DeepSpeed MII
v0.3.1





Представляя MII, библиотеку Python с открытым исходным кодом, разработанную DeepSpeed для демократизации мощного модельного вывода с акцентом на высокопроизводительную, низкую задержку и экономическую эффективность.
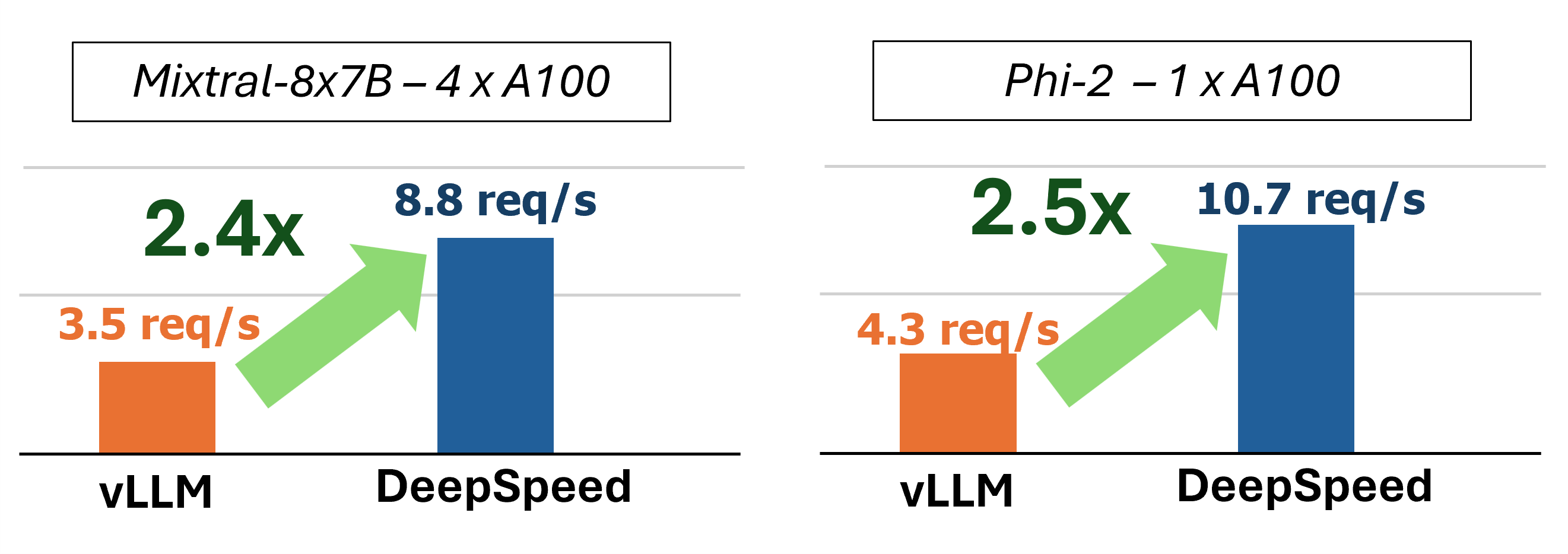
