DeepSpeed MII
v0.3.1





Presentamos a MII, una biblioteca de Python de código abierto diseñada por Deepeed para democratizar una poderosa inferencia modelo con un enfoque en el alto rendimiento, la baja latencia y la rentabilidad.
MII proporciona una inferencia de generación de texto acelerada mediante el uso de cuatro tecnologías clave:
Para obtener una inmersión más profunda para comprender estas características, consulte nuestro blog que también incluye un análisis de rendimiento detallado.
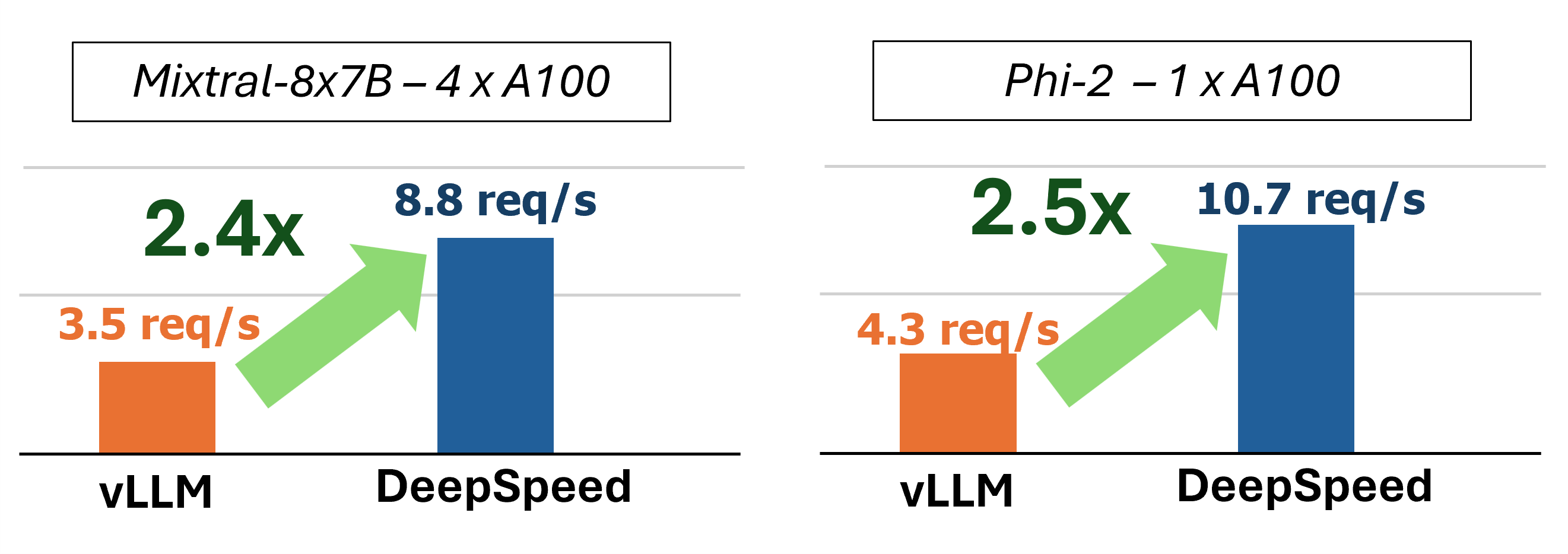
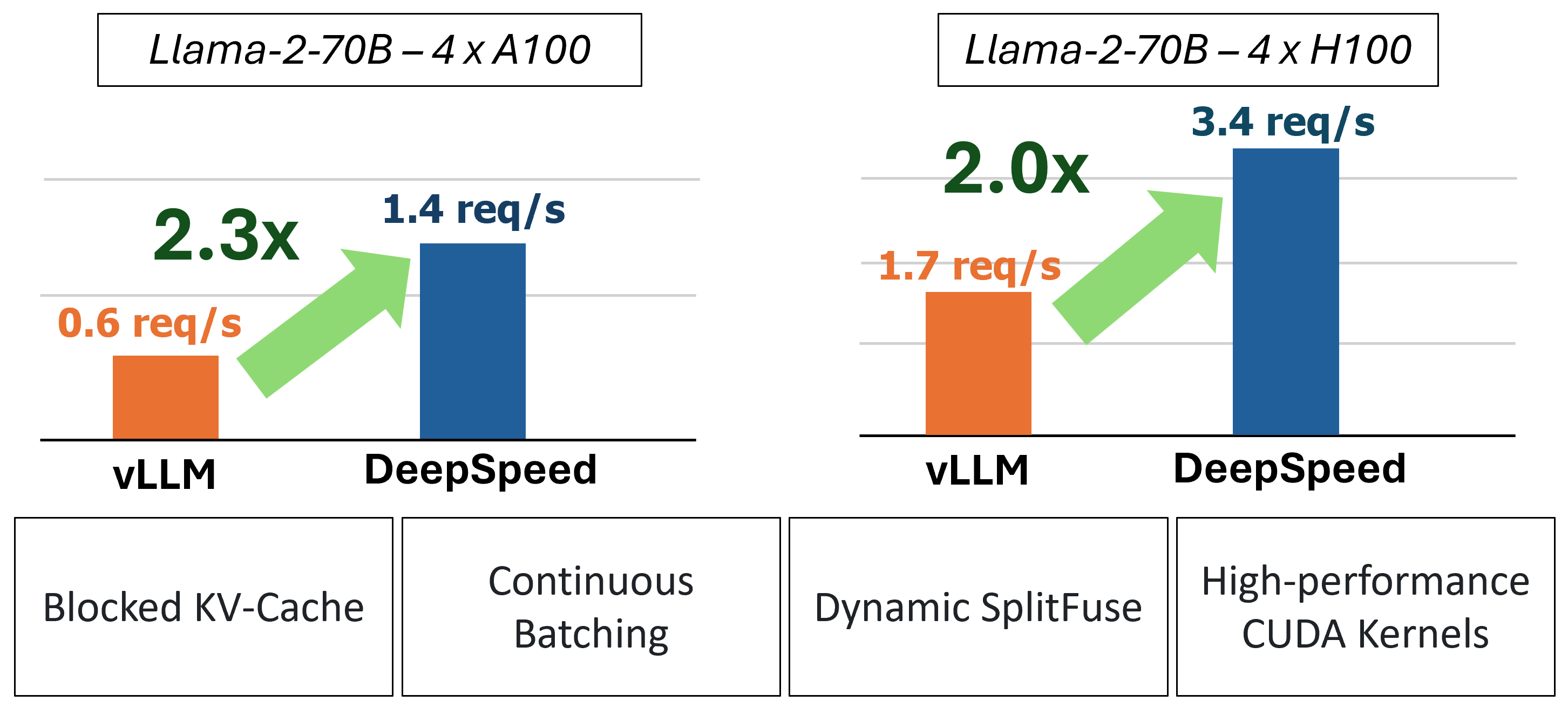
En el pasado, MII introdujo varias optimizaciones clave de rendimiento para escenarios de servicios de baja latencia:
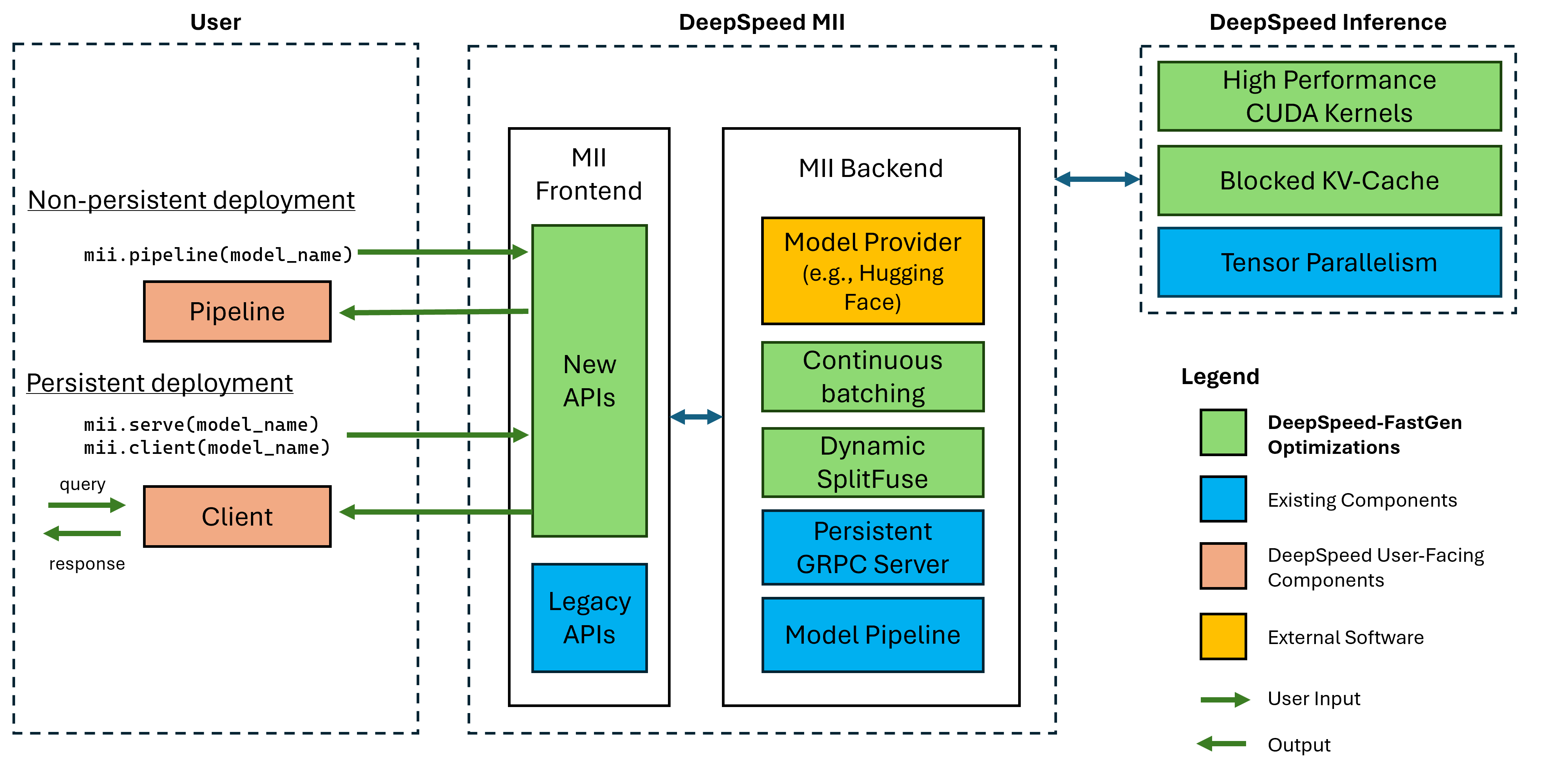
Figura 1: Arquitectura de MII, que muestra cómo MII optimiza automáticamente los modelos OSS utilizando la inferencia DS antes de implementarlos. Las optimizaciones de Deepeed-Fastgen en la figura se han publicado en nuestra publicación de blog.
MII bajo el capado Mii está impulsado por la inferencia de la velocidad profunda. Según la arquitectura del modelo, el tamaño del modelo, el tamaño del lote y los recursos de hardware disponibles, MII aplica automáticamente el conjunto apropiado de optimizaciones del sistema para minimizar la latencia y maximizar el rendimiento.
