DeepSpeed MII
v0.3.1





DeepSpeed가 설계 한 오픈 소스 파이썬 라이브러리 인 MII를 소개하여 강력한 모델 추론을 민주화하기 위해 높은 처리량, 낮은 대기 시간 및 비용 효율성에 중점을 둡니다.
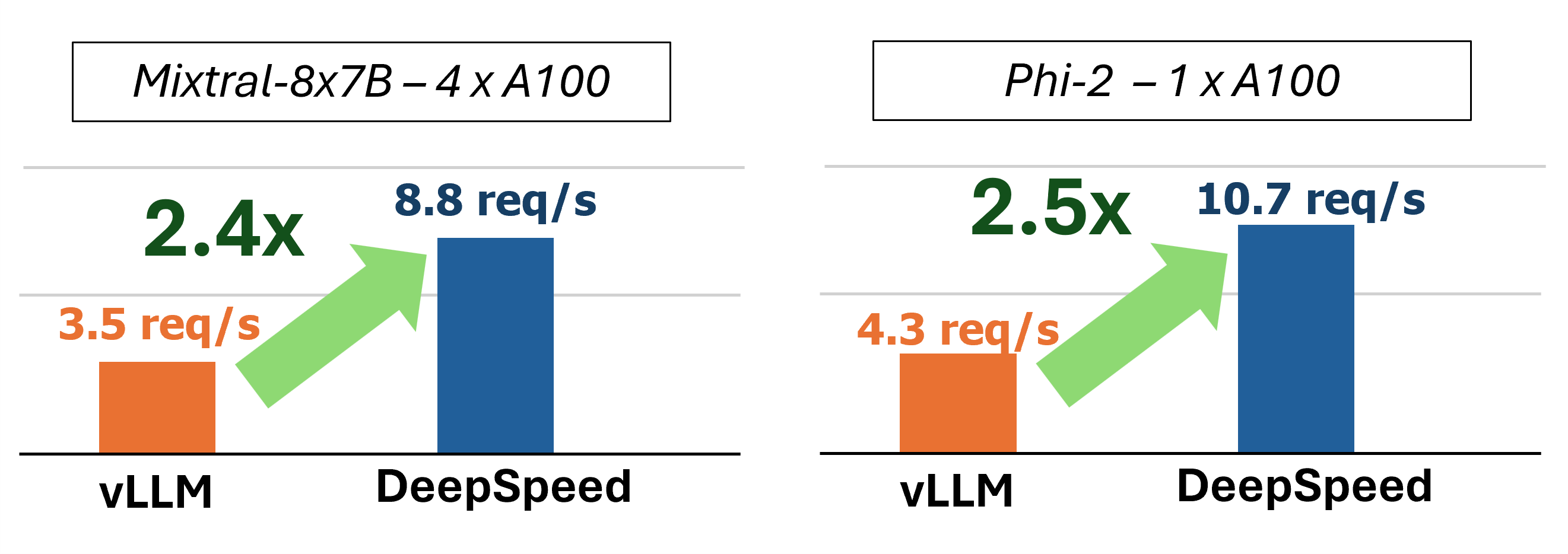
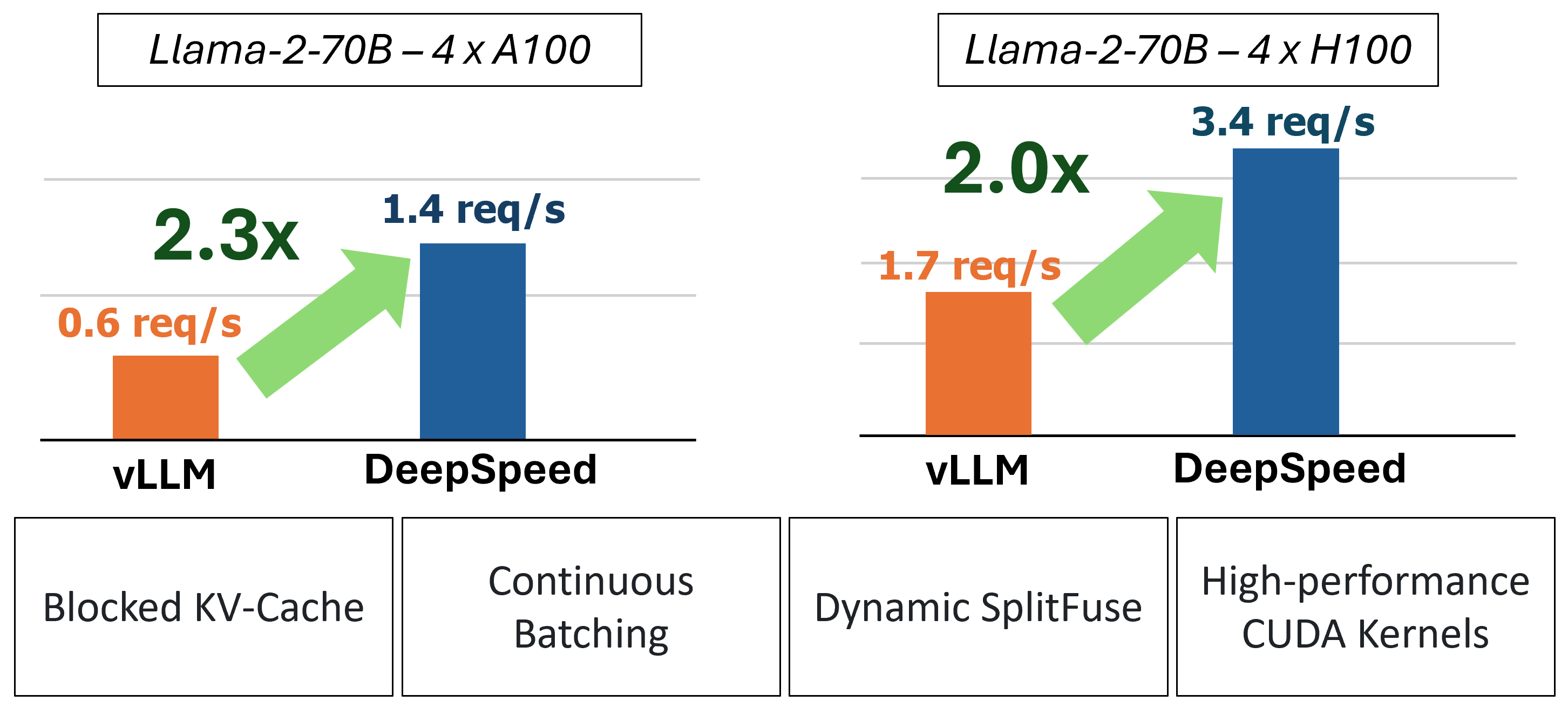
MII는 4 가지 주요 기술을 사용하여 가속화 된 텍스트 생성 추론을 제공합니다.
이러한 기능을 이해하기위한 더 깊이 다이빙하려면 자세한 성능 분석도 포함 된 블로그를 참조하십시오.
과거에 MII는 저도 서비스 시나리오를위한 몇 가지 주요 성능 최적화를 도입했습니다.
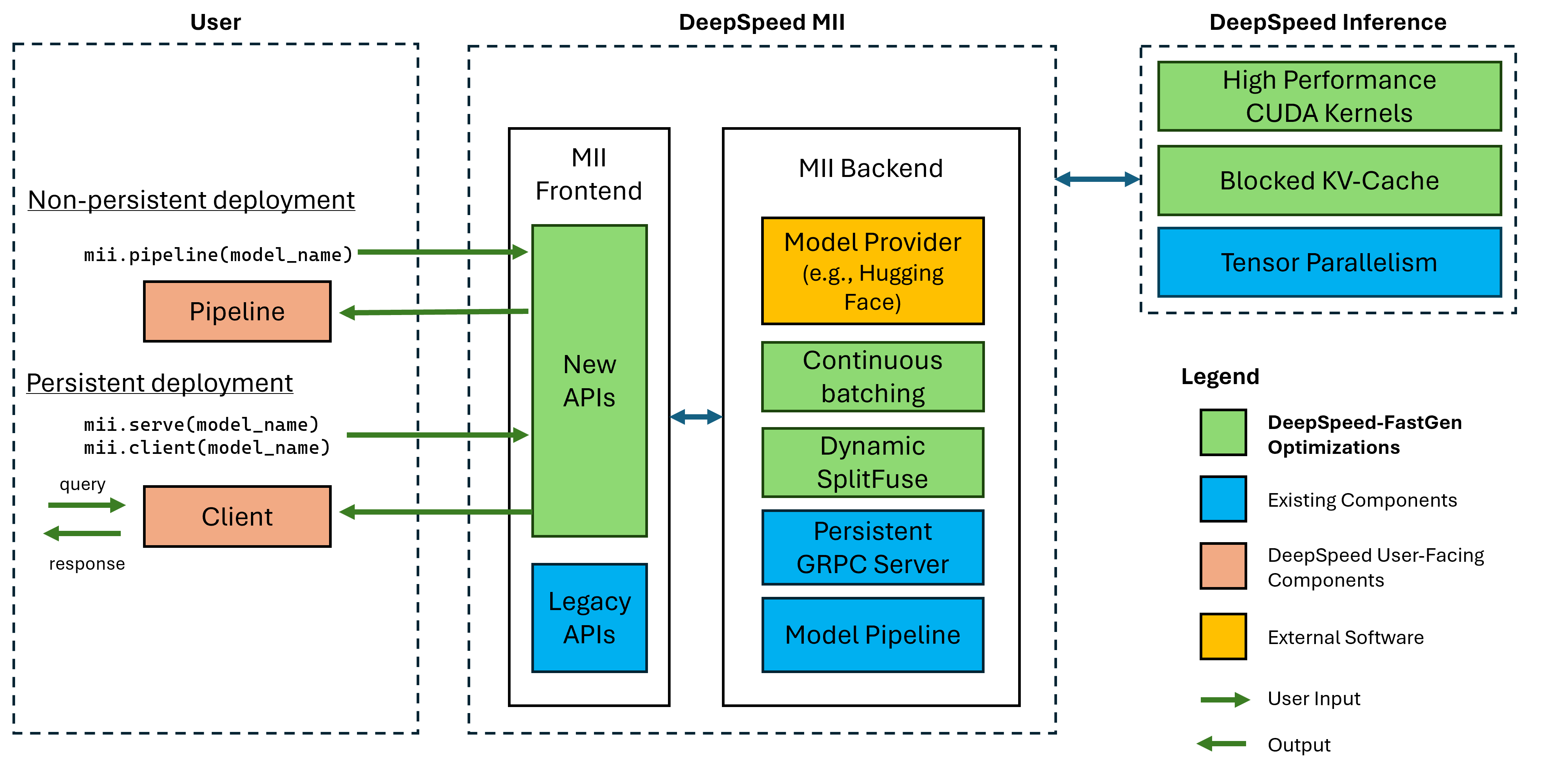
