpeed-MII的依賴性,並且將與之一起安裝。但是,如果出於任何原因需要手動編譯我們的內核,請參閱我們的高級安裝文檔。
非持久管道是嘗試DeepSpeed-MII的好方法。非滲透管道僅在您正在運行的Python腳本的過程中出現。運行非持久管道部署的完整示例僅為4行。嘗試一下!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response )返回的response是Response對象的列表。我們可以訪問有關生成的幾個詳細信息(例如, response[0].prompt_length ):
generated_text: str文本。prompt_length: int令牌數。generated_length: int生成的代幣數量。finish_reason: str停止生成的原因。 stop表示生成EOS令牌, length表示將生成達到max_new_tokens或max_length 。如果要釋放設備內存並破壞管道,請使用destroy方法:
pipe . destroy ()使用MII,利用多GPU系統來提高性能非常容易。使用deepspeed Launcher運行時,張量並行性將由--num_gpus自動控制:
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.py雖然僅需要模型名稱或路徑來站立非固定管道部署,但我們為用戶提供自定義選項:
mii.pipeline()選項:
model_name_or_path: str名稱或擁抱面模型的本地路徑。max_length: int為提示 +響應設置默認的最大令牌長度。all_rank_output: bool啟用時,所有等級返回生成的文本。默認情況下,只有等級0將返回文本。用戶還可以控制單個提示的生成特性(即,在調用pipe() )的使用以下選項:
max_length: int為及時 +響應設置每個prompt的最大令牌長度。min_new_tokens: int設置響應中生成的最小令牌數。 max_length將優先於此設置。max_new_tokens: int設置響應中生成的最大令牌數。ignore_eos: bool (默認為False )設置為True ,可以防止遇到EOS令牌時產生。top_p: float (默認為0.9 )當設置以下1.0以下時,過濾令牌,僅保留最可能的最可能的位置,即令牌概率和top_p 。top_k: int (默認為None )當None ,top-k過濾將被禁用。設置時,要保留最高概率令牌的數量。temperature: float (默認為None ),當None禁用溫度。設置時,調節令牌概率。do_sample: bool (默認為True )當True時,示例輸出logits。 False時,使用貪婪的抽樣。return_full_text: bool (默認為False ), True ,將輸入提示提示為返回的文本持續部署非常適合與長期運行和生產應用一起使用。持久模型使用輕巧的GRPC服務器,該服務器可以一次由多個客戶端查詢。運行持久模型的完整示例僅為5行。嘗試一下!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response )返回的response是Response對象的列表。我們可以訪問有關生成的幾個詳細信息(例如, response[0].prompt_length ):
generated_text: str文本。prompt_length: int令牌數。generated_length: int生成的代幣數量。finish_reason: str停止生成的原因。 stop表示生成EOS令牌, length表示將生成達到max_new_tokens或max_length 。如果我們想從其他過程中生成文本,我們也可以這樣做:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )當我們不再需要持續部署時,我們可以從任何客戶端關閉服務器:
client . terminate_server ()持續部署利用多GPU系統來提高延遲和吞吐量也很容易。模型並行性由tensor_parallel input to mii.serve控制:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )與單個GPU相比,最終的部署將使模型在2 GPU上將模型分開,以提供更快的推理和更高的吞吐量。
我們還可以通過設置多個模型複製品並利用DeepSpeed-MII提供的負載平衡來利用多GPU(和多節點)系統:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )由此產生的部署將加載2個模型複製品(每GPU一個)和2個模型實例之間的負載平衡收入請求。
模型並行性和復製品也可以合併,以利用更多GPU的系統。在下面的示例中,我們運行了2個模型複製品,每個複製品在具有4個GPU的系統上跨2 GPU:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )模型並行性和模型複製品之間的選擇最大性能取決於硬件,模型和工作負載的性質。例如,使用小型模型,用戶可能會發現模型複製品為請求提供了最低的平均延遲。同時,僅使用模型並行性時,大型模型可能會達到更大的總體吞吐量。
MII通過設置enable_restful_api=True在創建持久的MII部署時,可以輕鬆地通過RESTFUL API設置和運行模型推斷。 RESTFUL API可以在http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} 。下面提供了一個完整的示例:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ?注意:雖然沒有必要提供deployment_name (MII將為您自動化一個),但最好提供deployment_name ,以確保您可以與正確的Restful API接口。
然後,您可以使用任何HTTP客戶端將提示發送到Restful網關,例如curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment或python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)雖然僅需要模型名稱或路徑來站立持續部署,但我們為用戶提供自定義選項。
mii.serve()選項:
model_name_or_path: str (必需)名稱或擁抱面模型的本地路徑。max_length: int (默認為模型配置中的最大序列長度)設置了提示 +響應的默認最大令牌長度。deployment_name: str (默認為f"{model_name_or_path}-mii-deployment" )一個唯一的識別字符串,用於持久模型。如果提供,則應使用client = mii.client(deployment_name)檢索客戶端對象。tensor_parallel: int (默認為1 )gpu的數量,以將模型跨越。replica_num: int (默認為1 )要站起來的模型副本數量。enable_restful_api: bool (默認為False )啟用時,將啟動一個恢復的API網關進程,可以在http://{host}:{restful_api_port}/mii/{deployment_name} 。有關更多詳細信息,請參見有關RESTFUL API的部分。restful_api_port: int (默認為28080 )當enable_restful_api設置為True時,用於與Restful API接口的端口號。 mii.client()選項:
model_or_deployment_name: str模型或deployment_name的str名稱傳遞給mii.serve()用戶還可以控制單個提示的生成特性(即,在調用client.generate() )的使用以下選項:
max_length: int為及時 +響應設置每個prompt的最大令牌長度。min_new_tokens: int設置響應中生成的最小令牌數。 max_length將優先於此設置。max_new_tokens: int設置響應中生成的最大令牌數。ignore_eos: bool (默認為False )設置為True ,可以防止遇到EOS令牌時產生。top_p: float (默認為0.9 )當設置以下1.0以下時,過濾令牌,僅保留最可能的最可能的位置,即令牌概率和top_p 。top_k: int (默認為None )當None ,top-k過濾將被禁用。設置時,要保留最高概率令牌的數量。temperature: float (默認為None ),當None禁用溫度。設置時,調節令牌概率。do_sample: bool (默認為True )當True時,示例輸出logits。 False時,使用貪婪的抽樣。return_full_text: bool (默認為False ), True ,將輸入提示提示為返回的文本該項目歡迎貢獻和建議。大多數捐款要求您同意撰寫貢獻者許可協議(CLA),宣布您有權並實際上授予我們使用您的貢獻的權利。有關詳細信息,請訪問https://cla.opensource.microsoft.com。
當您提交拉動請求時,CLA機器人將自動確定您是否需要提供CLA並適當裝飾PR(例如狀態檢查,評論)。只需按照機器人提供的說明即可。您只需要使用我們的CLA在所有存儲庫中進行一次。
該項目採用了Microsoft開源的行為代碼。有關更多信息,請參見《行為守則常見問題守則》或與其他問題或評論聯繫[email protected]。
該項目可能包含用於項目,產品或服務的商標或徽標。 Microsoft商標或徽標的授權使用受到了Microsoft的商標和品牌準則的約束。在此項目的修改版本中使用Microsoft商標或徽標不得引起混亂或暗示Microsoft贊助。任何使用第三方商標或徽標都遵守這些第三方政策。


