DeepSpeed MII
v0.3.1





تقديم MII ، مكتبة Python مفتوحة المصدر صممها Spepeded لإضفاء الطابع الديمقراطي على الاستدلال النموذجي القوي مع التركيز على الإنتاجية العالية ، والتقنية المنخفضة ، والفعالية من حيث التكلفة.
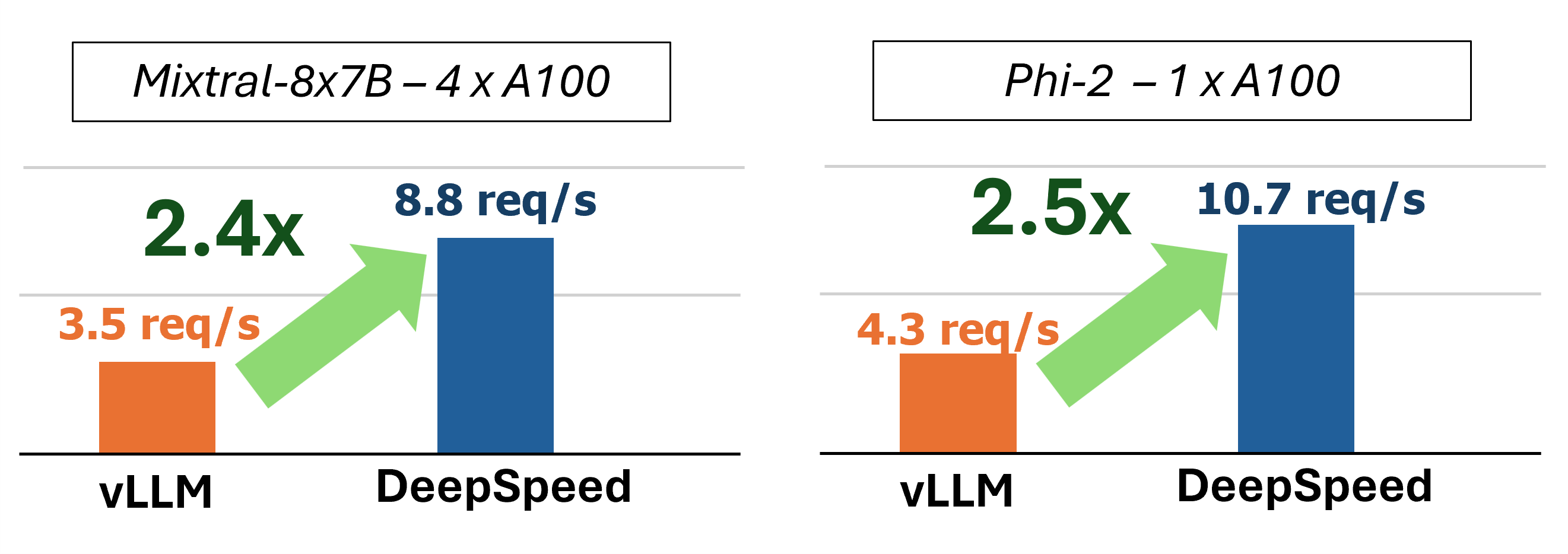
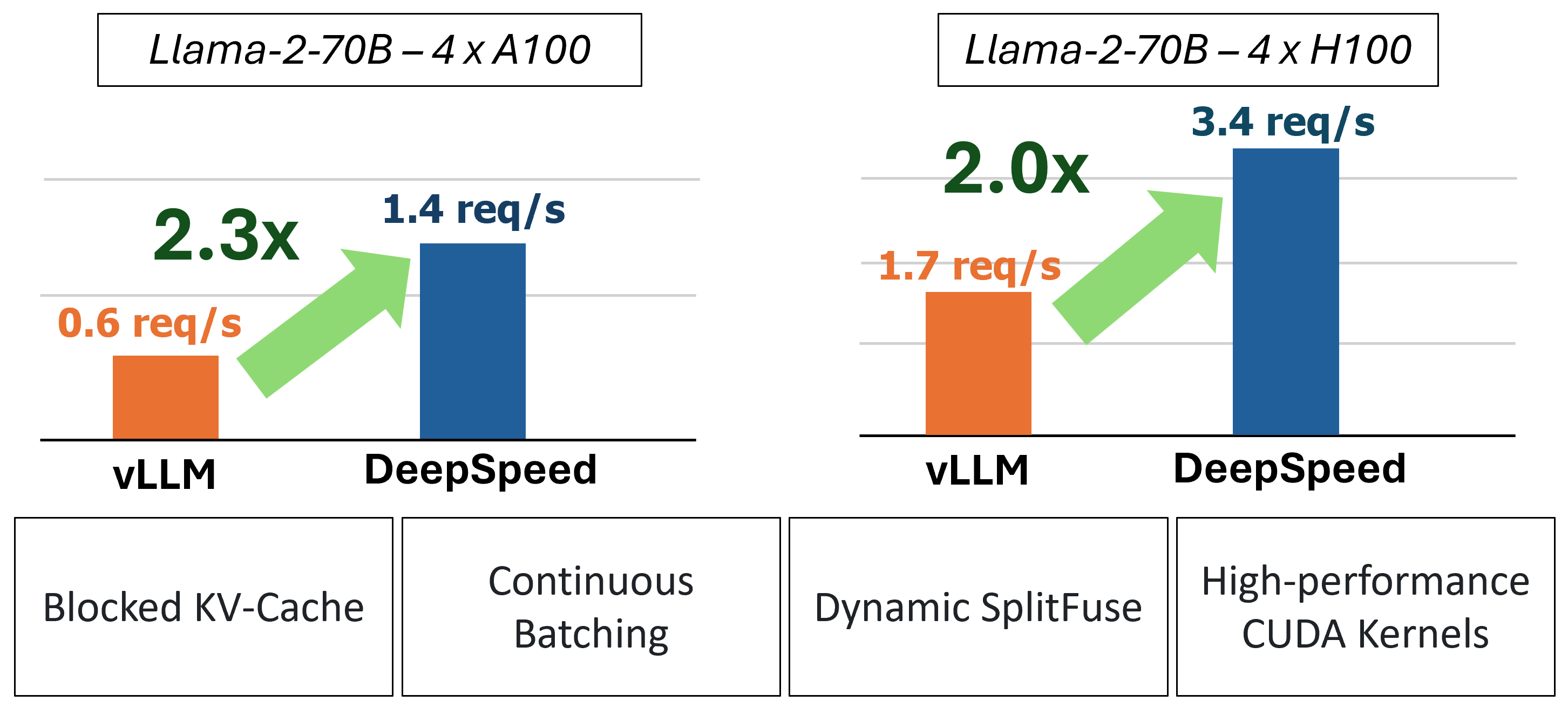
يوفر MII استدلالًا سريعًا لعملية نصي من خلال استخدام أربع تقنيات رئيسية:
من أجل الغوص الأعمق لفهم هذه الميزات ، يرجى الرجوع إلى مدونتنا والتي تتضمن أيضًا تحليل أداء مفصل.
