DeepSpeed MII
v0.3.1





Apresentando o MII, uma biblioteca Python de código aberto, projetado pela DeepSpeed para democratizar a poderosa inferência do modelo, com foco em alto rendimento, baixa latência e custo-efetividade.
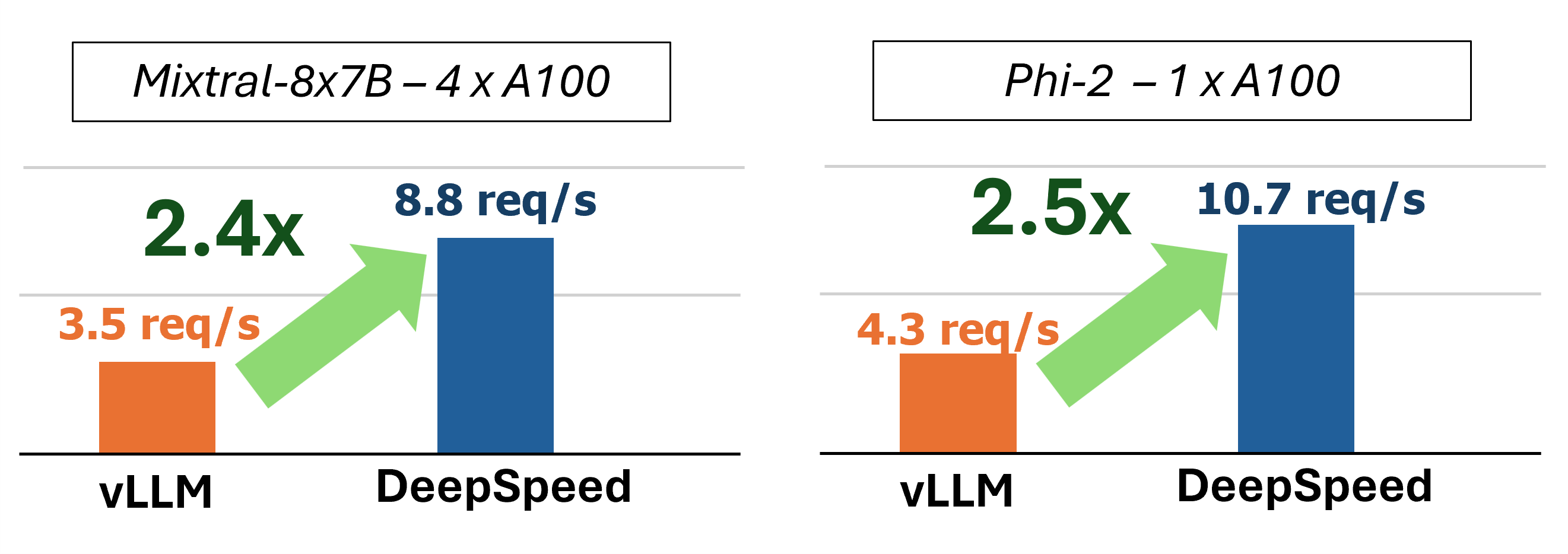