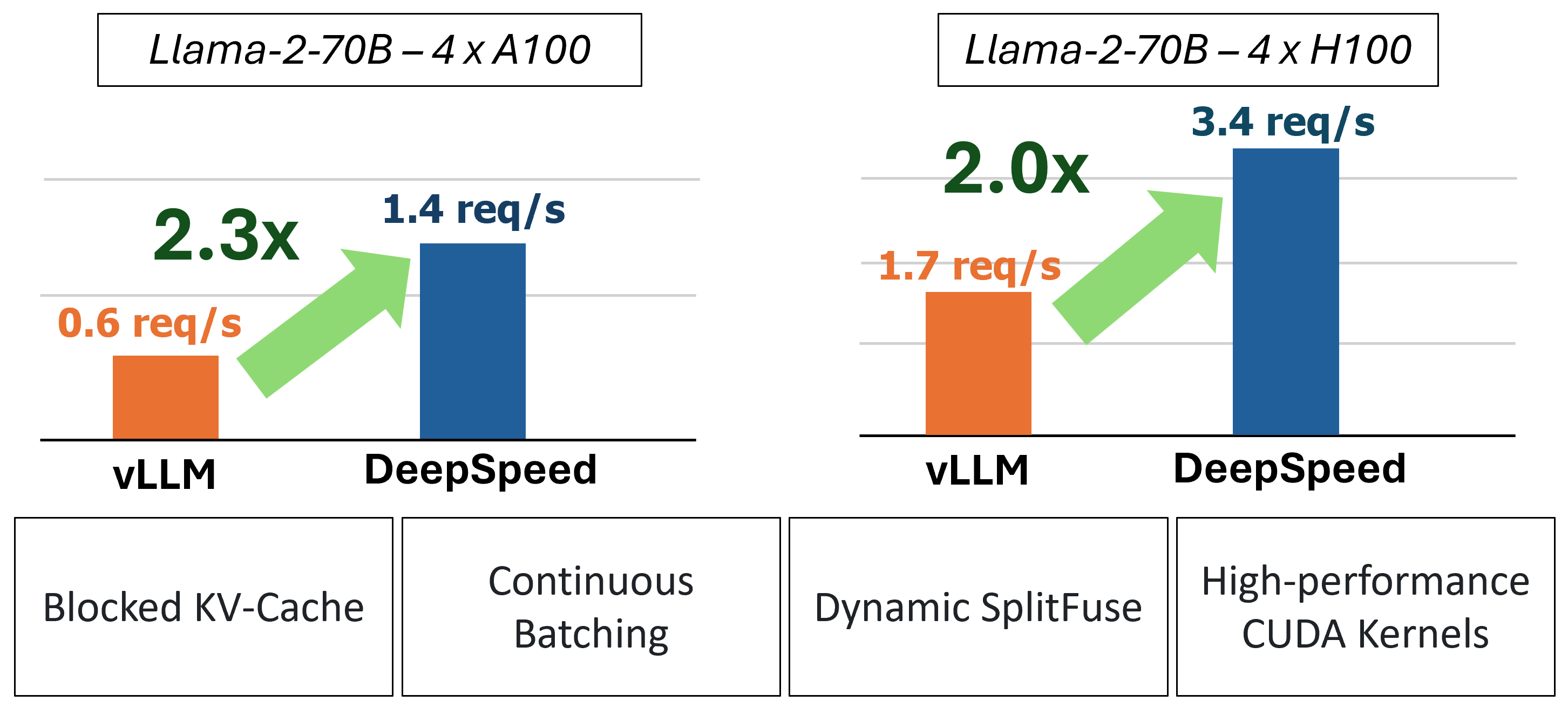
MII обеспечивает ускоренный вывод генерации текста посредством использования четырех ключевых технологий:
Для более глубокого погружения в понимание этих функций, пожалуйста, обратитесь к нашему блогу, который также включает подробный анализ производительности.
