DeepSpeed MII
v0.3.1





High-Throughput、LaTENCY、および費用対効果に焦点を当てて、強力なモデル推論を民主化するためにDeepSpeedによって設計されたオープンソースのPythonライブラリであるMIIを導入します。
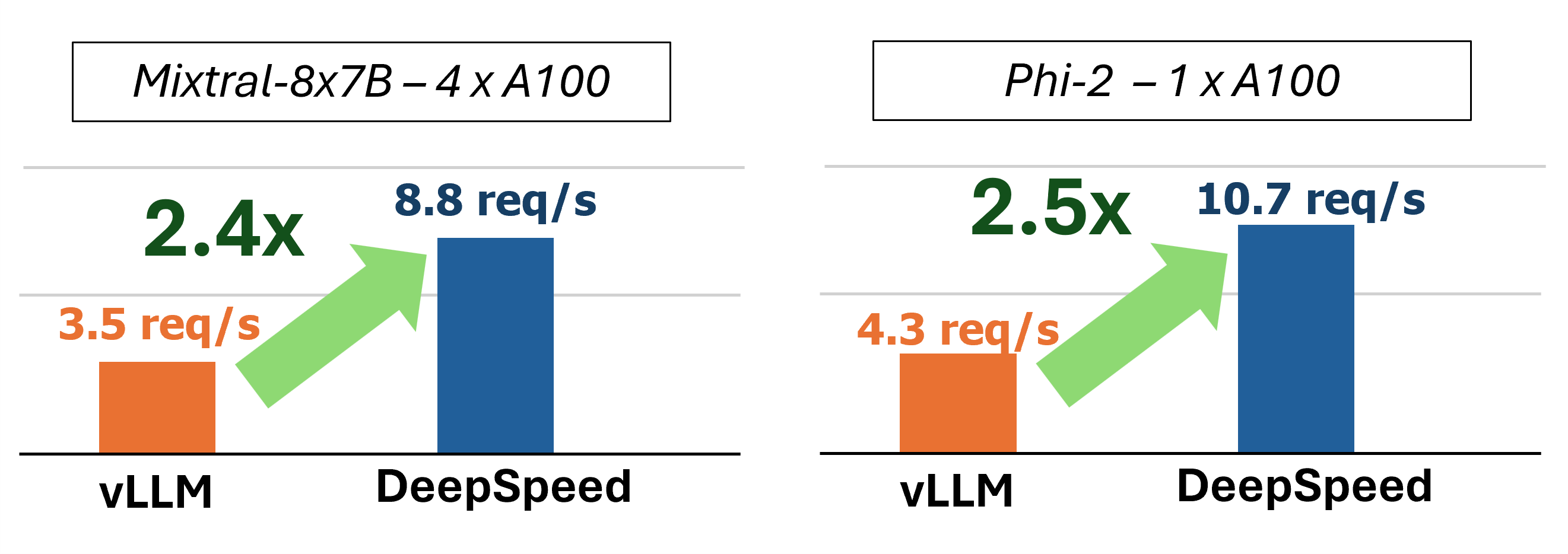
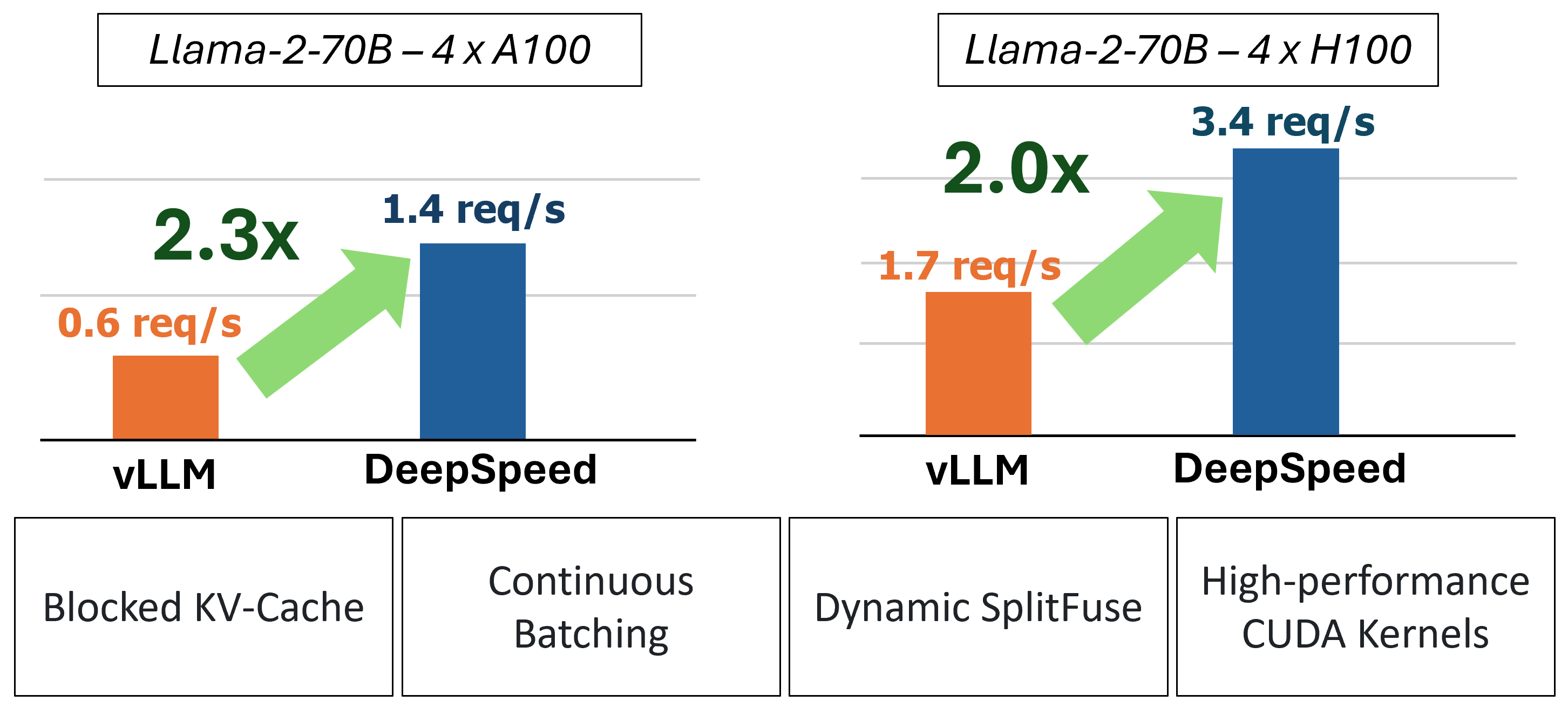
MIIは、4つの重要なテクノロジーを使用して、加速されたテキストジェネレーションの推論を提供します。
これらの機能をより深く理解するために、詳細なパフォーマンス分析も含むブログを参照してください。
過去に、MIIは低遅延のサービスシナリオのためのいくつかの重要なパフォーマンスの最適化を導入しました。
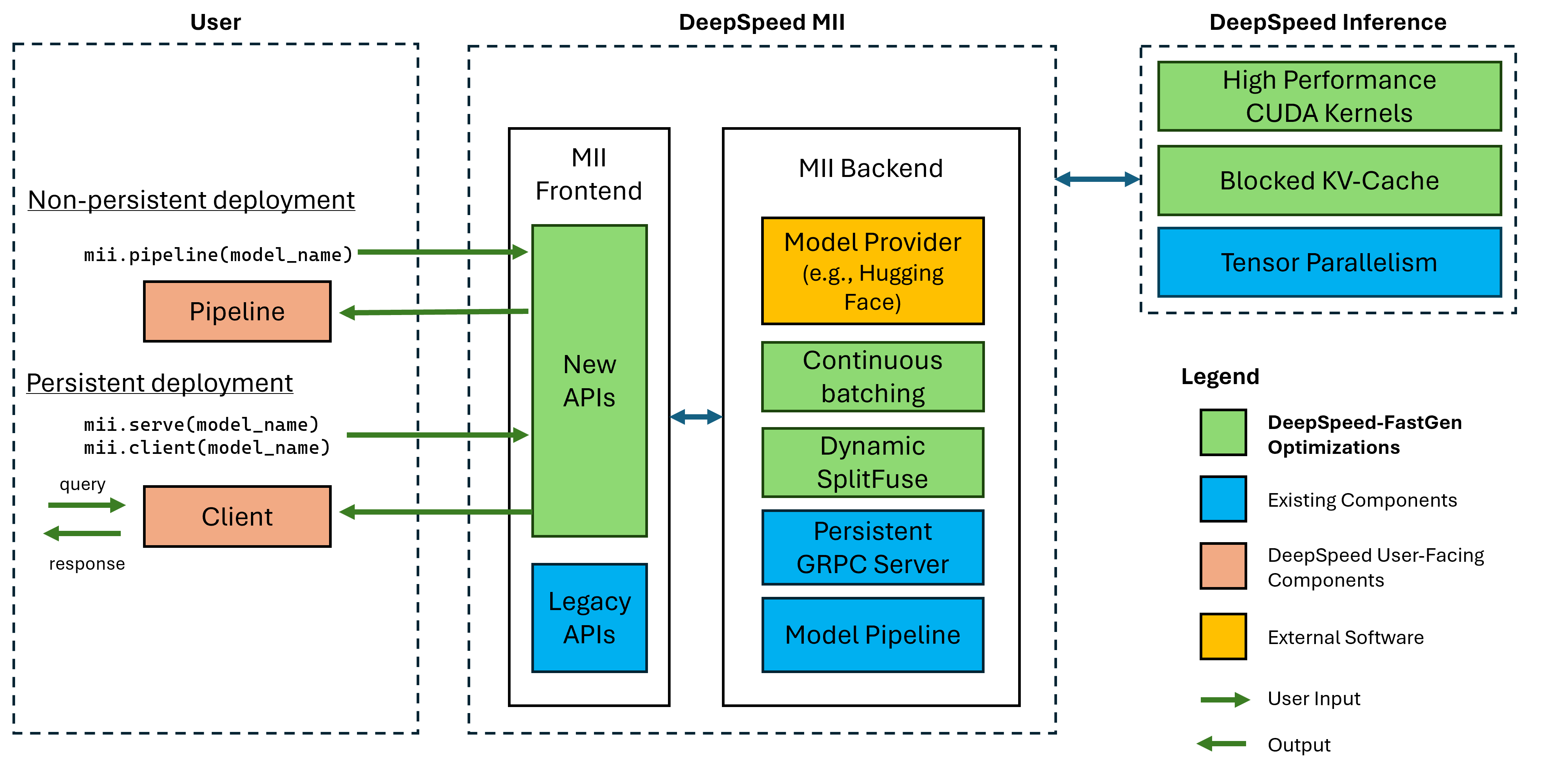
図1:MIIアーキテクチャ。MIIが展開する前にDS-Inferenceを使用してOSSモデルを自動的に最適化する方法を示しています。図のディープスピードファストの最適化は、ブログ投稿に掲載されています。
下部のMIIは、ディープスピードの推論によって駆動されます。モデルアーキテクチャ、モデルサイズ、バッチサイズ、利用可能なハードウェアリソースに基づいて、MIIは適切なシステム最適化セットを自動的に適用して、遅延を最小限に抑え、スループットを最大化します。
MIIは現在、8つの一般的なモデルアーキテクチャで37,000を超えるモデルをサポートしています。サポートしたい特定のモデルアーキテクチャがある場合は、問題を提出してお知らせください。すべての現在のモデルは、バックエンドでハグの顔を活用して、モデルの重みとモデルの対応するトークンザーの両方を提供します。現在のリリースでは、次のモデルアーキテクチャをサポートしています。
| モデルファミリー | サイズ範囲 | 〜モデル数 |
|---|---|---|
| ファルコン | 7b -180b | 600 |
| ラマ | 7b -65b | 57,000 |
| llama-2 | 7b -70b | 1,200 |
| llama-3 | 8b -405b | 1,600 |
| ミストラル | 7b | 23,000 |
| Mixtral(MOE) | 8x7b | 2,900 |
| Opt | 0.1b -66b | 2,200 |
| PHI-2 | 2.7b | 1,500 |
| Qwen | 7b -72b | 500 |
| QWEN2 | 0.5b -72b | 3700 |
MIIレガシーAPIは、Bert、Roberta、Stable Diffusion、Bloom、GPT-Jなどのその他のテキストジェネレーションモデルを含む50,000を超える異なるモデルをサポートしています。完全なリストについては、レガシーサポートモデルのテーブルをご覧ください。
DeepSpeed-MIIを使用すると、ユーザーはわずか数行のコードでサポートされているモデルの非密接で永続的な展開を作成できます。
開始するための最大の方法は、DeepSpeed-MIIのPYPIリリースです。つまり、数分以内に始めることができます。
