DeepSpeed MII
v0.3.1





Einführung von MII, einer Open-Source-Python-Bibliothek, die von DeepSpeed entworfen wurde, um mächtige Modellinferenz zu demokratisieren, konzentriert sich auf Hochdurchsatz, niedrige Latenz und Kosteneffizienz.
MII bietet durch die Verwendung von vier Schlüsseltechnologien eine beschleunigte Inferenz für die Textegeneration:
Für einen tieferen Einblick in das Verständnis dieser Funktionen finden Sie in unserem Blog, der auch eine detaillierte Leistungsanalyse enthält.
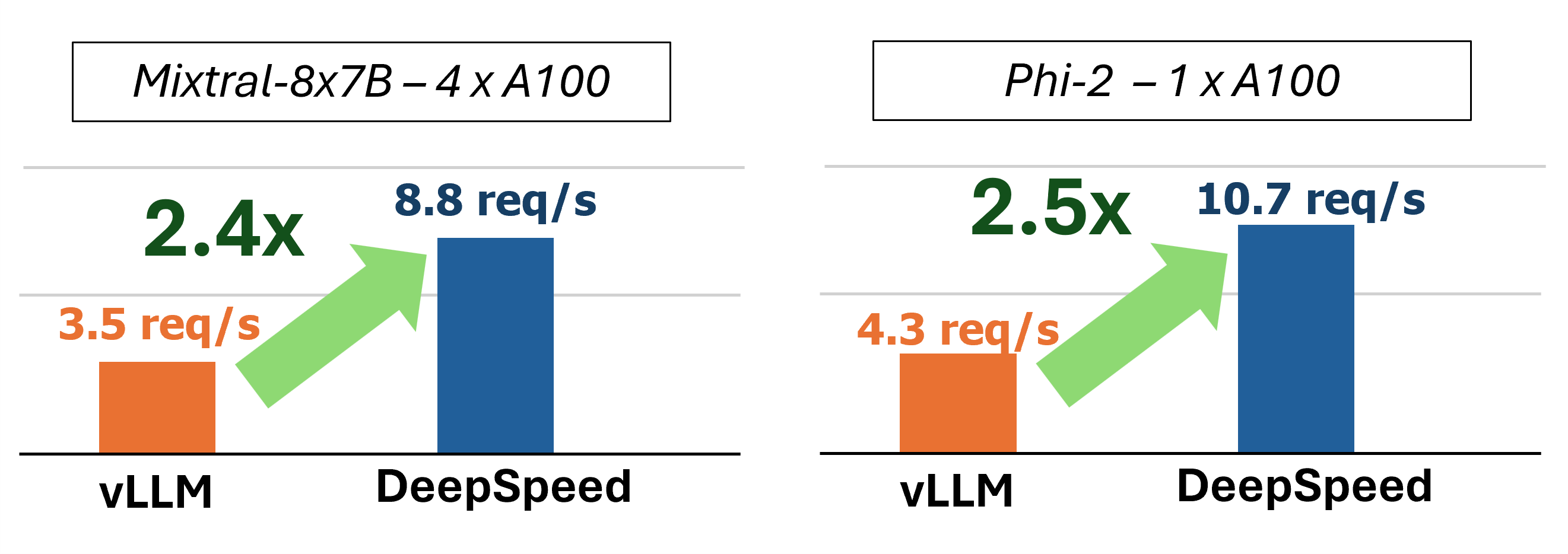
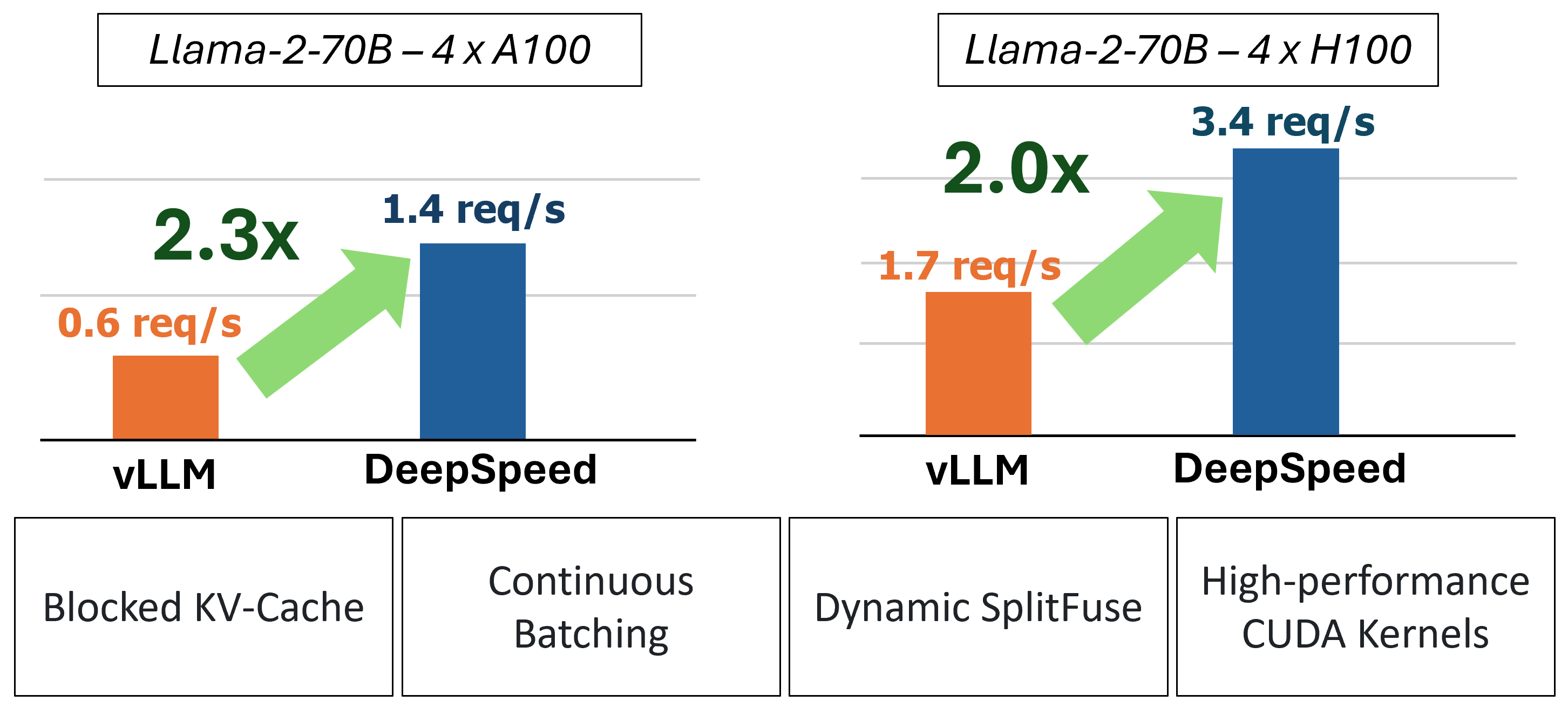
In der Vergangenheit führte MII mehrere wichtige Leistungsoptimierungen für Szenarien mit geringer Latenz ein:
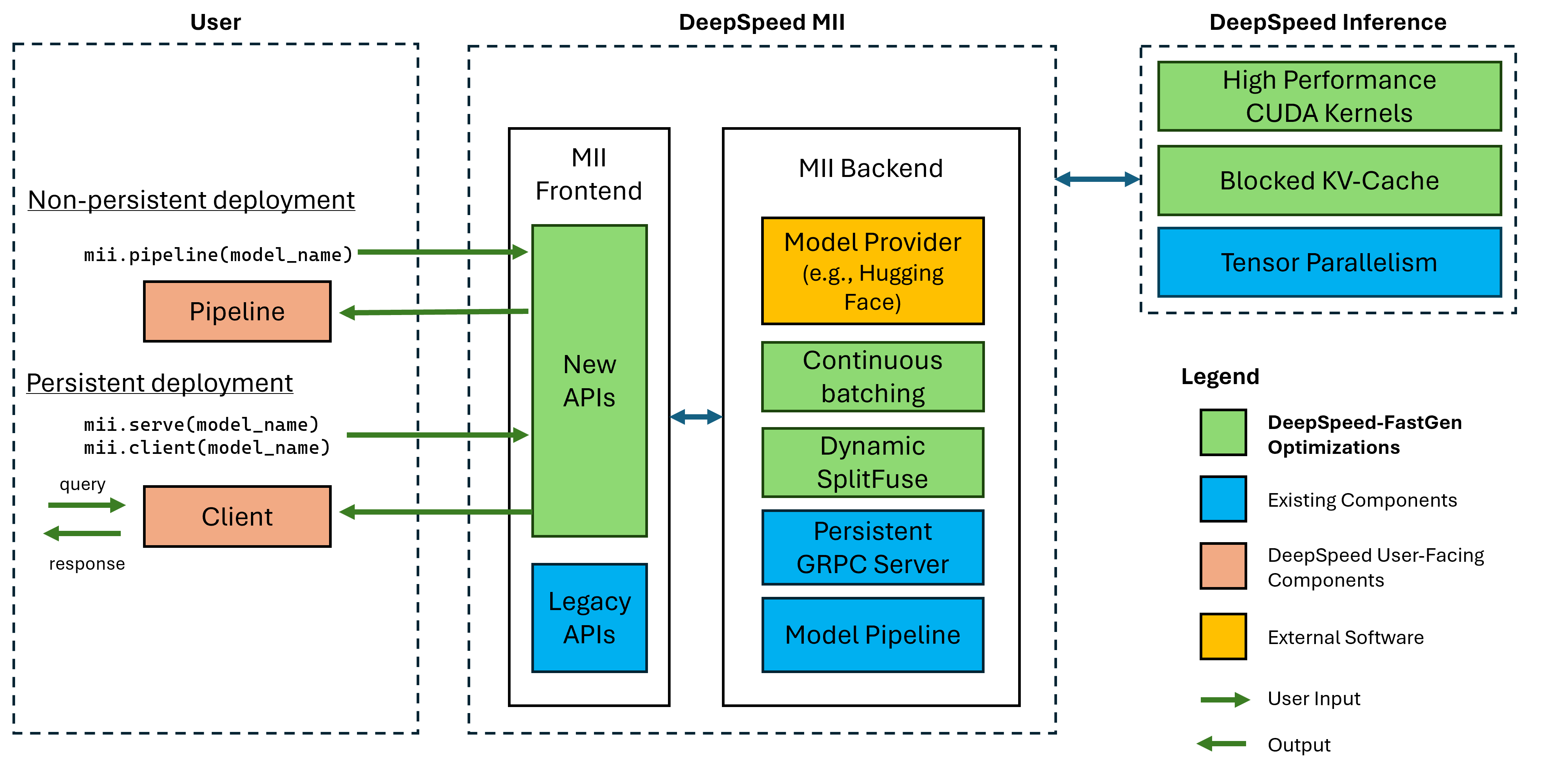