В прошлом MII вводил несколько ключевых оптимизаций производительности для сценариев обслуживания с низкой задержкой:
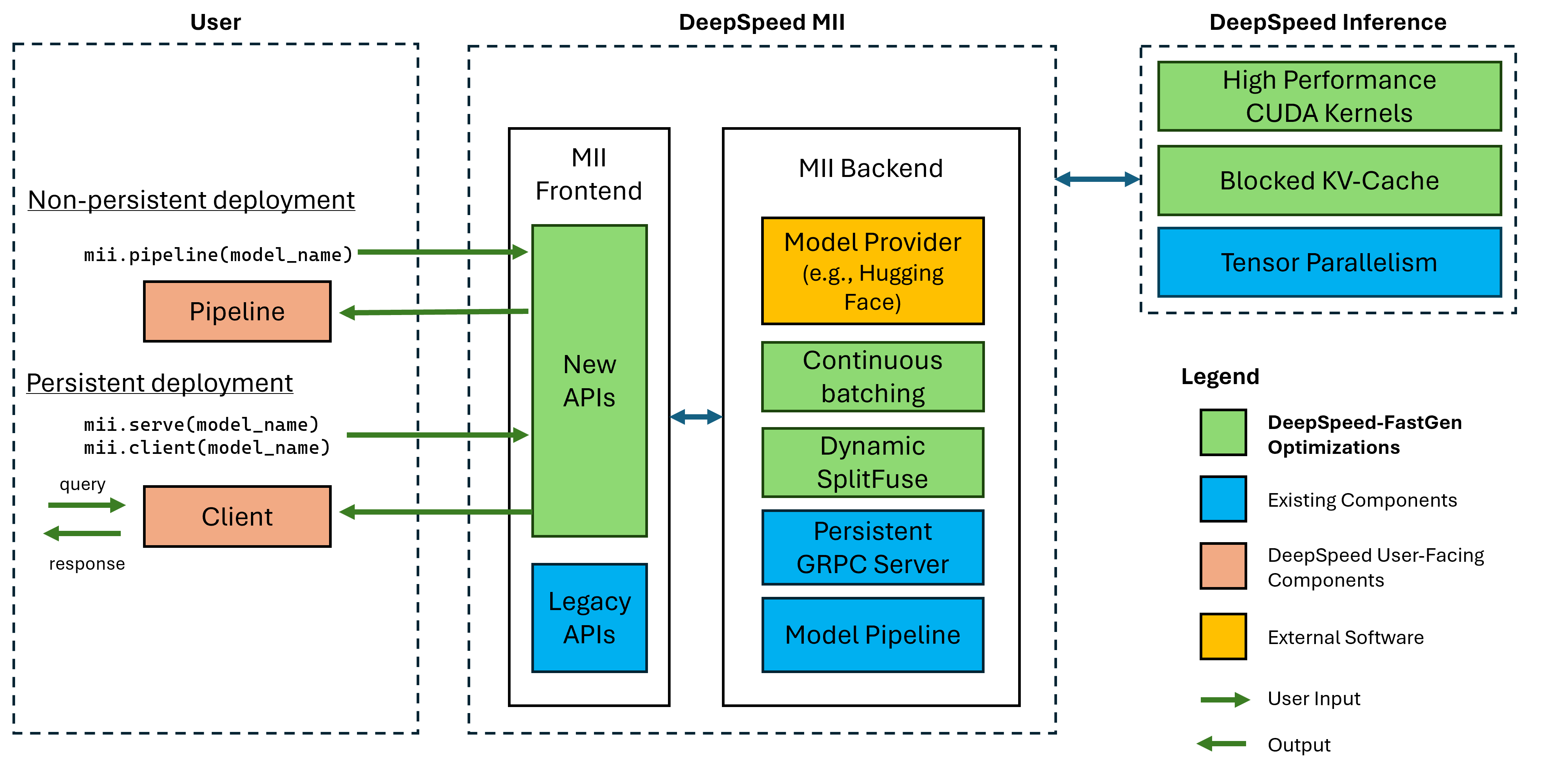
Рисунок 1: Архитектура MII, показывающая, как MII автоматически оптимизирует модели OSS с использованием DS-Inference перед их развертыванием. DeepSpeed-Fastgen оптимизация на рисунке была опубликована в нашем сообщении в блоге.
MII под рукой приводится в действие DeepSpeed Inference. На основе архитектуры модели, размера модели, размера партии и доступных аппаратных ресурсов MII автоматически применяет соответствующий набор оптимизаций системы, чтобы минимизировать задержку и максимизировать пропускную способность.