في الماضي ، قدمت MII العديد من تحسينات الأداء الرئيسية لسيناريوهات التقديم المنخفضة للتشويش:
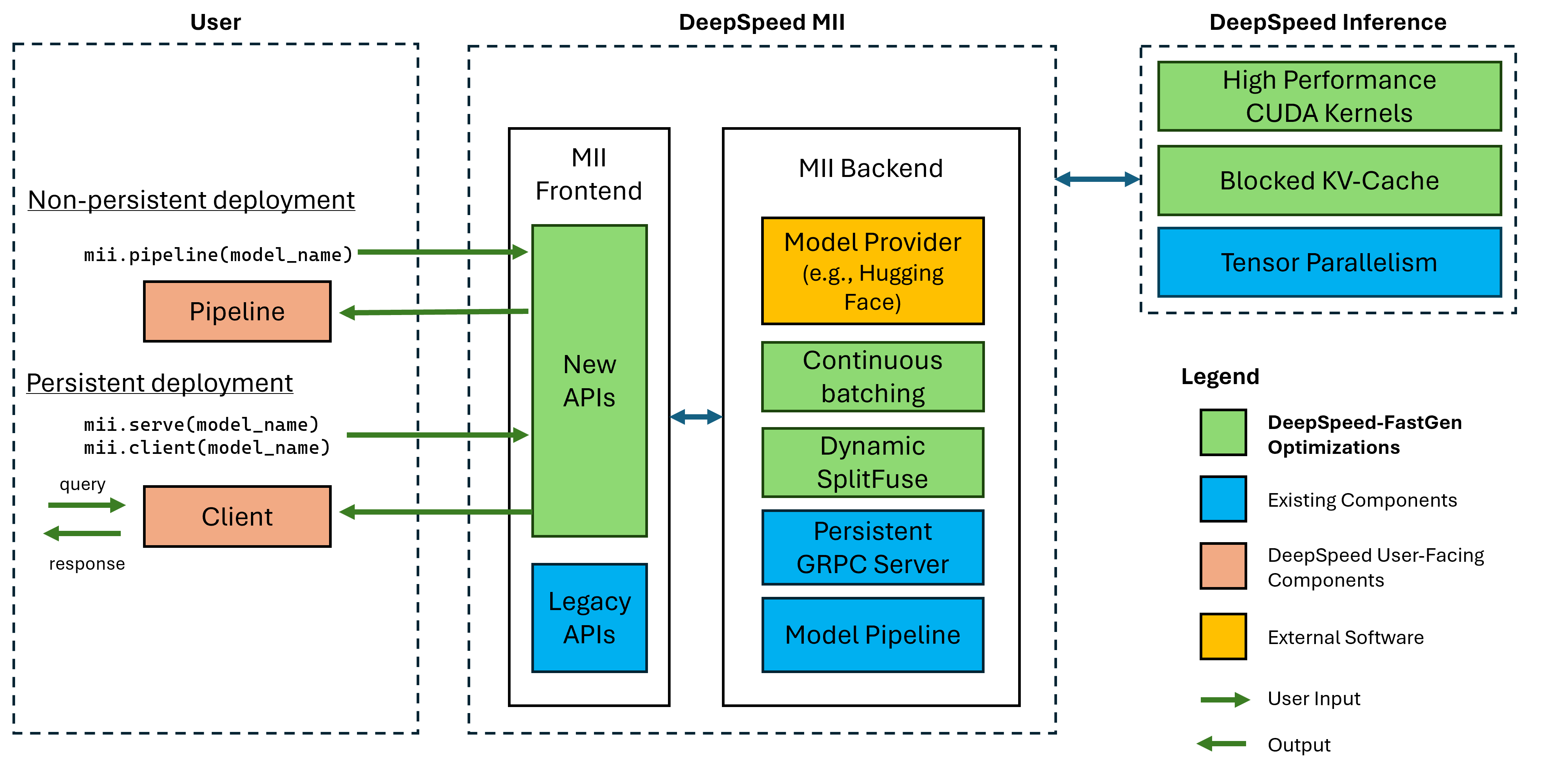
الشكل 1: بنية MII ، توضح كيفية تحسين MII تلقائيًا نماذج OSS باستخدام المؤتمر DS قبل نشرها. تم نشر تحسينات Deeped-Spastgen في الشكل في منشور المدونة لدينا.
يتم تشغيل MII تحت الغدد من خلال المؤتمر العميق. استنادًا إلى بنية النموذج ، وحجم النموذج ، وحجم الدُفعة ، وموارد الأجهزة المتاحة ، يطبق MII تلقائيًا المجموعة المناسبة من تحسينات النظام لتقليل الكمون وزيادة الإنتاجية إلى الحد الأقصى.