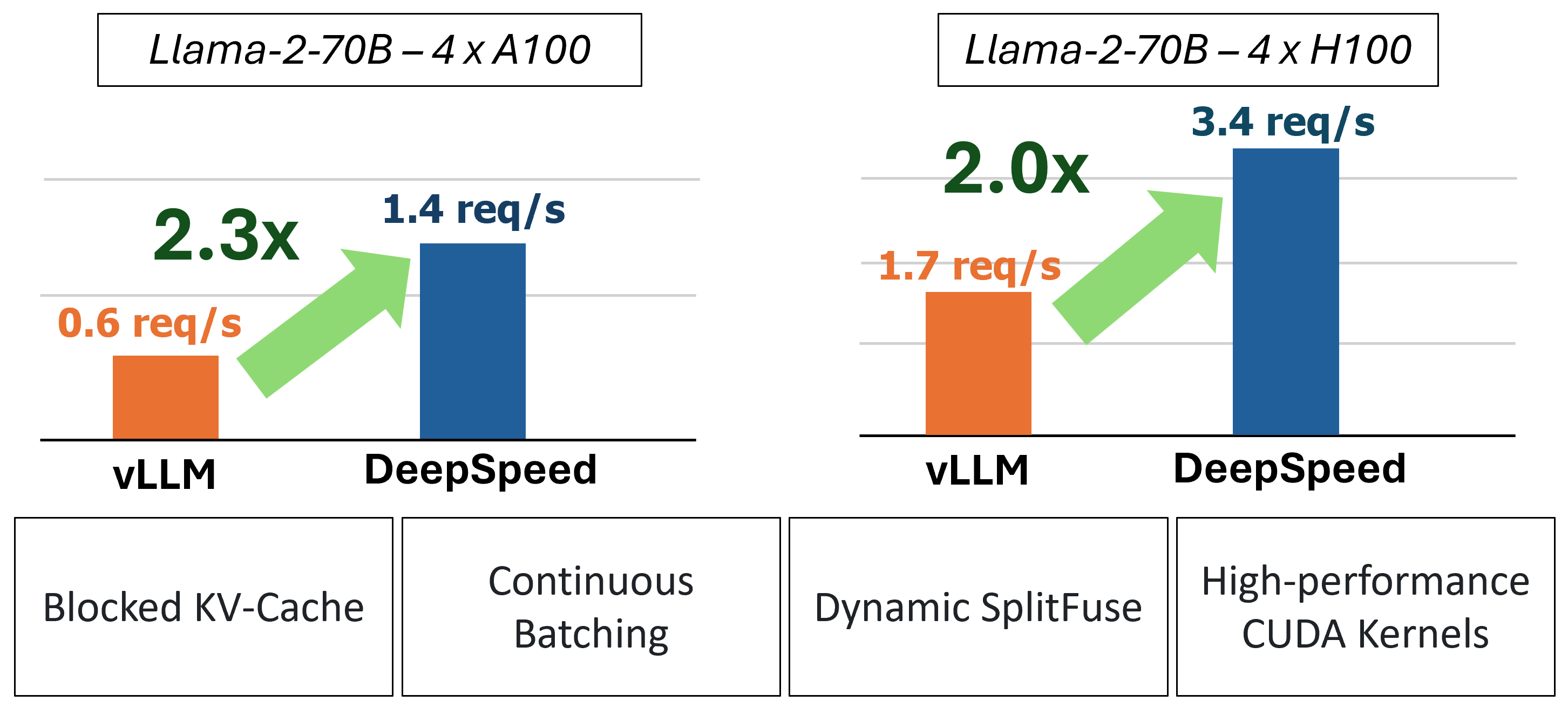
O MII fornece inferência acelerada de geração de texto através do uso de quatro tecnologias principais:
Para um mergulho mais profundo na compreensão desses recursos, consulte o nosso blog, que também inclui uma análise de desempenho detalhada.