pip install deepspeed-mii多くのプロジェクトがこのスペースで必要とする長期間のコンパイル時間の使いやすさと大幅な減少のために、私たちのカスタムカーネルの大部分をDeepSpeed-Kernelsという新しいライブラリを介してカスタムカーネルの大部分をカバーする事前にコンパイルされたPythonホイールを配布します。このライブラリは、コンピューティング機能8.0+(Ampere+)、Cuda 11.6+、およびUbuntu 20+を備えたNvidia GPUを備えた環境全体で非常にポータブルであることがわかりました。ほとんどの場合、このライブラリはdeepspeed-MIIの依存性であり、それにインストールされるため、このライブラリが存在することを知る必要さえありません。ただし、何らかの理由でカーネルを手動でコンパイルする必要がある場合は、高度なインストールドキュメントをご覧ください。
非密着性のあるパイプラインは、deepspeed-miiを試すのに最適な方法です。非特性パイプラインは、実行中のPythonスクリプトの期間中だけです。 Pipelineではないパイプラインの展開を実行するための完全な例は、わずか4行です。試してみてください!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response )返されたresponseは、 Responseオブジェクトのリストです。生成に関するいくつかの詳細にアクセスできます(例: response[0].prompt_length ):
generated_text: strテキスト。prompt_length: int元のプロンプトのトークンの数。generated_length: int生成されたトークンの数。finish_reason: str理由。 stop 、EOSトークンが生成され、 length max_new_tokensまたはmax_lengthに到達した生成を示します。デバイスメモリを解放してパイプラインを破壊する場合は、 destroy方法を使用します。
pipe . destroy ()MIIでは、パフォーマンスを向上させるためにマルチGPUシステムを利用することは簡単です。 deepspeed Launcherで実行すると、テンソル並列性は--num_gpusフラグによって自動的に制御されます。
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.py非特性パイプラインの展開を立てるには、モデル名またはパスのみが必要ですが、ユーザーにカスタマイズオプションを提供します。
mii.pipeline()オプション:
model_name_or_path: str名またはローカルパス。max_length: intプロンプト +応答のデフォルトの最大トークン長を設定します。all_rank_output: bool enabled、すべてのランクが生成されたテキストを返します。デフォルトでは、ランク0のみがテキストを返します。ユーザーは、次のオプションを使用して、個々のプロンプトの生成特性(つまり、 pipe()を呼び出すとき)の生成特性を制御することもできます。