يدعم MII حاليًا أكثر من 37000 نموذج عبر ثمانية من هيكل النماذج الشهيرة. نخطط لإضافة نماذج إضافية على المدى القريب ، إذا كانت هناك بنية نموذجية محددة تود دعمها ، فيرجى تقديم مشكلة وإخبارنا بذلك. جميع النماذج الحالية تزيد من الوجه المعانقة في الواجهة الخلفية لدينا لتوفير كل من الأوزان النموذجية ورمز الرمز المقابل للنموذج. لإصدارنا الحالي ، ندعم بنيات النموذج التالية:
| عائلة نموذجية | نطاق الحجم | ~ عدد النماذج |
|---|---|---|
| فالكون | 7 ب - 180 ب | 600 |
| لاما | 7 ب - 65 ب | 57000 |
| لاما 2 | 7 ب - 70 ب | 1200 |
| لاما 3 | 8b - 405b | 1600 |
| خطأ | 7 ب | 23000 |
| Mixtral (Moe) | 8x7b | 2900 |
| OPT | 0.1b - 66b | 2200 |
| PHI-2 | 2.7 ب | 1500 |
| Qwen | 7 ب - 72 ب | 500 |
| Qwen2 | 0.5b - 72b | 3700 |
تدعم واجهات برمجة تطبيقات MII Legacy أكثر من 50000 نموذج مختلف بما في ذلك BERT و Roberta والانتشار المستقر ونماذج أخرى لعملية النص مثل Bloom و GPT-J ، إلخ. للحصول على قائمة كاملة ، يرجى الاطلاع على جدول النماذج المدعومة من Legacy.
يتيح Deepspeed-Mii للمستخدمين إنشاء عمليات نشر غير متسقة ومستمرة للنماذج المدعومة في بضعة أسطر من التعليمات البرمجية.
طريقة Fasest للبدء هي إصدار PYPI الخاص بنا من Deepspeed-Mii مما يعني أنه يمكنك البدء في غضون دقائق عبر:
pip install deepspeed-miiلسهولة الاستخدام وانخفاض كبير في أوقات الترجمة الطويلة التي تتطلبها العديد من المشاريع في هذا المساحة ، نقوم بتوزيع عجلة بيثون مسبقة التجميع تغطي غالبية نواةنا المخصصة من خلال مكتبة جديدة تسمى Deeped-Sped-kernels. لقد وجدنا أن هذه المكتبة محمولة للغاية عبر البيئات مع NVIDIA GPUs مع إمكانات حساب 8.0+ (AMPERE+) ، CUDA 11.6+ ، و Ubuntu 20+. في معظم الحالات ، يجب ألا تحتاج حتى إلى معرفة أن هذه المكتبة موجودة لأنها تبعية لسباق العميق وسيتم تثبيتها بها. ومع ذلك ، إذا كنت بحاجة إلى تجميع نواةنا يدويًا لأي سبب من الأسباب ، يرجى الاطلاع على مستندات التثبيت المتقدمة.