그림 1 : MII 아키텍처, MII가 배포하기 전에 DS- 관절을 사용하여 OSS 모델을 자동으로 최적화하는 방법을 보여줍니다. 그림의 DeepSpeed-FastGen 최적화가 블로그 게시물에 게시되었습니다.
하부 MII는 깊은 속도를 기준으로 구동됩니다. Mii는 모델 아키텍처, 모델 크기, 배치 크기 및 사용 가능한 하드웨어 리소스를 기반으로 적절한 시스템 최적화 세트를 자동으로 적용하여 대기 시간을 최소화하고 처리량을 최대화합니다.
MII는 현재 8 개의 인기있는 모델 아키텍처에서 37,000 개가 넘는 모델을 지원합니다. 우리는 단기적으로 추가 모델을 추가 할 계획입니다. 지원하려는 특정 모델 아키텍처가있는 경우 문제를 제기하고 알려주십시오. 모든 현재 모델은 백엔드에서 포옹 얼굴을 활용하여 모델 가중치와 모델의 해당 토큰 화제를 모두 제공합니다. 현재 릴리스의 경우 다음 모델 아키텍처를 지원합니다.
| 모델 패밀리 | 크기 범위 | ~ 모델 수 |
|---|---|---|
| 매 | 7B -180B | 600 |
| 야마 | 7B -65B | 57,000 |
| llama-2 | 7B -70B | 1,200 |
| llama-3 | 8B -405B | 1,600 |
| 미스트랄 | 7b | 23,000 |
| 믹스 트랄 (Moe) | 8x7b | 2,900 |
| 고르다 | 0.1B -66B | 2,200 |
| PHI-2 | 2.7b | 1,500 |
| Qwen | 7B -72B | 500 |
| Qwen2 | 0.5B -72B | 3700 |
MII 레거시 API는 Bert, Roberta, 안정적인 확산 및 Bloom, GPT-J 등과 같은 기타 텍스트 생성 모델을 포함한 50,000 개가 넘는 모델을 지원합니다. 전체 목록은 레거시 지원 모델 테이블을 참조하십시오.