max_length: intプロンプトごとの最大トークン長をプロンプト +応答に設定します。min_new_tokens: int応答で生成されるトークンの最小数を設定します。 max_length 、この設定よりも優先されます。max_new_tokens: int応答で生成されたトークンの最大数を設定します。ignore_eos: bool (デフォルトでFalse )設定がTrue設定により、EOSトークンが発生したときに発電が終了するのを防ぎます。1.0未満に設定すると、 top_p: float (デフォルトは0.9になります)、トークンをフィルタリングし、最も可能性のtop_pもののみを維持します。top_k: int (デフォルトはNone ) Noneで、top-kフィルタリングが無効になっている場合。設定すると、保持する最高の確率トークンの数。temperature: float (デフォルトはNone ) Noneで、温度が無効になっている場合。設定すると、トークンの確率を調整します。do_sample: bool (デフォルトはTrue ) Trueの場合、サンプル出力ロジット。 Falseの場合は、貪欲なサンプリングを使用します。return_full_text: bool (デフォルトはFalse ) Trueが、返されたテキストに入力プロンプトをプレイズする永続的な展開は、長期にわたる生産アプリケーションでの使用に最適です。永続的なモデルは、複数のクライアントが一度に照会できる軽量GRPCサーバーを使用します。永続的なモデルを実行するための完全な例は、わずか5行です。試してみてください!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response )返されたresponseは、 Responseオブジェクトのリストです。生成に関するいくつかの詳細にアクセスできます(例: response[0].prompt_length ):
generated_text: strテキスト。prompt_length: int元のプロンプトのトークンの数。generated_length: int生成されたトークンの数。finish_reason: str理由。 stop 、EOSトークンが生成され、 length max_new_tokensまたはmax_lengthに到達した生成を示します。他のプロセスからテキストを生成したい場合は、それもできます。
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )永続的な展開が不要になった場合、クライアントからサーバーをシャットダウンできます。
client . terminate_server ()マルチGPUシステムを利用して、より良いレイテンシとスループットを利用することも、永続的な展開で簡単です。モデルの並列性は、 mii.serveへのtensor_parallel inputによって制御されます。
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )結果の展開により、モデルが2 GPUに分割され、単一のGPUよりも高速な推論とより高いスループットが得られます。
また、複数のモデルレプリカをセットアップし、DeepSpeed-MIIが提供する負荷バランスを活用することにより、Multi-GPU(およびMulti-Node)システムを利用することもできます。
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )結果の展開は、2つのモデルインスタンス間の2つのモデルレプリカ(GPUごとに1つ)と負荷分散のリクエストをロードします。