Abbildung 1: MII-Architektur und zeigt, wie MII OSS-Modelle automatisch mithilfe von DS-Inferenz optimiert, bevor sie bereitgestellt werden. In unserem Blog-Beitrag wurden Deepspeed-Fastgen-Optimierungen in der Figur veröffentlicht.
Unter dem Haus wird MII durch Deepspeed-Inferenz angetrieben. Basierend auf der Modellarchitektur, der Modellgröße, der Stapelgröße und der verfügbaren Hardware -Ressourcen wendet MII automatisch den entsprechenden Satz von Systemoptimierungen an, um die Latenz zu minimieren und den Durchsatz zu maximieren.
MII unterstützt derzeit über 37.000 Modelle in acht beliebten Modellarchitekturen. Wir planen, kurzfristig zusätzliche Modelle hinzuzufügen. Wenn es spezifische Modellarchitekturen gibt, die Sie unterstützt möchten, stellen Sie bitte ein Problem ein und teilen Sie es uns mit. Alle aktuellen Modelle nutzen das Umarmungsgesicht in unserem Backend, um sowohl die Modellgewichte als auch die entsprechende Tokenzeigerin des Modells bereitzustellen. Für unsere aktuelle Version unterstützen wir die folgenden Modellarchitekturen:
| Modellfamilie | Größenbereich | ~ Modellzahl |
|---|---|---|
| Falke | 7b - 180b | 600 |
| Lama | 7b - 65b | 57.000 |
| LAMA-2 | 7b - 70b | 1.200 |
| Lama-3 | 8b - 405b | 1.600 |
| Mistral | 7b | 23.000 |
| Mixtral (MOE) | 8x7b | 2.900 |
| Opt | 0,1b - 66b | 2.200 |
| Phi-2 | 2.7b | 1.500 |
| Qwen | 7b - 72b | 500 |
| Qwen2 | 0,5b - 72b | 3700 |
Mii Legacy APIs unterstützen über 50.000 verschiedene Modelle, darunter Bert, Roberta, stabile Diffusion und andere Modelle für Textegeneration wie Bloom, GPT-J usw. Für eine vollständige Liste finden Sie in unserer tablischen Modelle in unserer Legacy-unterstützten Modellen.