DeepSpeed-Mii를 사용하면 사용자가 몇 줄의 코드로 지원되는 모델에 대한 비가 강하고 지속적인 배포를 만들 수 있습니다.
시작하는 가장 Fasest 방법은 DeepSpeed-Mii의 PYPI 릴리스를 통해 다음을 통해 몇 분 안에 시작할 수 있습니다.
pip install deepspeed-mii이 공간에서 많은 프로젝트가 요구하는 긴 컴파일 시간을 쉽게 감소시키기 쉽고 긴 컴파일 시간이 크게 줄어들려면 DeepSpeed-Kernels라는 새로운 라이브러리를 통해 대부분의 사용자 정의 커널을 덮는 사전 컴파일 된 Python 휠을 배포합니다. 우리는이 라이브러리가 Compute 기능 8.0+ (Ampere+), Cuda 11.6+ 및 Ubuntu 20+를 갖춘 NVIDIA GPU가있는 환경에서 매우 휴대 성이라는 것을 발견했습니다. 대부분의 경우이 라이브러리가 DeepSpeed-Mii의 종속성이므로 설치 되므로이 라이브러리가 존재한다는 것을 알 필요조차 없습니다. 그러나 어떤 이유로 든 커널을 수동으로 컴파일 해야하는 경우 고급 설치 문서를 참조하십시오.
비기능 파이프 라인은 DeepSpeed-Mii를 시도하는 좋은 방법입니다. 비기능 파이프 라인은 실행중인 파이썬 스크립트의 지속 시간에만 해당됩니다. 비기능 파이프 라인 배포를 실행하기위한 전체 예는 4 줄에 불과합니다. 시도해보세요!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) 반환 된 response Response 개체 목록입니다. 생성에 대한 몇 가지 세부 사항에 액세스 할 수 있습니다 (예 : response[0].prompt_length ) :
generated_text: str 텍스트.prompt_length: int 토큰 수.generated_length: int 생성 된 토큰 수.finish_reason: str 이유. stop 는 EOS 토큰이 생성되었고 length 생성이 max_new_tokens 또는 max_length 에 도달했음을 나타냅니다. 장치 메모리를 자유롭게하고 파이프 라인을 파괴하려면 destroy 방법을 사용하십시오.
pipe . destroy () MII에서는 성능을 향상시키기 위해 멀티 GPU 시스템을 활용하는 것이 쉽습니다. deepspeed Launcher와 함께 실행되면 Tensor 병렬 처리는 --num_gpus 플래그에 의해 자동으로 제어됩니다.
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.py비 연개 파이프 라인 배포를 견딜 수있는 모델 이름이나 경로 만 필요하지만 사용자에게 사용자 정의 옵션을 제공합니다.
mii.pipeline() 옵션 :
model_name_or_path: str 이름 또는 포옹 페이스 모델로의 로컬 경로.max_length: int 프롬프트 + 응답의 기본 최대 토큰 길이를 설정합니다.all_rank_output: bool 활성화하면 모든 순위가 생성 된 텍스트를 반환합니다. 기본적으로 Rank 0 만 텍스트를 반환합니다. 사용자는 또한 다음 옵션으로 개별 프롬프트 (즉, pipe() )를 호출 할 때)의 생성 특성을 제어 할 수 있습니다.