В настоящее время MII поддерживает более 37 000 моделей в восьми популярных модельных архитектурах. Мы планируем добавить дополнительные модели в ближайшей перспективе, если есть конкретные модели архитектуры, которые вы хотите поддерживать, пожалуйста, подайте проблему и сообщите нам об этом. Все текущие модели используют обнимающееся лицо в нашем бэкэнде, чтобы обеспечить как веса модели, так и соответствующий токенизатор модели. Для нашего текущего выпуска мы поддерживаем следующие архитектуры модели:
| модель семьи | Размер диапазона | ~ Модели подсчет |
|---|---|---|
| Сокол | 7b - 180b | 600 |
| Лама | 7b - 65b | 57 000 |
| Лама-2 | 7b - 70b | 1200 |
| Лама-3 | 8b - 405b | 1600 |
| Мистраль | 7b | 23 000 |
| Миктральный (MOE) | 8x7b | 2900 |
| Опт | 0,1b - 66b | 2200 |
| Phi-2 | 2.7b | 1500 |
| Qwen | 7b - 72b | 500 |
| QWEN2 | 0,5B - 72B | 3700 |
MII Legacy API поддерживают более 50 000 различных моделей, включая Bert, Roberta, стабильную диффузию и другие модели генерации текста, такие как Bloom, GPT-J и т. Д. Для полного списка, пожалуйста, см. Наша таблица модели с поддержанными устаревшим.
DeepSpeed-MII позволяет пользователям создавать непрерывные и постоянные развертывания для поддерживаемых моделей всего за несколько строк кода.
Большой способ начать работу-это наш выпуск PYPI DeepSpeed-MII, что означает, что вы можете начать через несколько минут через:
pip install deepspeed-miiДля простоты использования и значительного сокращения длительного времени компиляции, которые требуются во многих проектах в этом пространстве, мы распространяем предварительно скомпилированное колесо Python, охватывающее большинство наших пользовательских ядер через новую библиотеку под названием DeepSpeed-Kernels. Мы обнаружили, что эта библиотека была очень портативной в разных средах с графическими процессорами NVIDIA с возможностями вычислительных возможностей 8.0+ (AMPERE+), CUDA 11.6+ и Ubuntu 20+. В большинстве случаев вам даже не нужно знать, что эта библиотека существует, поскольку она является зависимостью DeepSpeed-MII и будет установлена с ней. Однако, если по какой -то причине вам нужно скомпилировать наши ядра вручную, пожалуйста, посмотрите наши расширенные документы по установке.
Непостоянный трубопровод-отличный способ попробовать DeepSpeed-MII. Неустойчивые трубопроводы находятся вокруг только на время сценария Python, который вы запускаете. Полный пример запуска непрерывного развертывания трубопровода составляет всего 4 строки. Попробуйте!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) Возвращенный response - это список объектов Response . Мы можем получить доступ к нескольким подробностям о генерации (например, response[0].prompt_length ):
generated_text: str Текст, сгенерированный моделью.prompt_length: int Количество токенов в исходном приглашении.generated_length: int Количество сгенерированных токенов.finish_reason: str Причина остановки поколения. stop указывает, что токен EOS был сгенерирован, а length указывает, что генерация достигла max_new_tokens или max_length . Если вы хотите освободить память устройства и уничтожить трубопровод, используйте метод destroy :
pipe . destroy () Использовать преимущества систем с несколькими GPU для большей производительности легко с MII. При запуске с помощью запуска deepspeed параллелизм тензора автоматически контролируется флагом --num_gpus :
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pyВ то время как только имя или путь модели требуется для выдержки непрерывного развертывания трубопровода, мы предлагаем параметры настройки нашим пользователям:
mii.pipeline() Параметры :
model_name_or_path: str или локальный путь к модели HuggingFace.max_length: int устанавливает максимальную длину токена по умолчанию для ответа на запрос +.all_rank_output: bool При включении все ранги возвращают сгенерированный текст. По умолчанию только ранг 0 вернет текст. Пользователи также могут контролировать характеристики генерации для отдельных подсказок (т.е. при вызове pipe() ) со следующими параметрами:
max_length: int устанавливает максимальную длину токена для Per-Prompt для запроса + ответ.min_new_tokens: int устанавливает минимальное количество токенов, генерируемых в ответе. max_length будет иметь приоритет над этой настройкой.max_new_tokens: int устанавливает максимальное количество токенов, сгенерированных в ответе.ignore_eos: bool (по умолчанию к False ) настройка в True предотвращает окончание генерации, когда встречается токен EOS.top_p: float (по умолчанию до 0.9 ), когда установлен ниже 1.0 , фильтруйте токены и сохраняют только наиболее вероятные, где вероятности токена суммируются до ≥ top_p .top_k: int (по умолчанию None ), когда None , фильтрация Top-K отключена. При установке количество токенов с наибольшей вероятностью сохраняется.temperature: float (по умолчанию None ). Когда None , температура отключена. При установке модулирует вероятности токена.do_sample: bool (по умолчанию True ), когда True , выборки вывода. Когда False используйте жадную выборку.return_full_text: bool (по умолчанию False ). Когда True приготовляет подсказку ввода к возвращенному тексту Постоянное развертывание идеально подходит для использования с продолжительными и производственными приложениями. Постоянная модель использует легкий сервер GRPC, который можно попросить несколькими клиентами одновременно. Полный пример для запуска постоянной модели составляет всего 5 строк. Попробуйте!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) Возвращенный response - это список объектов Response . Мы можем получить доступ к нескольким подробностям о генерации (например, response[0].prompt_length ):
generated_text: str Текст, сгенерированный моделью.prompt_length: int Количество токенов в исходном приглашении.generated_length: int Количество сгенерированных токенов.finish_reason: str Причина остановки поколения. stop указывает, что токен EOS был сгенерирован, а length указывает, что генерация достигла max_new_tokens или max_length .Если мы хотим генерировать текст из других процессов, мы тоже можем это сделать:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )Когда нам больше не нужно постоянное развертывание, мы можем отключить сервер от любого клиента:
client . terminate_server () Использовать преимущества систем с несколькими GPU для лучшей задержки и пропускной способности также легко с постоянными развертываниями. Модель параллелизма контролируется вводом tensor_parallel в mii.serve :
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )Полученное развертывание развертывает модель на 2 графических процессорах, чтобы сделать более быстрый вывод и более высокую пропускную способность, чем один графический процессор.
Мы также можем воспользоваться преимуществами систем с несколькими GPU (и мультизлузом), настроив несколько реплик модели и воспользовавшись балансировкой нагрузки, которую обеспечивает DeepSpeed-MII:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )Полученное развертывание будет загружать 2 модели модели (одна на графический процессор) и входящие запросы с балансом нагрузки между двумя экземплярами модели.
Модель параллелизма и реплики также могут быть объединены, чтобы воспользоваться преимуществами систем с большим количеством графических процессоров. В приведенном ниже примере мы запускаем 2 модели модели, каждая из которых разделена на 2 графических процессора на системе с 4 графическими процессорами:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )Выбор между параллелизмом модели и модельными репликами для максимальной производительности будет зависеть от природы оборудования, модели и рабочей нагрузки. Например, с небольшими моделями пользователи могут обнаружить, что модели реплики обеспечивают самую низкую среднюю задержку для запросов. Между тем, крупные модели могут достичь большей общей пропускной способности при использовании только параллелизма модели.
MII позволяет легко настроить и запустить вывод модели с помощью API RESTFUL, установив enable_restful_api=True при создании постоянного развертывания MII. API RESTFUL может получать запросы по адресу http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} . Полный пример приведен ниже:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ? Примечание. Хотя предоставление deployment_name не требуется (MII будет автогеномствовать один для вас), это хорошая практика для предоставления deployment_name , чтобы вы могли убедиться, что вы взаимодействуете с правильным RESTFUL API.