モデルの並列性とレプリカを組み合わせて、より多くのGPUを備えたシステムを利用することもできます。以下の例では、2つのモデルレプリカを実行し、4つのGPUを持つシステム上で2つのGPUに分割されます。
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )モデルの並列性とモデルレプリカの選択は、最大のパフォーマンスのために、ハードウェア、モデル、およびワークロードの性質に依存します。たとえば、小さなモデルでは、ユーザーはモデルのレプリカがリクエストの平均レイテンシが最も低いことを発見する場合があります。一方、大規模なモデルは、モデルの並列性のみを使用すると、全体的なスループットが大きくなる場合があります。
MIIは、永続的なMII展開を作成するときにenable_restful_api=Trueを設定することにより、RESTFUL APIを介してモデルの推論を簡単に設定および実行できます。 RESTFUL APIはhttp://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME}でリクエストを受信できます。以下に完全な例を示します。
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ?注: deployment_nameを提供する必要はありません(MIIはあなたのためにそれを自動生成します)、正しいRESTFUL APIとのインターフェースを確保できるように、 deployment_nameを提供することをお勧めします。
その後、 curlなどのHTTPクライアントを使用して、Restful Gatewayにプロンプトを送信できます。
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deploymentまたはpython :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)永続的な展開を立てるにはモデル名またはパスのみが必要ですが、ユーザーにカスタマイズオプションを提供します。
mii.serve()オプション:
model_name_or_path: str (必須)huggingfaceモデルへの名前またはローカルパス。max_length: int (デフォルトはモデル構成の最大シーケンス長になります)プロンプト +応答のデフォルトの最大トークン長を設定します。deployment_name: str (デフォルトはf"{model_name_or_path}-mii-deployment" )永続的なモデルの一意の識別文字列。提供されている場合、クライアントオブジェクトはclient = mii.client(deployment_name)で取得する必要があります。tensor_parallel: int (defaults 1 )gpus数モデルを分割します。replica_num: int (デフォルトは1 )、立ち上がるモデルレプリカの数。enable_restful_api: bool (デフォルトはFalse )有効にすると、 http://{host}:{restful_api_port}/mii/{deployment_name}でクエリをかけることができるRESTFUL APIゲートウェイプロセスが起動されます。詳細については、Restful APIのセクションを参照してください。restful_api_port: int (デフォルトは28080に) enable_restful_apiがTrueに設定されている場合、Restful APIとのインターフェイスに使用されるポート番号。 mii.client()オプション:
model_or_deployment_name: str modelまたはdeployment_nameのstr名mii.serve()ユーザーは、次のオプションで個々のプロンプトの生成特性(つまり、 client.generate()を呼び出すとき)の生成特性を制御することもできます。
max_length: intプロンプトごとの最大トークン長をプロンプト +応答に設定します。min_new_tokens: int応答で生成されるトークンの最小数を設定します。 max_length 、この設定よりも優先されます。max_new_tokens: int応答で生成されたトークンの最大数を設定します。ignore_eos: bool ( TrueでFalse )設定は、EOSトークンに遭遇したときに発電が終了するのを防ぎます。1.0未満に設定すると、 top_p: float (デフォルトは0.9になります)、トークンをフィルタリングし、最も可能性のtop_pもののみを維持します。top_k: int (デフォルトはNone ) Noneで、top-kフィルタリングが無効になっている場合。設定すると、保持する最高の確率トークンの数。temperature: float (デフォルトはNone ) Noneで、温度が無効になっている場合。設定すると、トークンの確率を調整します。do_sample: bool (デフォルトはTrue ) Trueの場合、サンプル出力ロジット。 Falseの場合は、貪欲なサンプリングを使用します。return_full_text: bool (デフォルトはFalse ) Trueが、返されたテキストに入力プロンプトをプレイズするこのプロジェクトは、貢献と提案を歓迎します。ほとんどの貢献では、貢献者ライセンス契約(CLA)に同意する必要があります。詳細については、https://cla.opensource.microsoft.comをご覧ください。
プルリクエストを送信すると、CLAボットはCLAを提供し、PRを適切に飾る必要があるかどうかを自動的に決定します(たとえば、ステータスチェック、コメント)。ボットが提供する指示に従うだけです。 CLAを使用して、すべてのレポでこれを1回だけ行う必要があります。
このプロジェクトは、Microsoftのオープンソース行動規範を採用しています。詳細については、FAQのコードを参照するか、追加の質問やコメントについては[email protected]にお問い合わせください。
このプロジェクトには、プロジェクト、製品、またはサービスの商標またはロゴが含まれる場合があります。 Microsoftの商標またはロゴの承認された使用は、Microsoftの商標およびブランドガイドラインに従うものであり、従わなければなりません。このプロジェクトの変更されたバージョンでのMicrosoft商標またはロゴの使用は、混乱を引き起こしたり、Microsoftのスポンサーシップを暗示したりしてはなりません。サードパーティの商標またはロゴの使用は、これらのサードパーティのポリシーの対象となります。