max_length: int 프롬프트 + 응답을 위해 프롬프트 당 최대 토큰 길이를 설정합니다.min_new_tokens: int 응답에서 생성 된 최소 토큰 수를 설정합니다. max_length 이 설정보다 우선합니다.max_new_tokens: int 응답에서 생성 된 최대 토큰 수를 설정합니다.ignore_eos: bool ( True 에서 False ) 설정은 EOS 토큰이 발생할 때 생성이 끝나는 것을 방지합니다.top_p: float (기본값 0.9 ) 1.0 미만으로 설정하면 토큰을 필터링하고 가장 가능성이 높은 곳에서만 Token 확률이 ≥ top_p 에 합산됩니다.top_k: int (기본값으로 None ) None 때 Top-K 필터링이 비활성화됩니다. 설정하면 유지할 최고 확률 토큰의 수입니다.temperature: float ( None 으로) None 온도는 비활성화되면 비활성화됩니다. 설정하면 토큰 확률을 조절합니다.do_sample: bool (true to True ) True 일 때 샘플 출력 로짓. False 경우 욕심 많은 샘플링을 사용하십시오.return_full_text: bool (defaults to False ) True 일 때 입력 프롬프트를 반환 된 텍스트에 선출합니다. 지속적인 배포는 장기 실행 및 생산 응용 프로그램과 함께 사용하기에 이상적입니다. 영구 모델은 여러 클라이언트가 한 번에 쿼리 할 수있는 경량 GRPC 서버를 사용합니다. 영구 모델을 실행하기위한 전체 예는 5 줄에 불과합니다. 시도해보세요!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) 반환 된 response Response 개체 목록입니다. 생성에 대한 몇 가지 세부 사항에 액세스 할 수 있습니다 (예 : response[0].prompt_length ) :
generated_text: str 텍스트.prompt_length: int 토큰 수.generated_length: int 생성 된 토큰 수.finish_reason: str 이유. stop EOS 토큰이 생성되었고 length 생성이 max_new_tokens 또는 max_length 에 도달했음을 나타냅니다.다른 프로세스에서 텍스트를 생성하려면 다음을 수행 할 수 있습니다.
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )더 이상 지속적인 배포가 필요하지 않으면 모든 클라이언트에서 서버를 종료 할 수 있습니다.
client . terminate_server () 더 나은 대기 시간과 처리량을 위해 멀티 GPU 시스템을 활용하는 것도 지속적으로 배포되면 쉽습니다. 모델 병렬 처리는 tensor_parallel 입력에 의해 mii.serve 에 의해 제어됩니다.
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )결과 배포는 2 GPU에 걸쳐 모델을 분할하여 단일 GPU보다 더 빠른 추론과 더 높은 처리량을 제공합니다.
또한 여러 모델 복제품을 설정하고 DeepSpeed-MII가 제공하는로드 밸런싱을 활용하여 멀티 GPU (및 다중 노드) 시스템을 활용할 수 있습니다.
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )결과 배포는 2 개의 모델 복제품 (GPU 당 1 개)과 2 개의 모델 인스턴스간에로드 균형을 잡는 요청을로드합니다.
모델 병렬 처리 및 복제본은 또한 더 많은 GPU를 가진 시스템을 활용하기 위해 결합 할 수 있습니다. 아래의 예에서, 우리는 2 개의 모델 복제품을 실행하며, 각각은 4 개의 gpus가있는 시스템에서 2 개의 GPU를 가로 질러 분할됩니다.
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )최대 성능을위한 모델 병렬 처리와 모델 복제품 중에서 선택은 하드웨어, 모델 및 워크로드의 특성에 따라 다릅니다. 예를 들어, 소규모 모델에서는 사용자가 모델 복제본이 요청에 대한 가장 낮은 평균 대기 시간을 제공 할 수 있습니다. 한편, 대형 모델은 모델 병렬 처리 만 사용할 때 전체 처리량을 더 많이 달성 할 수 있습니다.
MII를 사용하면 영구적 인 MII 배포를 생성 할 때 enable_restful_api=True 설정하여 RESTFUL API를 통해 모델 추론을 쉽게 설정하고 실행할 수 있습니다. RESTFUL API는 http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} 에서 요청을받을 수 있습니다. 아래의 전체 예는 다음과 같습니다.
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ? 참고 : deployment_name 제공하는 것이 필요하지는 않지만 (MII는 귀하를 위해 자율적으로 자율적으로 생성됩니다) deployment_name 제공하는 것이 좋습니다.
그런 다음 curl 과 같은 HTTP 클라이언트와 함께 RESTFul Gateway에 프롬프트를 보낼 수 있습니다.
