DeepSpeed MII
v0.3.1





Présentation de Mii, une bibliothèque Python open source conçue par Deeppeed pour démocratiser l'inférence du modèle puissant en mettant l'accent sur le haut débit, la faible latence et la rentabilité.
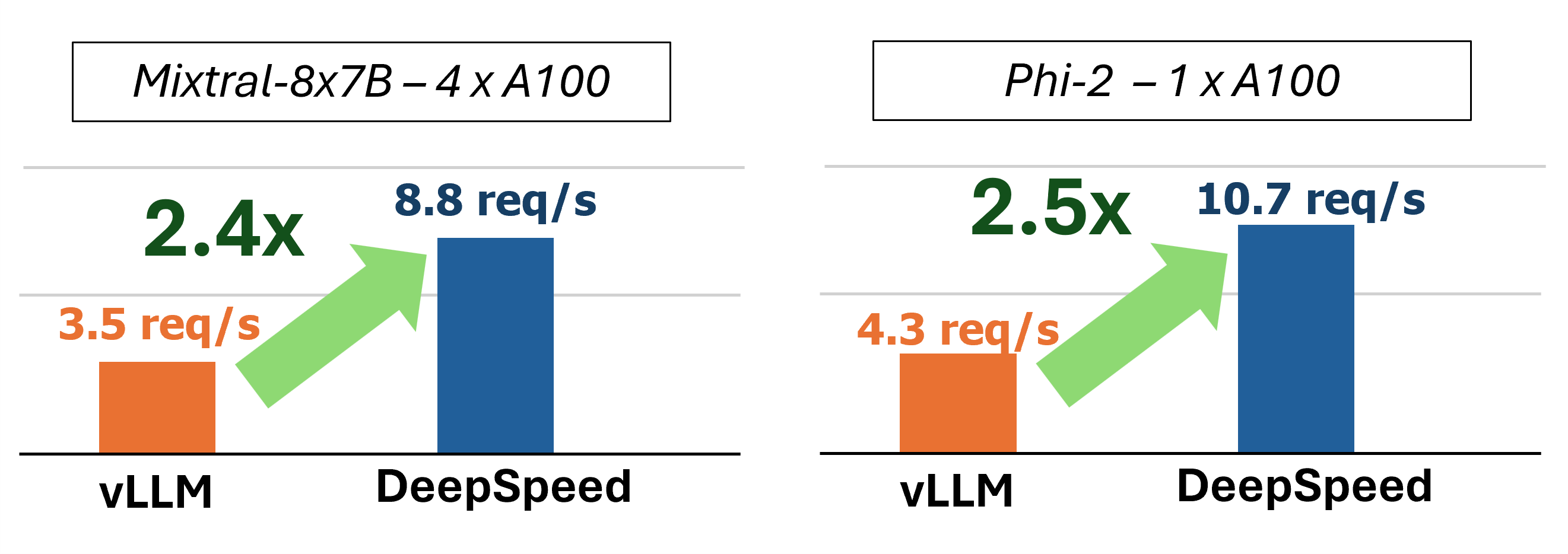
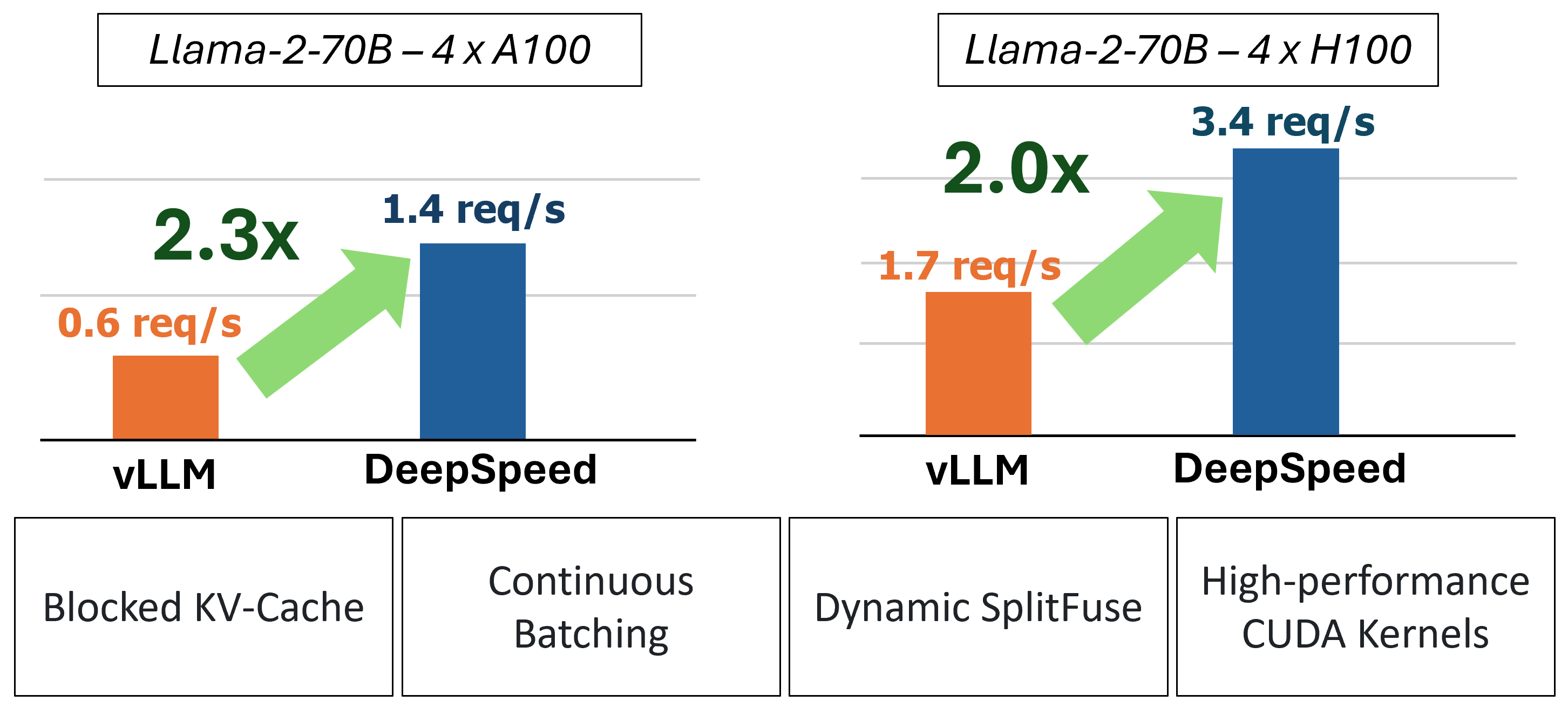
MII fournit une inférence de génération de texte accélérée grâce à l'utilisation de quatre technologies clés:
Pour une plongée plus profonde pour comprendre ces fonctionnalités, veuillez vous référer à notre blog qui comprend également une analyse détaillée des performances.