يعد خط الأنابيب غير المتسق وسيلة رائعة لتجربة Spedspeed-Mii. خطوط الأنابيب غير المتسقة موجودة فقط طوال مدة البرنامج النصي Python الذي تقوم بتشغيله. المثال الكامل لتشغيل نشر خط أنابيب غير متسق هو 4 أسطر فقط. جربها!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) response التي تم إرجاعها هي قائمة كائنات Response . يمكننا الوصول إلى عدة تفاصيل حول الجيل (على سبيل المثال ، response[0].prompt_length ):
generated_text: str تم إنشاؤه بواسطة النموذج.prompt_length: int عدد الرموز في المطالبة الأصلية.generated_length: int عدد الرموز التي تم إنشاؤها.finish_reason: str سبب لإيقاف الجيل. يشير stop إلى تم إنشاء رمز EOS ويشير length إلى أن الجيل وصل إلى max_new_tokens أو max_length . إذا كنت ترغب في تحرير ذاكرة الجهاز وتدمير خط الأنابيب ، فاستخدم طريقة destroy :
pipe . destroy () من السهل الاستفادة من أنظمة GPU متعددة الأداء بشكل أكبر مع MII. عند تشغيله باستخدام قاذفة deepspeed ، يتم التحكم تلقائيًا في التوازي التلقائي بواسطة علامة --num_gpus :
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pyعلى الرغم من أن اسم النموذج أو المسار مطلوب فقط للوقوف على نشر خط أنابيب غير متسق ، فإننا نقدم خيارات التخصيص لمستخدمينا:
خيارات mii.pipeline() :
model_name_or_path: str أو المسار المحلي إلى نموذج Huggingface.max_length: int تقوم بتعيين طول الرمز القصوى الافتراضي لاستجابة المطالبة +.all_rank_output: bool عند تمكينها ، تُرجع جميع الرتب النص الذي تم إنشاؤه. بشكل افتراضي ، سيعود المرتبة 0 فقط إلى النص. يمكن للمستخدمين أيضًا التحكم في خصائص توليد المطالبات الفردية (أي ، عند استدعاء pipe() ) مع الخيارات التالية:
max_length: int يقوم بتعيين الحد الأقصى للرمز المميز لكل ما يعرض للاستجابة المطالبة +.min_new_tokens: int يحدد الحد الأدنى لعدد الرموز التي تم إنشاؤها في الاستجابة. max_length سوف له الأسبقية على هذا الإعداد.max_new_tokens: int يحدد الحد الأقصى لعدد الرموز التي تم إنشاؤها في الاستجابة.ignore_eos: bool (الإعدادات الافتراضية إلى False ) إلى True يمنع التوليد من النهاية عند مواجهة رمز EOS.top_p: float (الإعدادات الافتراضية إلى 0.9 ) عند تعيينه أقل من 1.0 ، قم بتصفية الرموز والحفاظ على الأكثر احتمالًا فقط ، حيث يلخص احتمالات الرمز المميز إلى ≥ top_p .top_k: int (الافتراضيات إلى None ) عندما None ، يتم تعطيل تصفية Top-K. عند التعيين ، فإن عدد رموز الاحتمالات الأعلى للحفاظ عليها.temperature: float (التخلف عن السداد إلى None ) عندما None ، يتم تعطيل درجة الحرارة. عند التعيين ، يعدل احتمالات الرمز المميز.do_sample: bool (الإعدادات الافتراضية إلى True ) عندما True ، عينة سجلات الإخراج. عندما يكون False ، استخدم أخذ العينات الجشع.return_full_text: bool (الإعدادات الافتراضية إلى False ) عندما True ، يسبق موجه الإدخال إلى النص الذي تم إرجاعه يعد النشر المستمر مثاليًا للاستخدام مع تطبيقات الإنتاج طويلة الأمد. يستخدم النموذج المستمر خادم GRPC خفيف الوزن يمكن الاستعلام عنه من قبل عملاء متعددين في وقت واحد. المثال الكامل لتشغيل نموذج ثابت هو 5 أسطر فقط. جربها!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) response التي تم إرجاعها هي قائمة كائنات Response . يمكننا الوصول إلى عدة تفاصيل حول الجيل (على سبيل المثال ، response[0].prompt_length ):
generated_text: str تم إنشاؤه بواسطة النموذج.prompt_length: int عدد الرموز في المطالبة الأصلية.generated_length: int عدد الرموز التي تم إنشاؤها.finish_reason: str سبب لإيقاف الجيل. يشير stop إلى تم إنشاء رمز EOS ويشير length إلى أن الجيل وصل إلى max_new_tokens أو max_length .إذا أردنا إنشاء نص من عمليات أخرى ، فيمكننا القيام بذلك أيضًا:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )عندما لم نعد بحاجة إلى نشر مستمر ، يمكننا إيقاف الخادم من أي عميل:
client . terminate_server () الاستفادة من أنظمة GPU متعددة من أجل زمن الوصول والإنتاجية أفضل أيضًا مع عمليات النشر المستمرة. يتم التحكم في التوازي النموذجية بواسطة tensor_parallel INPORT إلى mii.serve :
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )سيقوم النشر الناتج بتقسيم النموذج عبر 2 وحدات معالجة الرسومات لتوفير استنتاج أسرع وإنتاجية أعلى من وحدة معالجة الرسومات الواحدة.