Actualmente, MII admite más de 37,000 modelos en ocho arquitecturas de modelos populares. Planeamos agregar modelos adicionales en el corto plazo, si hay arquitecturas de modelos específicas que desea que compatible, presenten un problema y háganoslo saber. Todos los modelos actuales aprovechan la cara abrazada en nuestro backend para proporcionar los pesos del modelo y el tokenizador correspondiente del modelo. Para nuestro lanzamiento actual, admitemos las siguientes arquitecturas del modelo:
| familia modelo | rango de tamaño | ~ recuento de modelos |
|---|---|---|
| Halcón | 7b - 180b | 600 |
| Llama | 7b - 65b | 57,000 |
| Llama-2 | 7b - 70b | 1.200 |
| LLAMA-3 | 8b - 405b | 1.600 |
| Mistral | 7b | 23,000 |
| Mixtral (Moe) | 8x7b | 2.900 |
| OPTAR | 0.1b - 66b | 2.200 |
| Phi-2 | 2.7b | 1.500 |
| Qwen | 7b - 72b | 500 |
| Qwen2 | 0.5b - 72b | 3700 |
Las API Legacy MII admiten más de 50,000 modelos diferentes, incluidos Bert, Roberta, Difusión estable y otros modelos de generación de texto como Bloom, GPT-J, etc. para una lista completa, consulte nuestra tabla de modelos compatibles con Legacy.
Deepspeed-MII permite a los usuarios crear implementaciones no persistentes y persistentes para modelos compatibles en solo unas pocas líneas de código.
La forma más importante de comenzar es con nuestra liberación de PYPI de Deepspeed-Mii, lo que significa que puede comenzar en cuestión de minutos a través de:
pip install deepspeed-miiPara facilitar el uso y una reducción significativa en los largos tiempos de compilación que requieren muchos proyectos en este espacio, distribuimos una rueda de pitón precompilada que cubre la mayoría de nuestros núcleos personalizados a través de una nueva biblioteca llamada Kernels de velocidad profunda. Hemos encontrado que esta biblioteca es muy portátil en entornos con GPU NVIDIA con capacidades de cálculo 8.0+ (Ampere+), CUDA 11.6+ y Ubuntu 20+. En la mayoría de los casos, ni siquiera debe necesitar saber que esta biblioteca existe, ya que es una dependencia de DeepSpeed-Mii y se instalará con ella. Sin embargo, si por alguna razón necesita compilar nuestros núcleos manualmente, consulte nuestros documentos de instalación avanzados.
Una tubería no persistente es una excelente manera de probar Deepspeed-Mii. Las tuberías no persistentes están solo por la duración del script de Python que está ejecutando. El ejemplo completo para ejecutar una implementación de tuberías no persistente es de solo 4 líneas. ¡Probar!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) La response devuelta es una lista de objetos Response . Podemos acceder a varios detalles sobre la generación (por ejemplo, response[0].prompt_length ):
generated_text: str generado por el modelo.prompt_length: int número de tokens en el mensaje original.generated_length: int número de tokens generados.finish_reason: str para detener la generación. stop indica que se generó el token EOS y length indica que la generación alcanzó max_new_tokens o max_length . Si desea liberar la memoria del dispositivo y destruir la tubería, use el método destroy :
pipe . destroy () Aprovechar los sistemas de múltiples GPU para un mayor rendimiento es fácil con MII. Cuando se ejecuta con el lanzador deepspeed , el paralelismo tensor se controla automáticamente por el indicador --num_gpus :
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pySi bien solo se requiere el nombre o ruta del modelo para soportar una implementación de tuberías no persistente, ofrecemos opciones de personalización a nuestros usuarios:
mii.pipeline() Opciones :
model_name_or_path: str o ruta local a un modelo Huggingface.max_length: int establece la longitud de token máxima predeterminada para la solicitud + respuesta.all_rank_output: bool Cuando está habilitado, todos los rangos devuelven el texto generado. Por defecto, solo el rango 0 devolverá el texto. Los usuarios también pueden controlar las características de generación para indicaciones individuales (es decir, cuando llaman pipe() ) con las siguientes opciones:
max_length: int establece la longitud de token máxima por prompt para la respuesta + respuesta.min_new_tokens: int establece el número mínimo de tokens generados en la respuesta. max_length tendrá prioridad sobre esta configuración.max_new_tokens: int establece el número máximo de tokens generados en la respuesta.ignore_eos: bool (predeterminado a False ) La configuración de True evita que la generación finalice cuando se encuentra el token EOS.top_p: float (predeterminado es 0.9 ) Cuando se establece por debajo de 1.0 , filtra tokens y mantiene solo las más probables, donde las probabilidades de tokens suma a ≥ top_p .top_k: int (predeterminado a None ) Cuando None , el filtrado de Top-K está deshabilitado. Cuando se establece, el número de tokens de mayor probabilidad para mantener.temperature: float (predeterminado None ) Cuando None , la temperatura está deshabilitada. Cuando se establece, modula las probabilidades de token.do_sample: bool (predeterminado es True ) Cuando True , muestra los registros de salida. Cuando sea False , use muestreo codicioso.return_full_text: bool (predeterminado a False ) Cuando es True , prepida el indicador de entrada al texto devuelto Una implementación persistente es ideal para su uso con aplicaciones de larga duración y producción. El modelo persistente utiliza un servidor GRPC ligero que puede ser consultado por varios clientes a la vez. El ejemplo completo para ejecutar un modelo persistente es de solo 5 líneas. ¡Probar!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) La response devuelta es una lista de objetos Response . Podemos acceder a varios detalles sobre la generación (por ejemplo, response[0].prompt_length ):
generated_text: str generado por el modelo.prompt_length: int número de tokens en el mensaje original.generated_length: int número de tokens generados.finish_reason: str para detener la generación. stop indica que se generó el token EOS y length indica que la generación alcanzó max_new_tokens o max_length .Si queremos generar texto de otros procesos, también podemos hacerlo:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )Cuando ya no necesitamos una implementación persistente, podemos cerrar el servidor de cualquier cliente:
client . terminate_server () Aprovechar los sistemas de múltiples GPU para una mejor latencia y rendimiento también es fácil con las implementaciones persistentes. El paralelismo del modelo está controlado por la entrada tensor_parallel a mii.serve :
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )La implementación resultante dividirá el modelo en 2 GPU para ofrecer una inferencia más rápida y un rendimiento más alto que una sola GPU.
También podemos aprovechar los sistemas de múltiples GPU (y múltiples nodos) configurando múltiples réplicas de modelo y aprovechando el equilibrio de carga que proporciona DeepSpeed-Mii:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )La implementación resultante cargará 2 réplicas modelo (una por GPU) y las solicitudes entrantes de equilibrio de carga entre las 2 instancias modelo.
El paralelismo modelo y las réplicas también se pueden combinar para aprovechar los sistemas con muchos más GPU. En el ejemplo a continuación, ejecutamos 2 réplicas modelo, cada una dividida en 2 GPU en un sistema con 4 GPU:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )La elección entre el paralelismo del modelo y las réplicas del modelo para el máximo rendimiento dependerá de la naturaleza del hardware, el modelo y la carga de trabajo. Por ejemplo, con los modelos pequeños, los usuarios pueden encontrar que las réplicas del modelo proporcionan la latencia promedio más baja para las solicitudes. Mientras tanto, los modelos grandes pueden lograr un mayor rendimiento general al usar solo el paralelismo del modelo.
MII facilita la configuración y ejecuta la inferencia del modelo a través de API RESTFUL al enable_restful_api=True al crear una implementación de MII persistente. La API Restful puede recibir solicitudes en http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} . A continuación se proporciona un ejemplo completo:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ? Nota: Si bien no es necesario proporcionar un deployment_name (Mii se autogeneizará uno para usted), es una buena práctica proporcionar una deployment_name para que pueda asegurarse de interactuar con la API RESTFOR correcta.