Dans le passé, MII a introduit plusieurs optimisations de performances clés pour les scénarios de service à faible latence:
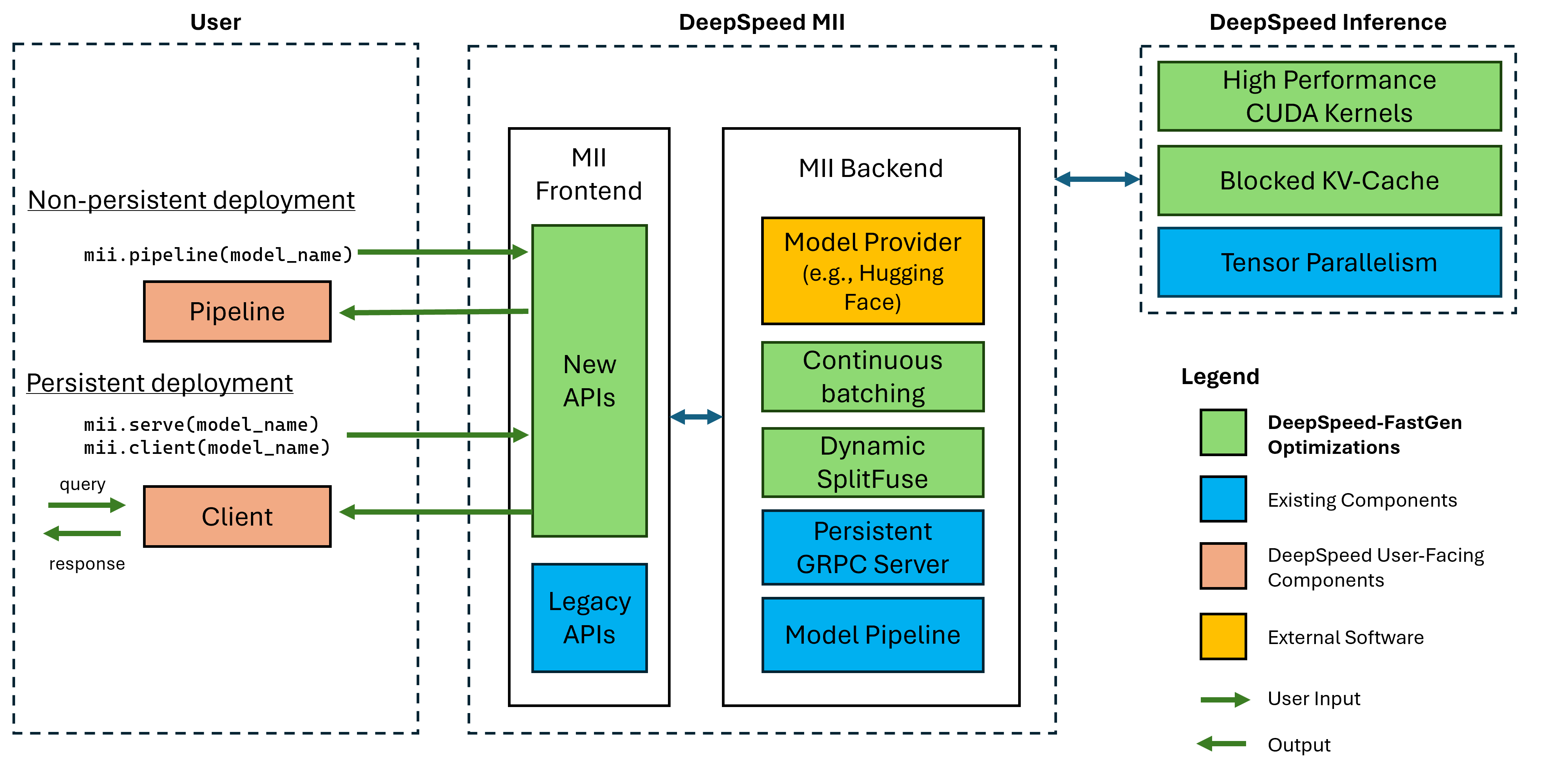
Figure 1: Architecture MII, montrant comment MII optimise automatiquement les modèles OSS en utilisant l'inférence DS avant de les déployer. Les optimisations Deeppeed-Fastgen dans la figure ont été publiées dans notre article de blog.
Le MII sous le capuchon est alimenté par une inférence profonde. Sur la base de l'architecture du modèle, de la taille du modèle, de la taille du lot et des ressources matérielles disponibles, MII applique automatiquement l'ensemble approprié des optimisations du système pour minimiser la latence et maximiser le débit.