Mit DeepSpeed-Mii können Benutzer nicht-persistente und anhaltende Bereitstellungen für unterstützte Modelle in nur wenigen Codezeilen erstellen.
Die Möglichkeit, mit unserer PYPI-Freisetzung von DeepSpeed-Mii zu beginnen, bedeutet, dass Sie innerhalb von Minuten beginnen können:
pip install deepspeed-miiFür die Benutzerfreundlichkeit und eine signifikante Verringerung der langen Kompilierungszeiten, die viele Projekte in diesem Bereich erfordern, verteilen wir ein vorkompiliertes Python-Rad, das den Großteil unserer kundenspezifischen Kernel über eine neue Bibliothek namens DeepSpeed-Kernels abdeckt. Wir haben festgestellt, dass diese Bibliothek über Umgebungen mit NVIDIA -GPUs mit Rechenfunktionen 8.0+ (Ampere+), CUDA 11.6+ und Ubuntu 20+ sehr tragbar ist. In den meisten Fällen sollten Sie nicht einmal wissen, dass diese Bibliothek existiert, da es sich um eine Abhängigkeit von DeepSpeed-MII handelt und damit installiert wird. Wenn Sie jedoch aus irgendeinem Grund unsere Kernel manuell kompilieren müssen, lesen Sie bitte unsere erweiterten Installationsdokumente.
Eine nicht-persistente Pipeline ist eine großartige Möglichkeit, Deepspeed-Mii zu versuchen. Nicht-persistente Pipelines sind nur für die Dauer des von Ihnen ausgeführten Python-Skripts vorhanden. Das vollständige Beispiel für die Ausführung einer nicht-persistenten Pipeline-Bereitstellung beträgt nur 4 Zeilen. Probieren Sie es aus!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) Die zurückgegebene response ist eine Liste von Response . Wir können auf verschiedene Details zur Generation zugreifen (z. B. response[0].prompt_length ):
generated_text: str -Text generiert vom Modell.prompt_length: int Anzahl der Token in der ursprünglichen Eingabeaufforderung.generated_length: int Anzahl der generierten Token.finish_reason: str Grund für die Beendigung der Generation. stop gibt an, dass das EOS -Token generiert wurde und length zeigt, dass die Generation max_new_tokens oder max_length erreicht hat. Wenn Sie den Speicher des Gerätespeichers freigeben und die Pipeline zerstören möchten, verwenden Sie die destroy :
pipe . destroy () Mit MII ist die Nutzung von Multi-GPU-Systemen für eine größere Leistung einfach. Wenn Sie mit dem deepspeed -Launcher ausgeführt werden, wird die Tensor -Parallelität automatisch durch das Flag --num_gpus gesteuert:
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pyWährend nur der Modellname oder Pfad für eine nicht-persistente Pipeline-Bereitstellung erforderlich ist, bieten wir unseren Benutzern Anpassungsoptionen an:
mii.pipeline() Optionen :
model_name_or_path: str -Name oder lokaler Pfad zu einem Umarmungsface -Modell.max_length: int legt die Standard -Maximum -Token -Länge für die Eingabeaufforderung + -Reaktion fest.all_rank_output: bool Wenn aktiviert, gibt alle Ränge den generierten Text zurück. Standardmäßig gibt nur Rang 0 Text zurück. Benutzer können auch die Erzeugungsmerkmale für einzelne Eingabeaufforderungen (dh beim Aufrufen pipe() ) mit den folgenden Optionen steuern:
max_length: int legt die maximale tokenlänge pro prompt für die Eingabeaufforderung + Antwort fest.min_new_tokens: int legt die Mindestanzahl der in der Antwort generierten Token fest. max_length hat Vorrang vor dieser Einstellung.max_new_tokens: int legt die maximale Anzahl der in der Antwort generierten Token fest.ignore_eos: bool (standardmäßig zu False ) Einstellung zu True verhindert, dass die Erzeugung beim Auftreten des EOS -Tokens endet.top_p: float (Standardeinstellungen bis 0.9 ) Wenn Sie unter 1.0 gesetzt sind, filtern Sie Token und halten Sie nur die wahrscheinlichsten, wo Token -Wahrscheinlichkeiten zu ≥ top_p summieren.top_k: int (standardmäßig None ) Wenn None , ist die Top-K-Filterung deaktiviert. Bei der Einstellung die Anzahl der Token mit höchster