يمكننا أيضًا الاستفادة من أنظمة GPU (والعقدة المتعددة) المتعددة عن طريق إعداد النسخ المتماثلة النموذجية المتعددة والاستفادة من توازن الحمل الذي يوفره Deepspeed-Mii:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )سيقوم النشر الناتج بتحميل النسخ المتماثلة النموذجية (واحدة لكل وحدة معالجة الرسومات) وطلبات التوازن الواردة بين مثالين النموذجين.
يمكن أيضًا دمج التوازي النموذجية والنسخ المتماثلة للاستفادة من الأنظمة مع العديد من وحدات معالجة الرسومات. في المثال أدناه ، نقوم بتشغيل نسخ متماثلة من طراز 2 ، كل منها منقسم عبر 2 وحدات معالجة الرسومات على نظام مع 4 وحدات معالجة الرسومات:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )يعتمد الاختيار بين موازاة النموذج والنسخ المتماثل للأداء الأقصى على طبيعة الأجهزة والنموذج وعبلة العمل. على سبيل المثال ، مع الطرز الصغيرة ، قد يجد المستخدمون أن النسخ المتماثلة النموذجية توفر أدنى متوسط زمن استمرار للطلبات. وفي الوقت نفسه ، قد تحقق النماذج الكبيرة إنتاجية بشكل عام أكبر عند استخدام موازاة النموذج فقط.
يجعل MII من السهل إعداد وتشغيل الاستدلال النموذج عبر واجهات برمجة التطبيقات RESTFul من خلال تعيين enable_restful_api=True عند إنشاء نشر MII مستمر. يمكن أن تتلقى واجهة برمجة تطبيقات Restful طلبات على http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} . مثال كامل أدناه:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ؟ ملاحظة: في حين أن تقديم deployment_name ليس ضروريًا (سيقوم Mii بتدوين التلقائي من أجلك) ، فمن الجيد توفير deployment_name حتى تتمكن من التأكد من أنك تتداخل مع واجهة برمجة التطبيقات الصحيحة الصحيحة.
يمكنك بعد ذلك إرسال مطالبات إلى بوابة Restful مع أي عميل HTTP ، مثل curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment أو python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)بينما لا يلزم سوى اسم النموذج أو المسار للوقوف على نشر مستمر ، فإننا نقدم خيارات التخصيص لمستخدمينا.