No passado, o MII introduziu várias otimizações importantes de desempenho para cenários de porção de baixa latência:
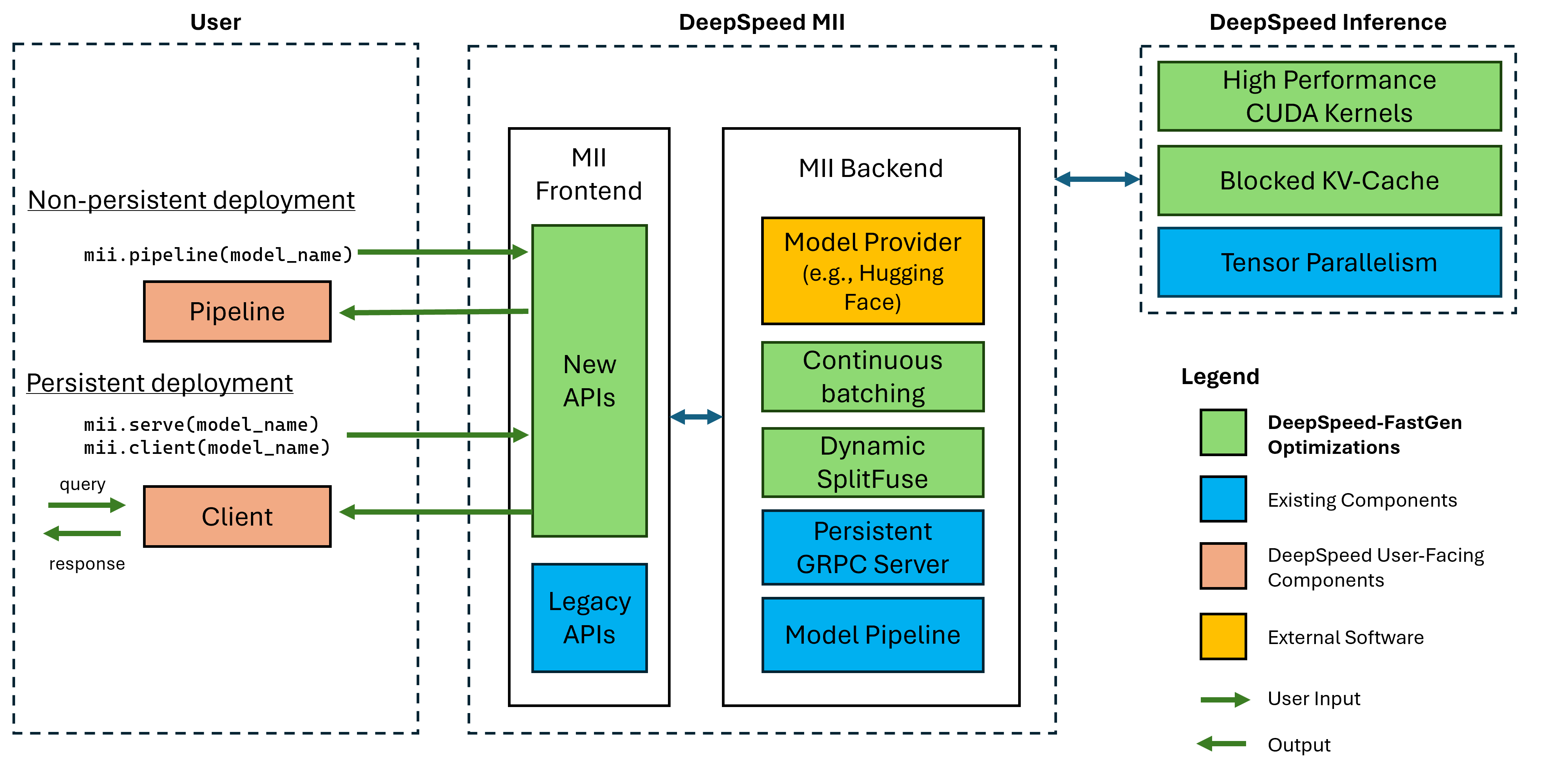
Figura 1: A arquitetura MII, mostrando como o MII otimiza automaticamente os modelos de OSS usando a inferência de DS antes de implantá-los. As otimizações DeepSpeed-Fastgen na figura foram publicadas em nossa postagem no blog.
O MII sob o alojamento é alimentado por uma inferência de velocidade profunda. Com base na arquitetura do modelo, tamanho do modelo, tamanho do lote e recursos de hardware disponíveis, o MII aplica automaticamente o conjunto apropriado de otimizações do sistema para minimizar a latência e maximizar a taxa de transferência.