Wahrscheinlichkeit, die Sie halten können.temperature: float (standardmäßig None ) Wenn None , ist die Temperatur deaktiviert. Moduliert beim Einstellen die Token -Wahrscheinlichkeiten.do_sample: bool (Standard zu True ) Wenn True , Beispielausgabeprotokoll. Wenn False , verwenden Sie gierige Probenahme.return_full_text: bool (Standard zu False ) Wenn True die Eingabeaufforderung für den zurückgegebenen Text vorbereitet Eine anhaltende Bereitstellung ist ideal für die Verwendung von langjährigen und Produktionsanwendungen. Das persistente Modell verwendet einen leichten GRPC -Server, der von mehreren Clients gleichzeitig abgefragt werden kann. Das vollständige Beispiel für das Ausführen eines persistenten Modells beträgt nur 5 Zeilen. Probieren Sie es aus!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) Die zurückgegebene response ist eine Liste von Response . Wir können auf verschiedene Details zur Generation zugreifen (z. B. response[0].prompt_length ):
generated_text: str -Text generiert vom Modell.prompt_length: int Anzahl der Token in der ursprünglichen Eingabeaufforderung.generated_length: int Anzahl der generierten Token.finish_reason: str Grund für die Beendigung der Generation. stop gibt an, dass das EOS -Token generiert wurde und length zeigt, dass die Generation max_new_tokens oder max_length erreicht hat.Wenn wir Text aus anderen Prozessen generieren möchten, können wir dies auch tun:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )Wenn wir keine anhaltende Bereitstellung mehr benötigen, können wir den Server von jedem Client herunterladen:
client . terminate_server () Die Nutzung von Multi-GPU-Systemen für eine bessere Latenz und Durchsatz ist auch bei den anhaltenden Bereitstellungen einfach. Die Modellparallelität wird durch die tensor_parallel -Eingabe in mii.serve gesteuert:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )Die resultierende Bereitstellung spaltet das Modell über 2 GPUs auf, um eine schnellere Inferenz und einen höheren Durchsatz zu liefern als eine einzelne GPU.
Wir können auch Multi-GPU-Systeme (und Multi-Knoten) nutzen, indem wir mehrere Modellreplikas einrichten und das Lastausgleich nutzen, das Deepspeed-Mii bietet:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )Die resultierende Bereitstellung lädt 2 Modellreplikate (eine pro GPU) und eingehende Anforderungen der Ladeausgleich zwischen den 2 Modellinstanzen.
Modellparallelität und Repliken können auch kombiniert werden, um Systeme mit viel mehr GPUs zu nutzen. Im folgenden Beispiel führen wir 2 Modellrepliken aus, die jeweils über 2 GPUs auf einem System mit 4 GPUs aufgeteilt werden:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )Die Auswahl zwischen Modellparallelität und Modellreplikationen für die maximale Leistung hängt von der Art der Hardware, des Modells und der Arbeitsbelastung ab. Bei kleinen Modellen können Benutzer beispielsweise feststellen, dass Modellrepliken die niedrigste durchschnittliche Latenz für Anfragen bieten. In der Zwischenzeit können große Modelle einen größeren Gesamtdurchsatz erzielen, wenn nur die Modellparallelität verwendet wird.
Mii erleichtert das Einrichten und Ausführen von Modellinferenz über erholsame APIs, indem Sie bei der Erstellung einer persistenten MII -Bereitstellung enable_restful_api=True einstellen. Die RESTful -API kann Anfragen unter http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} erhalten. Ein vollständiges Beispiel finden Sie unten:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ? HINWEIS: Während die Bereitstellung eines deployment_name nicht erforderlich ist (MII wird einen für Sie autogeneriert), ist es eine gute Praxis, einen deployment_name bereitzustellen, damit Sie sicherstellen können, dass Sie sich mit der richtigen API mit der richtigen Pause verbinden.
