DeepSpeed MII
v0.3.1





由DeepSpeed设计的开源Python图书馆MII介绍MII,旨在使强大的模型推断民主化,重点是高通量,低潜伏期和成本效益。
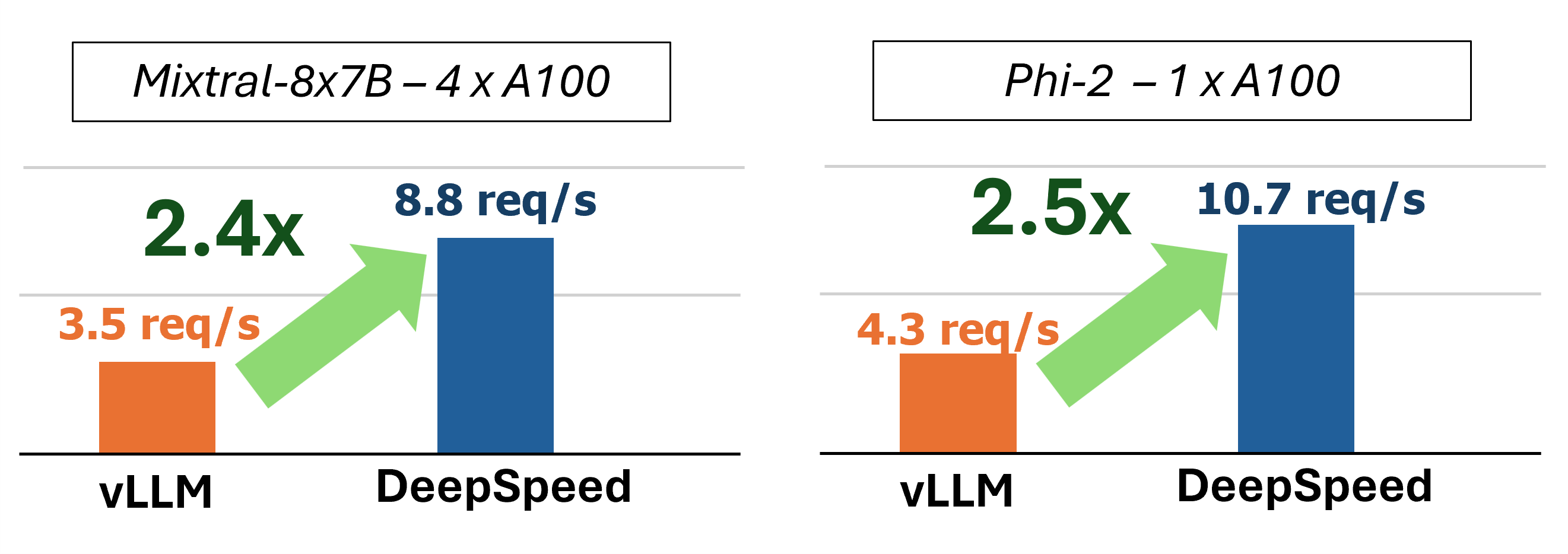
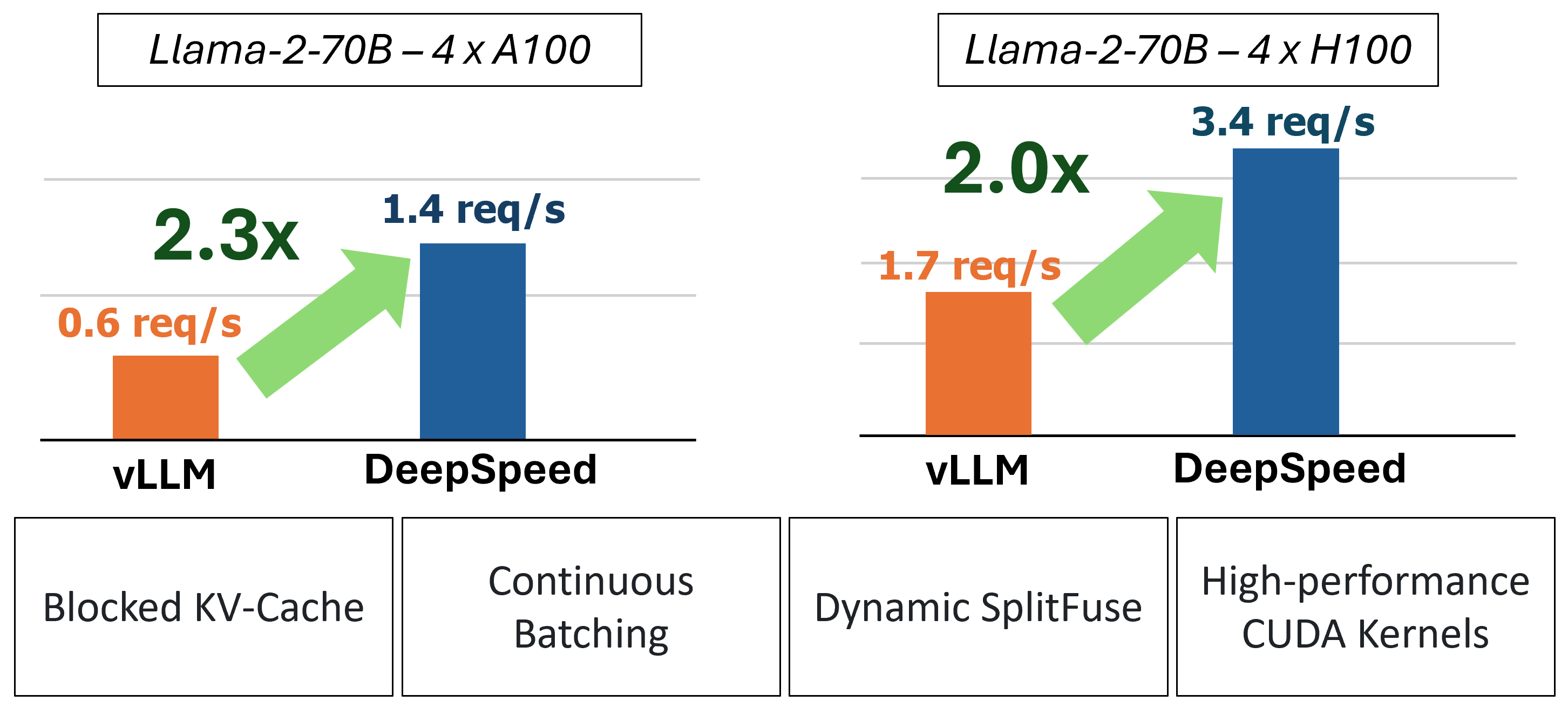
MII通过使用四种关键技术提供了加速的文本生成推断:
要深入了解这些功能,请参考我们的博客,该博客还包括详细的性能分析。