Затем вы можете отправить подсказки в Retfful Gateway с любым HTTP -клиентом, таким как curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment или python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)В то время как для выдержания постоянного развертывания требуется только имя модели или путь, мы предлагаем параметры настройки нашим пользователям.
mii.serve() Варианты :
model_name_or_path: str (требуется) Имя или локальный путь к модели HuggingFace.max_length: int (по умолчанию в максимальную длину последовательности в конфигурации модели) Устанавливает максимальную длину токена по умолчанию для ответа на подсказку +.deployment_name: str (по умолчанию к f"{model_name_or_path}-mii-deployment" ) уникальная идентификационная строка для постоянной модели. Если предоставлены, клиентские объекты должны быть извлечены с помощью client = mii.client(deployment_name) .tensor_parallel: int (по умолчанию 1 ) количество графических процессоров, чтобы разделить модель через.replica_num: int (по умолчанию 1 ) количество модельных реплик, чтобы встать.enable_restful_api: bool (по умолчанию False ) Когда включено, запускается процесс Geatway Restful API, который можно запрашивать по адресу http://{host}:{restful_api_port}/mii/{deployment_name} . Смотрите раздел об API RESTFUL для более подробной информации.restful_api_port: int (по умолчанию в 28080 ) Номер порта, используемый для взаимодействия с RESTFUL API, когда enable_restful_api установлен на True . mii.client() Варианты :
model_or_deployment_name: str Имя модели mii.serve() deployment_name Пользователи также могут контролировать характеристики генерации для отдельных подсказок (т.е. при вызове client.generate() ) со следующими параметрами:
max_length: int устанавливает максимальную длину токена для Per-Prompt для запроса + ответ.min_new_tokens: int устанавливает минимальное количество токенов, генерируемых в ответе. max_length будет иметь приоритет над этой настройкой.max_new_tokens: int устанавливает максимальное количество токенов, сгенерированных в ответе.ignore_eos: bool (по умолчанию к False ) настройка в True предотвращает окончание генерации, когда встречается токен EOS.top_p: float (по умолчанию до 0.9 ), когда установлен ниже 1.0 , фильтруйте токены и сохраняют только наиболее вероятные, где вероятности токена суммируются до ≥ top_p .top_k: int (по умолчанию None ), когда None , фильтрация Top-K отключена. При установке количество токенов с наибольшей вероятностью сохраняется.temperature: float (по умолчанию None ). Когда None , температура отключена. При установке модулирует вероятности токена.do_sample: bool (по умолчанию True ), когда True , выборки вывода. Когда False используйте жадную выборку.return_full_text: bool (по умолчанию False ). Когда True приготовляет подсказку ввода к возвращенному текстуЭтот проект приветствует вклады и предложения. Большинство взносов требуют, чтобы вы согласились с лицензионным соглашением о участнике (CLA), заявив, что вы имеете право и фактически предоставить нам права на использование вашего вклада. Для получения подробной информации, посетите https://cla.opensource.microsoft.com.
Когда вы отправляете запрос на привлечение, бот CLA автоматически определит, нужно ли вам предоставить CLA и правильно украсить PR (например, проверка состояния, комментарий). Просто следуйте инструкциям, предоставленным ботом. Вам нужно будет сделать это только один раз во всех репо, используя наш CLA.
Этот проект принял код поведения с открытым исходным кодом Microsoft. Для получения дополнительной информации см. Кодекс поведения FAQ или свяжитесь с [email protected] с любыми дополнительными вопросами или комментариями.
Этот проект может содержать товарные знаки или логотипы для проектов, продуктов или услуг. Уполномоченное использование товарных знаков или логотипов Microsoft подлежит и должно следовать указаниям Microsoft по товарной марке и брендам. Использование товарных знаков Microsoft или логотипов в модифицированных версиях этого проекта не должно вызывать путаницу или подразумевать спонсорство Microsoft. Любое использование сторонних товарных знаков или логотипов подвержена политике сторонних сторон.