Sie können dann mit jedem HTTP -Client Eingabeaufforderungen an das erholsame Gateway senden, z. B. curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment oder python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)Während nur der Modellname oder Pfad erforderlich ist, um eine anhaltende Bereitstellung aufzustehen, bieten wir unseren Benutzern Anpassungsoptionen an.
mii.serve() Optionen :
model_name_or_path: str (erforderlich) Name oder lokaler Pfad zu einem HarmgingFace -Modell.max_length: int (Standards bis maximale Sequenzlänge in der Modellkonfiguration) Legt die Standard -Maximum -Token -Länge für die Eingabeaufforderung + -Ronaktion fest.deployment_name: str (Standards zu f"{model_name_or_path}-mii-deployment" ) Eine eindeutige Identifizierungszeichenfolge für das persistente Modell. Wenn dies bereitgestellt wird, sollten Clientobjekte mit client = mii.client(deployment_name) abgerufen werden.tensor_parallel: int (Standards bis 1 ) Anzahl von GPUs, um das Modell überzuteilen.replica_num: int (standards to 1 ) die Anzahl der Modellreplikate, die aufstehen sollen.enable_restful_api: bool (standardnaugs to False ) Wenn aktiviert, wird ein RESTFOFFFUL -Gateway -Prozess gestartet, der unter http://{host}:{restful_api_port}/mii/{deployment_name} abfragen kann. Weitere Informationen finden Sie im Abschnitt über erholsame APIs.restful_api_port: int (standards to 28080 ) Die Portnummer, die zur Schnittstelle mit der erholsamen API verwendet wird, wenn enable_restful_api auf True eingestellt ist. mii.client() Optionen :
model_or_deployment_name: str -Name des Modells oder deployment_name an mii.serve() übergeben Benutzer können auch die Erzeugungsmerkmale für einzelne Eingabeaufforderungen (dh beim Aufrufen client.generate() ) mit den folgenden Optionen steuern:
max_length: int legt die maximale tokenlänge pro prompt für die Eingabeaufforderung + Antwort fest.min_new_tokens: int legt die Mindestanzahl der in der Antwort generierten Token fest. max_length hat Vorrang vor dieser Einstellung.max_new_tokens: int legt die maximale Anzahl der in der Antwort generierten Token fest.ignore_eos: bool (standardmäßig zu False ) Einstellung zu True verhindert, dass die Erzeugung beim Auftreten des EOS -Tokens endet.top_p: float (Standardeinstellungen bis 0.9 ) Wenn Sie unter 1.0 gesetzt sind, filtern Sie Token und halten Sie nur die wahrscheinlichsten, wo Token -Wahrscheinlichkeiten zu ≥ top_p summieren.top_k: int (standardmäßig None ) Wenn None , ist die Top-K-Filterung deaktiviert. Bei der Einstellung die Anzahl der Token mit höchster Wahrscheinlichkeit, die Sie halten können.temperature: float (standardmäßig None ) Wenn None , ist die Temperatur deaktiviert. Moduliert beim Einstellen die Token -Wahrscheinlichkeiten.do_sample: bool (Standard zu True ) Wenn True , Beispielausgabeprotokoll. Wenn False , verwenden Sie gierige Probenahme.return_full_text: bool (Standard zu False ) Wenn True die Eingabeaufforderung für den zurückgegebenen Text vorbereitetDieses Projekt begrüßt Beiträge und Vorschläge. In den meisten Beiträgen müssen Sie einer Mitarbeiters Lizenzvereinbarung (CLA) zustimmen, in der Sie erklären, dass Sie das Recht haben und uns tatsächlich tun, um uns die Rechte zu gewähren, Ihren Beitrag zu verwenden. Weitere Informationen finden Sie unter https://cla.opensource.microsoft.com.
Wenn Sie eine Pull -Anfrage einreichen, bestimmt ein CLA -Bot automatisch, ob Sie einen CLA angeben und die PR angemessen dekorieren müssen (z. B. Statusprüfung, Kommentar). Befolgen Sie einfach die vom Bot bereitgestellten Anweisungen. Sie müssen dies nur einmal über alle Repos mit unserem CLA tun.
Dieses Projekt hat den Microsoft Open Source -Verhaltenscode übernommen. Weitere Informationen finden Sie im FAQ oder wenden Sie sich an [email protected] mit zusätzlichen Fragen oder Kommentaren.
Dieses Projekt kann Marken oder Logos für Projekte, Produkte oder Dienstleistungen enthalten. Die autorisierte Verwendung von Microsoft -Marken oder Logos unterliegt den Marken- und Markenrichtlinien von Microsoft und muss folgen. Die Verwendung von Microsoft -Marken oder Logos in geänderten Versionen dieses Projekts darf keine Verwirrung verursachen oder Microsoft -Sponsoring implizieren. Jede Verwendung von Marken oder Logos von Drittanbietern unterliegt den Richtlinien dieses Drittanbieters.