MII prend actuellement en charge plus de 37 000 modèles dans huit architectures de modèles populaires. Nous prévoyons d'ajouter des modèles supplémentaires à court terme, s'il existe des architectures de modèles spécifiques que vous souhaitez prendre en charge, veuillez déposer un problème et le faire savoir. Tous les modèles actuels tirent parti de la face étreinte dans notre backend pour fournir à la fois les poids du modèle et le tokenizer correspondant du modèle. Pour notre version actuelle, nous prenons en charge les architectures de modèle suivantes:
| famille de modèles | plage de taille | ~ Count de modèle |
|---|---|---|
| Faucon | 7b - 180b | 600 |
| Lama | 7b - 65b | 57 000 |
| Lama-2 | 7b - 70b | 1 200 |
| Lama-3 | 8b - 405b | 1 600 |
| Mistral | 7b | 23 000 |
| Mixtral (MOE) | 8x7b | 2 900 |
| OPTER | 0.1b - 66b | 2 200 |
| Phi-2 | 2.7b | 1 500 |
| Qwen | 7b - 72b | 500 |
| Qwen2 | 0,5b - 72b | 3700 |
Les API MII Legacy prennent en charge plus de 50 000 modèles différents, notamment Bert, Roberta, la diffusion stable et d'autres modèles de génération de texte comme Bloom, GPT-J, etc. Pour une liste complète, veuillez consulter notre tableau de modèles pris en charge hérité.
Deeppeed-MII permet aux utilisateurs de créer des déploiements non persistants et persistants pour les modèles pris en charge dans quelques lignes de code.
La façon la plus fascolaire de commencer est avec notre sortie PYPI de Deeppeed-MII, ce qui signifie que vous pouvez commencer en quelques minutes via:
pip install deepspeed-miiPour une facilité d'utilisation et une réduction significative des longs temps de compilation dont de nombreux projets ont besoin dans cet espace, nous distribuons une roue Python pré-compilée couvrant la majorité de nos noyaux personnalisés via une nouvelle bibliothèque appelée Deeppeed-Kernels. Nous avons trouvé que cette bibliothèque était très portable dans les environnements avec des GPU NVIDIA avec des capacités de calcul 8.0+ (AMPERE +), CUDA 11.6+ et Ubuntu 20+. Dans la plupart des cas, vous ne devriez même pas avoir besoin de savoir que cette bibliothèque existe car il s'agit d'une dépendance de Deeppeed-MII et sera installée avec. Cependant, si pour une raison quelconque, vous devez compiler manuellement nos noyaux, veuillez consulter nos documents d'installation avancés.
Un pipeline non persistant est un excellent moyen d'essayer Deeppeed-MII. Les pipelines non persistants ne sont que pendant la durée du script Python que vous exécutez. L'exemple complet pour l'exécution d'un déploiement de pipeline non persistant n'est que de 4 lignes. Essayez-le!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) La response retournée est une liste d'objets Response . Nous pouvons accéder à plusieurs détails sur la génération (par exemple, response[0].prompt_length ):
generated_text: str généré par le modèle.prompt_length: int de jetons dans l'invite d'origine.generated_length: int de jetons générés.finish_reason: str Raison de l'arrêt de la génération. stop indique que le jeton EOS a été généré et length indique que la génération atteinte max_new_tokens ou max_length . Si vous souhaitez libérer de la mémoire de l'appareil et détruire le pipeline, utilisez la méthode destroy :
pipe . destroy () Profiter des systèmes multi-GPU pour de plus grandes performances est facile avec MII. Lorsqu'il est exécuté avec le lanceur deepspeed , le parallélisme du tenseur est automatiquement contrôlé par l'indicateur --num_gpus :
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pyBien que seul le nom ou le chemin du modèle soit requis pour supporter un déploiement de pipelines non persistant, nous proposons des options de personnalisation à nos utilisateurs:
mii.pipeline() Options :
model_name_or_path: str ou chemin local vers un modèle HuggingFace.max_length: int définit la longueur de jeton maximale par défaut pour l'invite + la réponse.all_rank_output: bool Lorsque vous êtes activé, tous les classements renvoient le texte généré. Par défaut, seul le classement 0 retournera le texte. Les utilisateurs peuvent également contrôler les caractéristiques de génération pour les invites individuelles (c'est-à-dire lors de l'appel de pipe() ) avec les options suivantes:
max_length: int définit la longueur de jeton maximale par rapport pour l'invite + la réponse.min_new_tokens: int définit le nombre minimum de jetons générés dans la réponse. max_length aura la priorité sur ce paramètre.max_new_tokens: int définit le nombre maximum de jetons générés dans la réponse.ignore_eos: bool (par défaut est False ) Le paramètre sur True empêche la génération de se terminer lorsque le jeton EOS est rencontré.top_p: float (par défaut à 0.9 ) lorsqu'il est défini en dessous de 1.0 , filtrez les jetons et ne conservez que les probabilités les plus probables, où les probabilités de jeton résument à ≥ top_p .top_k: int (par défaut à None ) en None de filtrage supérieur-k est désactivé. Lorsqu'il est défini, le nombre de jetons de probabilité les plus élevés à conserver.temperature: float (par défaut à None ) lorsque None , la température est désactivée. Lorsque vous définissez, module les probabilités de jetons.do_sample: bool (par défaut est True ) Lorsque True , exemples de logits de sortie. Lorsqu'il False , utilisez un échantillonnage gourmand.return_full_text: bool (par défaut est False ) Lorsque True , défendez l'invite d'entrée vers le texte renvoyé Un déploiement persistant est idéal pour une utilisation avec des applications de longue date et de production. Le modèle persistant utilise un serveur GRPC léger qui peut être interrogé par plusieurs clients à la fois. L'exemple complet pour l'exécution d'un modèle persistant n'est que de 5 lignes. Essayez-le!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) La response retournée est une liste d'objets Response . Nous pouvons accéder à plusieurs détails sur la génération (par exemple, response[0].prompt_length ):
generated_text: str généré par le modèle.prompt_length: int de jetons dans l'invite d'origine.generated_length: int de jetons générés.finish_reason: str Raison de l'arrêt de la génération. stop indique que le jeton EOS a été généré et length indique que la génération atteinte max_new_tokens ou max_length .Si nous voulons générer du texte à partir d'autres processus, nous pouvons également le faire:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )Lorsque nous n'avons plus besoin d'un déploiement persistant, nous pouvons fermer le serveur de tout client:
client . terminate_server () Profiter des systèmes multi-GPU pour une meilleure latence et un meilleur débit est également facile avec les déploiements persistants. Le parallélisme du modèle est contrôlé par l'entrée tensor_parallel à mii.serve :
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )Le déploiement résultant divisera le modèle sur 2 GPU pour fournir une inférence plus rapide et un débit plus élevé qu'un seul GPU.
Nous pouvons également profiter des systèmes multi-GPU (et multi-nœuds) en configurant plusieurs répliques de modèle et en profitant de l'équilibrage de la charge que Deeppeed-MII fournit:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )Le déploiement résultant chargera 2 répliques de modèle (une par GPU) et les demandes entrantes de chargement entre les 2 instances de modèle.
Le parallélisme du modèle et les répliques peuvent également être combinés pour tirer parti des systèmes avec de nombreux autres GPU. Dans l'exemple ci-dessous, nous exécutons 2 répliques de modèle, chacune se sépare de 2 GPU sur un système avec 4 GPU:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )Le choix entre le parallélisme du modèle et les répliques du modèle pour des performances maximales dépendra de la nature du matériel, du modèle et de la charge de travail. Par exemple, avec les petits modèles, les utilisateurs peuvent constater que les répliques du modèle fournissent la latence moyenne la plus faible pour les demandes. Pendant ce temps, les grands modèles peuvent atteindre un débit global plus élevé lors de l'utilisation uniquement du parallélisme du modèle.
MII facilite la configuration et l'exécution de l'inférence du modèle via des API RESTful en définissant enable_restful_api=True lors de la création d'un déploiement mii persistant. L'API RESTFul peut recevoir des demandes sur http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} . Un exemple complet est fourni ci-dessous:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ? Remarque: Bien que la fourniture d'un deployment_name ne soit pas nécessaire (MII sera automatiquement en automatiquement pour vous), il est bon à fournir un deployment_name afin que vous puissiez vous assurer d'interfaçage avec la bonne API Restful.