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment 또는 python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)지속적인 배포를 위해 모델 이름이나 경로 만 필요하지만 사용자에게 사용자 정의 옵션을 제공합니다.
mii.serve() 옵션 :
model_name_or_path: str (필수) 이름 또는 포옹 페이스 모델로의 로컬 경로.max_length: int (모델 구성에서 기본값에서 최대 시퀀스 길이) 프롬프트 + 응답의 기본 최대 토큰 길이를 설정합니다.deployment_name: str ( f"{model_name_or_path}-mii-deployment" )) 영구 모델의 고유 한 식별 문자열입니다. 제공된 경우 client = mii.client(deployment_name) 로 클라이언트 객체를 검색해야합니다.tensor_parallel: int ( 1 ) GPU 수 (기본값) GPU 수를 분할합니다.replica_num: int (1에서 1 ).enable_restful_api: bool (defaults to False )을 활성화하면 http://{host}:{restful_api_port}/mii/{deployment_name} 에서 쿼리 할 수있는 편안한 API 게이트웨이 프로세스가 시작됩니다. 자세한 내용은 Restful API의 섹션을 참조하십시오.restful_api_port: int (기본값은 28080 ) enable_restful_api True 로 설정된 경우 RESTFUL API와 인터페이스하는 데 사용되는 포트 번호입니다. mii.client() 옵션 :
model_or_deployment_name: str mii.serve() 에 전달 된 모델 또는 deployment_name 의 str 이름 사용자는 또한 다음 옵션으로 개별 프롬프트 (즉, client.generate() )를 호출 할 때)의 생성 특성을 제어 할 수 있습니다.
max_length: int 프롬프트 + 응답을 위해 프롬프트 당 최대 토큰 길이를 설정합니다.min_new_tokens: int 응답에서 생성 된 최소 토큰 수를 설정합니다. max_length 이 설정보다 우선합니다.max_new_tokens: int 응답에서 생성 된 최대 토큰 수를 설정합니다.ignore_eos: bool ( True 에서 False ) 설정은 EOS 토큰이 발생할 때 생성이 끝나는 것을 방지합니다.top_p: float (기본값 0.9 ) 1.0 미만으로 설정하면 토큰을 필터링하고 가장 가능성이 높은 곳에서만 Token 확률이 ≥ top_p 에 합산됩니다.top_k: int (기본값으로 None ) None 때 Top-K 필터링이 비활성화됩니다. 설정하면 유지할 최고 확률 토큰의 수입니다.temperature: float ( None 으로) None 온도는 비활성화되면 비활성화됩니다. 설정하면 토큰 확률을 조절합니다.do_sample: bool (true to True ) True 일 때 샘플 출력 로짓. False 경우 욕심 많은 샘플링을 사용하십시오.return_full_text: bool (defaults to False ) True 일 때 입력 프롬프트를 반환 된 텍스트에 선출합니다.이 프로젝트는 기여와 제안을 환영합니다. 대부분의 기부금은 귀하가 귀하가 귀하의 기부금을 사용할 권리를 부여 할 권리가 있다고 선언하는 기고자 라이센스 계약 (CLA)에 동의해야합니다. 자세한 내용은 https://cla.opensource.microsoft.com을 방문하십시오.
풀 요청을 제출할 때 CLA 봇은 CLA를 제공하고 PR을 적절하게 장식 해야하는지 자동으로 결정합니다 (예 : 상태 점검, 댓글). 봇이 제공 한 지침을 따르십시오. CLA를 사용하여 모든 저장소에서 한 번만이 작업을 수행하면됩니다.
이 프로젝트는 Microsoft 오픈 소스 행동 강령을 채택했습니다. 자세한 내용은 추가 질문이나 의견이 있으면 행동 강령 FAQ 또는 [email protected]에 문의하십시오.
이 프로젝트에는 프로젝트, 제품 또는 서비스에 대한 상표 또는 로고가 포함될 수 있습니다. Microsoft 상표 또는 로고의 승인 된 사용에는 Microsoft의 상표 및 브랜드 지침이 적용되며 따라야합니다. 이 프로젝트의 수정 된 버전에서 Microsoft 상표 또는 로고를 사용한다고해서 혼란을 일으키거나 Microsoft 후원을 암시해서는 안됩니다. 타사 상표 또는 로고를 사용하면 타사 정책이 적용됩니다.