Atualmente, o MII suporta mais de 37.000 modelos em oito arquiteturas populares. Planejamos adicionar modelos adicionais no curto prazo, se houver arquiteturas de modelos específicas que você deseja suportar, registre um problema e informe -nos. Todos os modelos atuais aproveitam o rosto de abraçar em nosso back -end para fornecer os pesos do modelo e o tokenizador correspondente do modelo. Para o nosso lançamento atual, apoiamos as seguintes arquiteturas de modelo:
| família modelo | faixa de tamanho | ~ Contagem de modelos |
|---|---|---|
| Falcão | 7b - 180b | 600 |
| Lhama | 7b - 65b | 57.000 |
| Lhama-2 | 7b - 70b | 1.200 |
| Lhama-3 | 8b - 405b | 1.600 |
| Mistral | 7b | 23.000 |
| Mixtral (moe) | 8x7b | 2.900 |
| OPTAR | 0,1b - 66b | 2.200 |
| Phi-2 | 2.7b | 1.500 |
| Qwen | 7b - 72b | 500 |
| Qwen2 | 0,5b - 72b | 3700 |
As APIs do MII Legacy suportam mais de 50.000 modelos diferentes, incluindo Bert, Roberta, Difusão estável e outros modelos de geração de texto como Bloom, GPT-J, etc. Para uma lista completa, consulte nossa tabela de modelos suportados por legado.
O DeepSpeed-MII permite que os usuários criem implantações não persistentes e persistentes para modelos suportados em apenas algumas linhas de código.
A maneira mais interessante de começar é com o lançamento do Pypi do DeepSpeed-MII, o que significa que você pode começar em poucos minutos por meio de:
pip install deepspeed-miiPara facilitar o uso e a redução significativa em longos tempos de compilação que muitos projetos exigem neste espaço, distribuímos uma roda de Python pré-compilada que cobre a maioria de nossos núcleos personalizados através de uma nova biblioteca chamada DeepSpeed-Kernels. Descobrimos que essa biblioteca é muito portátil em ambientes com o NVIDIA GPUS com recursos de computação 8.0+ (Ampere+), CUDA 11.6+ e Ubuntu 20+. Na maioria dos casos, você nem precisa saber que essa biblioteca existe, pois é uma dependência do DeepSpeed-MII e será instalada com ela. No entanto, se, por qualquer motivo, você precisar compilar nossos kernels manualmente, consulte nossos documentos avançados de instalação.
Um pipeline não persistente é uma ótima maneira de experimentar o DeepSpeed-MII. Os pipelines não persistentes estão apenas por toda a duração do script python que você está executando. O exemplo completo para executar uma implantação de pipeline não persistente é de apenas 4 linhas. Experimente!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) A response retornada é uma lista de objetos Response . Podemos acessar vários detalhes sobre a geração (por exemplo, response[0].prompt_length ):
generated_text: str gerado pelo modelo.prompt_length: int número de tokens no prompt original.generated_length: int número de tokens gerados.finish_reason: str Razão para parar a geração. stop indica que o token EOS foi gerado e length indica que a geração atingiu max_new_tokens ou max_length . Se você deseja liberar memória do dispositivo e destruir o pipeline, use o método destroy :
pipe . destroy () Aproveitar os sistemas multi-GPU para maior desempenho é fácil com o MII. Quando executado com o lançador deepspeed , o paralelismo do tensor é automaticamente controlado pelo sinalizador --num_gpus :
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pyEmbora apenas o nome ou o caminho do modelo seja necessário para suportar uma implantação de pipeline não persistente, oferecemos opções de personalização para nossos usuários:
mii.pipeline() Opções :
model_name_or_path: str ou caminho local para um modelo Huggingface.max_length: int define o comprimento máximo de token padrão para a resposta do prompt +.all_rank_output: bool Quando ativado, todas as classificações retornam o texto gerado. Por padrão, apenas a classificação 0 retornará o texto. Os usuários também podem controlar as características de geração para instruções individuais (ou seja, ao chamar pipe() ) com as seguintes opções:
max_length: int define o comprimento máximo do token por promotos para resposta PROMPRADA +.min_new_tokens: int define o número mínimo de tokens gerados na resposta. max_length terá precedência sobre essa configuração.max_new_tokens: int define o número máximo de tokens gerados na resposta.ignore_eos: bool (padrão para False ) A configuração para True impede a geração de terminação quando o token EOS é encontrado.top_p: float (Padrões para 0.9 ) Quando definido abaixo de 1.0 , filtrar tokens e manter apenas o mais provável, onde as probabilidades de token somam ≥ top_p .top_k: int (padrão para None ) Quando None , a filtragem superior-k é desativada. Quando definido, o número de tokens de probabilidade mais altos para manter.temperature: float (Padrões para None ) Quando None , a temperatura é desativada. Quando definido, modula as probabilidades de token.do_sample: bool (padrão para True ) Quando True , amostra de logits de saída. Quando False , use amostragem gananciosa.return_full_text: bool (padrão para False ) quando True , prenda o prompt de entrada para o texto retornado Uma implantação persistente é ideal para uso com aplicativos de longa duração e produção. O modelo persistente usa um servidor GRPC leve que pode ser consultado por vários clientes de uma só vez. O exemplo completo para executar um modelo persistente são apenas 5 linhas. Experimente!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) A response retornada é uma lista de objetos Response . Podemos acessar vários detalhes sobre a geração (por exemplo, response[0].prompt_length ):
generated_text: str gerado pelo modelo.prompt_length: int número de tokens no prompt original.generated_length: int número de tokens gerados.finish_reason: str Razão para parar a geração. stop indica que o token EOS foi gerado e length indica que a geração atingiu max_new_tokens ou max_length .Se queremos gerar texto de outros processos, também podemos fazer isso:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )Quando não precisamos mais de uma implantação persistente, podemos desligar o servidor de qualquer cliente:
client . terminate_server () Aproveitar os sistemas multi-GPU para melhor latência e taxa de transferência também é fácil com as implantações persistentes. O paralelismo do modelo é controlado pela entrada tensor_parallel em mii.serve :
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )A implantação resultante dividirá o modelo em 2 GPUs para fornecer inferência mais rápida e maior taxa de transferência do que uma única GPU.
Também podemos aproveitar os sistemas multi-GPU (e multi-nó), configurando várias réplicas de modelo e aproveitando o balanceamento de carga que o DeepSpeed-MII fornece:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )A implantação resultante carregará 2 réplicas de modelos (uma por GPU) e solicitações recebidas pelo equilíbrio de carga entre as duas instâncias do modelo.
O paralelismo e as réplicas do modelo também podem ser combinados para aproveitar os sistemas com muito mais GPUs. No exemplo abaixo, executamos 2 réplicas de modelo, cada uma dividida em 2 GPUs em um sistema com 4 GPUs:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )A escolha entre o paralelismo do modelo e as réplicas de modelo para o máximo desempenho dependerá da natureza do hardware, modelo e carga de trabalho. Por exemplo, com os pequenos modelos, os usuários podem achar que as réplicas de modelo fornecem a menor latência média para solicitações. Enquanto isso, modelos grandes podem atingir maior taxa de transferência geral ao usar apenas o paralelismo do modelo.
O MII facilita a configuração e a execução da inferência do modelo por meio de APIs RESTful, Configurando enable_restful_api=True ao criar uma implantação persistente do MII. A API RESTful pode receber solicitações em http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} . Um exemplo completo é fornecido abaixo:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ? NOTA: Embora seja necessário fornecer um deployment_name (MII (MII será autogerro para você), é uma boa prática fornecer uma deployment_name para que você possa garantir que está interagindo com a API RESTful correta.