Vous pouvez ensuite envoyer des invites à la passerelle Restful avec n'importe quel client HTTP, comme curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment ou python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)Bien que seul le nom ou le chemin du modèle soit nécessaire pour supporter un déploiement persistant, nous offrons des options de personnalisation à nos utilisateurs.
mii.serve() Options :
model_name_or_path: str (requis) Nom ou chemin local vers un modèle HuggingFace.max_length: int (par défaut à la longueur maximale de séquence dans la configuration du modèle) définit la longueur de jeton maximale par défaut pour l'invite + la réponse.deployment_name: str (par défaut à f"{model_name_or_path}-mii-deployment" ) Une chaîne d'identification unique pour le modèle persistant. S'il est fourni, les objets clients doivent être récupérés avec client = mii.client(deployment_name) .tensor_parallel: int (par défaut est 1 ) Nombre de GPU pour diviser le modèle.replica_num: int (par défaut est 1 ) le nombre de répliques de modèle à se lever.enable_restful_api: bool (par défaut à False ) Lorsque vous activez, un processus de passerelle API reposant est lancé qui peut être interrogé sur http://{host}:{restful_api_port}/mii/{deployment_name} . Voir la section sur les API RESTFul pour plus de détails.restful_api_port: int (par défaut à 28080 ) Le numéro de port utilisé pour interfacer avec l'API RESTFul lorsque enable_restful_api est défini sur True . mii.client() Options :
model_or_deployment_name: str NOM DU MODÈLE OU deployment_name transmis à mii.serve() Les utilisateurs peuvent également contrôler les caractéristiques de génération pour les invites individuelles (c.-à-d. Lorsque vous appelez client.generate() ) avec les options suivantes:
max_length: int définit la longueur de jeton maximale par rapport pour l'invite + la réponse.min_new_tokens: int définit le nombre minimum de jetons générés dans la réponse. max_length aura la priorité sur ce paramètre.max_new_tokens: int définit le nombre maximum de jetons générés dans la réponse.ignore_eos: bool (par défaut est False ) Le paramètre sur True empêche la génération de se terminer lorsque le jeton EOS est rencontré.top_p: float (par défaut à 0.9 ) lorsqu'il est défini en dessous de 1.0 , filtrez les jetons et ne conservez que les probabilités les plus probables, où les probabilités de jeton résument à ≥ top_p .top_k: int (par défaut à None ) en None de filtrage supérieur-k est désactivé. Lorsqu'il est défini, le nombre de jetons de probabilité les plus élevés à conserver.temperature: float (par défaut à None ) lorsque None , la température est désactivée. Lorsque vous définissez, module les probabilités de jetons.do_sample: bool (par défaut est True ) Lorsque True , exemples de logits de sortie. Lorsqu'il False , utilisez un échantillonnage gourmand.return_full_text: bool (par défaut est False ) Lorsque True , défendez l'invite d'entrée vers le texte renvoyéCe projet accueille les contributions et les suggestions. La plupart des contributions vous obligent à accepter un accord de licence de contributeur (CLA) déclarant que vous avez le droit de faire et en fait, accordez-nous les droits d'utilisation de votre contribution. Pour plus de détails, visitez https://cla.opensource.microsoft.com.
Lorsque vous soumettez une demande de traction, un bot CLA déterminera automatiquement si vous devez fournir un CLA et décorer le RP de manière appropriée (par exemple, vérification d'état, commentaire). Suivez simplement les instructions fournies par le bot. Vous n'aurez besoin de le faire qu'une seule fois sur tous les dépositions en utilisant notre CLA.
Ce projet a adopté le code de conduite open source Microsoft. Pour plus d'informations, consultez le code de conduite FAQ ou contactez [email protected] avec toute question ou commentaire supplémentaire.
Ce projet peut contenir des marques ou des logos pour des projets, des produits ou des services. L'utilisation autorisée de marques ou de logos Microsoft est soumise et doit suivre les directives de marque et de marque de Microsoft. L'utilisation de marques ou de logos de Microsoft dans des versions modifiées de ce projet ne doit pas provoquer de confusion ou impliquer le parrainage de Microsoft. Toute utilisation de marques ou de logos tiers est soumis aux politiques de ces tiers.