خيارات mii.serve() :
model_name_or_path: str (مطلوب) الاسم أو المسار المحلي إلى نموذج Huggingface.max_length: int (الافتراضيات إلى الحد الأقصى لطول التسلسل في التكوين النموذج) يعين الحد الأقصى لطول الرمز المميز الافتراضي لاستجابة المطالبة +.deployment_name: str (الافتراضيات إلى f"{model_name_or_path}-mii-deployment" ) سلسلة تعريف فريدة للنموذج الثابت. إذا تم توفيرها ، يجب استرداد كائنات العميل باستخدام client = mii.client(deployment_name) .tensor_parallel: int (الافتراضيات إلى 1 ) عدد وحدات معالجة الرسومات لتقسيم النموذج عبر.replica_num: int (الإعدادات الافتراضية إلى 1 ) عدد النسخ المتماثلة النموذجية للوقوف.enable_restful_api: bool (الإعدادات الافتراضية إلى False ) عند تمكينه ، يتم إطلاق عملية بوابة API المريحة التي يمكن الاستعلام عنها على http://{host}:{restful_api_port}/mii/{deployment_name} . راجع القسم الموجود في واجهات برمجة التطبيقات المريحة لمزيد من التفاصيل.restful_api_port: int (الإعدادات الافتراضية إلى 28080 ) رقم المنفذ المستخدم للتفاعل مع واجهة برمجة تطبيقات RESTful عند ضبط enable_restful_api على True . خيارات mii.client() :
model_or_deployment_name: str تم تمرير اسم النموذج أو deployment_name إلى mii.serve() يمكن للمستخدمين أيضًا التحكم في خصائص توليد المطالبات الفردية (أي ، عند الاتصال client.generate() ) مع الخيارات التالية:
max_length: int يقوم بتعيين الحد الأقصى للرمز المميز لكل ما يعرض للاستجابة المطالبة +.min_new_tokens: int يحدد الحد الأدنى لعدد الرموز التي تم إنشاؤها في الاستجابة. max_length سوف له الأسبقية على هذا الإعداد.max_new_tokens: int يحدد الحد الأقصى لعدد الرموز التي تم إنشاؤها في الاستجابة.ignore_eos: bool (الإعدادات الافتراضية إلى False ) إلى True يمنع التوليد من النهاية عند مواجهة رمز EOS.top_p: float (الإعدادات الافتراضية إلى 0.9 ) عند تعيينه أقل من 1.0 ، قم بتصفية الرموز والحفاظ على الأكثر احتمالًا فقط ، حيث يلخص احتمالات الرمز المميز إلى ≥ top_p .top_k: int (الافتراضيات إلى None ) عندما None ، يتم تعطيل تصفية Top-K. عند التعيين ، فإن عدد رموز الاحتمالات الأعلى للحفاظ عليها.temperature: float (التخلف عن السداد إلى None ) عندما None ، يتم تعطيل درجة الحرارة. عند التعيين ، يعدل احتمالات الرمز المميز.do_sample: bool (الإعدادات الافتراضية إلى True ) عندما True ، عينة سجلات الإخراج. عندما يكون False ، استخدم أخذ العينات الجشع.return_full_text: bool (الإعدادات الافتراضية إلى False ) عندما True ، يسبق موجه الإدخال إلى النص الذي تم إرجاعهيرحب هذا المشروع بالمساهمات والاقتراحات. تطلب منك معظم المساهمات الموافقة على اتفاقية ترخيص المساهم (CLA) مع إعلان أن لديك الحق في ذلك في الواقع ، ويفعلنا في الواقع حقوق استخدام مساهمتك. لمزيد من التفاصيل ، تفضل بزيارة https://cla.opensource.microsoft.com.
عند إرسال طلب سحب ، سيحدد CLA Bot تلقائيًا ما إذا كنت بحاجة إلى توفير CLA وتزيين العلاقات العامة بشكل مناسب (على سبيل المثال ، فحص الحالة ، التعليق). ببساطة اتبع الإرشادات التي يقدمها الروبوت. ستحتاج فقط إلى القيام بذلك مرة واحدة عبر جميع عمليات إعادة الشراء باستخدام CLA لدينا.
اعتمد هذا المشروع رمز سلوك المصدر المفتوح Microsoft. لمزيد من المعلومات ، راجع مدونة الشهادة الأسئلة الشائعة أو الاتصال بـ [email protected] مع أي أسئلة أو تعليقات إضافية.
قد يحتوي هذا المشروع على علامات تجارية أو شعارات للمشاريع أو المنتجات أو الخدمات. يخضع الاستخدام المعتمد للعلامات التجارية أو الشعارات Microsoft ويجب أن يتبعوا إرشادات Microsoft التجارية والعلامة التجارية. يجب ألا يسبب استخدام العلامات التجارية Microsoft أو الشعارات في إصدارات معدلة من هذا المشروع الارتباك أو يعني رعاية Microsoft. يخضع أي استخدام للعلامات التجارية أو الشعارات من طرف ثالث لسياسات تلك الطرف الثالث.