Você pode enviar prompts para o gateway RESTful com qualquer cliente HTTP, como curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment ou python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)Embora apenas o nome ou o caminho do modelo seja necessário para resistir a uma implantação persistente, oferecemos opções de personalização para nossos usuários.
mii.serve() Opções :
model_name_or_path: str (requerido) Nome ou caminho local para um modelo Huggingface.max_length: int (padrão para o comprimento máximo da sequência na configuração do modelo) define o comprimento máximo padrão do token para a resposta do prompt +.deployment_name: str (padrão para f"{model_name_or_path}-mii-deployment" ) Uma string de identificação exclusiva para o modelo persistente. Se fornecido, os objetos do cliente devem ser recuperados com client = mii.client(deployment_name) .tensor_parallel: int (padrão para 1 ) Número de GPUs para dividir o modelo.replica_num: int (padrão para 1 ) o número de réplicas de modelo para se levantar.enable_restful_api: bool (padrão para False ) Quando ativado, é lançado um processo de gateway API RESTful que pode ser consultado em http://{host}:{restful_api_port}/mii/{deployment_name} . Veja a seção sobre APIs RESTful para obter mais detalhes.restful_api_port: int (padrão para 28080 ) O número da porta usado para interagir com a API RESTful quando enable_restful_api é definido como True . Opções mii.client() :
model_or_deployment_name: str Nome do modelo ou deployment_name passado para mii.serve() Os usuários também podem controlar as características de geração para prompts individuais (ou seja, ao ligar para client.generate() ) com as seguintes opções:
max_length: int define o comprimento máximo do token por promotos para resposta PROMPRADA +.min_new_tokens: int define o número mínimo de tokens gerados na resposta. max_length terá precedência sobre essa configuração.max_new_tokens: int define o número máximo de tokens gerados na resposta.ignore_eos: bool (padrão para False ) A configuração para True impede a geração de terminação quando o token EOS é encontrado.top_p: float (Padrões para 0.9 ) Quando definido abaixo de 1.0 , filtrar tokens e manter apenas o mais provável, onde as probabilidades de token somam ≥ top_p .top_k: int (padrão para None ) Quando None , a filtragem superior-k é desativada. Quando definido, o número de tokens de probabilidade mais altos para manter.temperature: float (Padrões para None ) Quando None , a temperatura é desativada. Quando definido, modula as probabilidades de token.do_sample: bool (padrão para True ) Quando True , amostra de logits de saída. Quando False , use amostragem gananciosa.return_full_text: bool (padrão para False ) quando True , prenda o prompt de entrada para o texto retornadoEste projeto recebe contribuições e sugestões. A maioria das contribuições exige que você concorde com um Contrato de Licença de Colaborador (CLA) declarando que você tem o direito e, na verdade, concede -nos os direitos de usar sua contribuição. Para detalhes, visite https://cla.opensource.microsoft.com.
Quando você envia uma solicitação de tração, um BOT do CLA determina automaticamente se você precisa fornecer um CLA e decorar o PR adequadamente (por exemplo, verificação de status, comentar). Simplesmente siga as instruções fornecidas pelo bot. Você só precisará fazer isso uma vez em todos os repositórios usando nosso CLA.
Este projeto adotou o Código de Conduta Open Microsoft. Para obter mais informações, consulte o Código de Conduta Perguntas frequentes ou entre em contato com [email protected] com quaisquer perguntas ou comentários adicionais.
Este projeto pode conter marcas comerciais ou logotipos para projetos, produtos ou serviços. O uso autorizado de marcas comerciais ou logotipos da Microsoft está sujeito e deve seguir as diretrizes de marca registrada e marca da Microsoft. O uso de marcas comerciais da Microsoft ou logotipos em versões modificadas deste projeto não deve causar confusão ou implicar o patrocínio da Microsoft. Qualquer uso de marcas comerciais ou logotipos de terceiros estão sujeitas às políticas de terceiros.