Luego puede enviar indicaciones a Restful Gateway con cualquier cliente HTTP, como curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment o python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)Si bien solo se requiere el nombre o ruta del modelo para defender una implementación persistente, ofrecemos opciones de personalización a nuestros usuarios.
mii.serve() Opciones :
model_name_or_path: str (requerido) Nombre o ruta local a un modelo Huggingface.max_length: int (predeterminado a la longitud de secuencia máxima en la configuración del modelo) establece la longitud de token máxima predeterminada para la respuesta + respuesta.deployment_name: str (predeterminado a f"{model_name_or_path}-mii-deployment" ) una cadena de identificación única para el modelo persistente. Si se proporciona, los objetos del cliente deben recuperarse con client = mii.client(deployment_name) .tensor_parallel: int (predeterminado es 1 ) número de GPU para dividir el modelo.replica_num: int (predeterminado es 1 ) el número de réplicas del modelo para ponerse de pie.enable_restful_api: bool (predeterminado a False ) Cuando se habilita, se inicia un proceso de puerta de enlace API RESTFUL que se puede consultar en http://{host}:{restful_api_port}/mii/{deployment_name} . Consulte la sección sobre API RESTful para obtener más detalles.restful_api_port: int (predeterminado a 28080 ) el número de puerto utilizado para interactuar con la API RESTFUL cuando enable_restful_api se establece en True . mii.client() Opciones :
model_or_deployment_name: str del modelo o deployment_name pasado a mii.serve() Los usuarios también pueden controlar las características de generación para indicaciones individuales (es decir, cuando llaman client.generate() ) con las siguientes opciones:
max_length: int establece la longitud de token máxima por prompt para la respuesta + respuesta.min_new_tokens: int establece el número mínimo de tokens generados en la respuesta. max_length tendrá prioridad sobre esta configuración.max_new_tokens: int establece el número máximo de tokens generados en la respuesta.ignore_eos: bool (predeterminado a False ) La configuración de True evita que la generación finalice cuando se encuentra el token EOS.top_p: float (predeterminado es 0.9 ) Cuando se establece por debajo de 1.0 , filtra tokens y mantiene solo las más probables, donde las probabilidades de tokens suma a ≥ top_p .top_k: int (predeterminado a None ) Cuando None , el filtrado de Top-K está deshabilitado. Cuando se establece, el número de tokens de mayor probabilidad para mantener.temperature: float (predeterminado None ) Cuando None , la temperatura está deshabilitada. Cuando se establece, modula las probabilidades de token.do_sample: bool (predeterminado es True ) Cuando True , muestra los registros de salida. Cuando sea False , use muestreo codicioso.return_full_text: bool (predeterminado a False ) Cuando es True , prepida el indicador de entrada al texto devueltoEste proyecto da la bienvenida a las contribuciones y sugerencias. La mayoría de las contribuciones requieren que acepte un Acuerdo de Licencia de Contributor (CLA) que declare que tiene derecho y realmente hacernos los derechos para utilizar su contribución. Para más detalles, visite https://cla.opensource.microsoft.com.
Cuando envíe una solicitud de extracción, un BOT CLA determinará automáticamente si necesita proporcionar un CLA y decorar el PR adecuadamente (por ejemplo, verificación de estado, comentario). Simplemente siga las instrucciones proporcionadas por el bot. Solo necesitará hacer esto una vez en todos los reposos usando nuestro CLA.
Este proyecto ha adoptado el Código de Conducta Open Open Microsoft. Para obtener más información, consulte el Código de Conducta Preguntas frecuentes o comuníquese con [email protected] con cualquier pregunta o comentario adicional.
Este proyecto puede contener marcas comerciales o logotipos para proyectos, productos o servicios. El uso autorizado de marcas o logotipos de Microsoft está sujeto y debe seguir las pautas de marca y marca de Microsoft. El uso de marcas registradas de Microsoft o logotipos en versiones modificadas de este proyecto no debe causar confusión o implicar el patrocinio de Microsoft. Cualquier uso de marcas comerciales o logotipos de terceros está sujeto a las políticas de esas partes de terceros.