过去,MII引入了低延迟服务方案的几个关键性能优化:
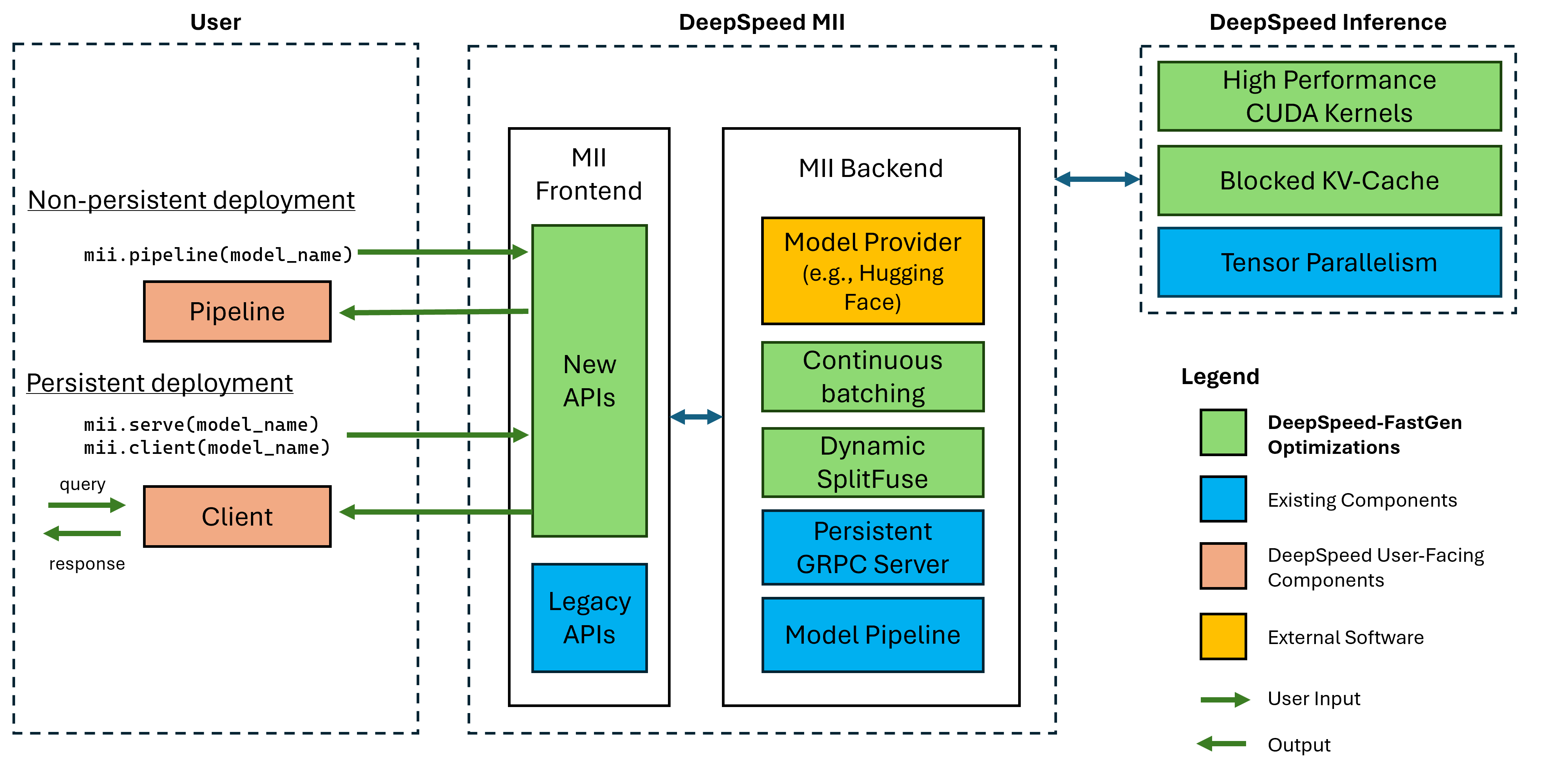
图1:MII体系结构,显示MII在部署之前使用DS-推导如何自动优化OSS模型。该图中的DeepSpeed-Fastgen优化已在我们的博客文章中发表。
下层MII由深速推导提供动力。根据模型体系结构,型号大小,批处理大小和可用的硬件资源,MII会自动应用适当的系统优化集以最大程度地减少延迟和最大化吞吐量。
MII目前支持八个流行模型架构的37,000多个型号。我们计划在短期内添加其他模型,如果您需要支持的特定模型架构,请提出问题并告诉我们。当前的所有模型都在我们的后端均采用拥抱面孔,以提供模型权重和模型相应的令牌。对于当前版本,我们支持以下模型体系结构:
| 模特家庭 | 尺寸范围 | 〜型号计数 |
|---|---|---|
| 鹘 | 7b -180b | 600 |
| 骆驼 | 7b -65b | 57,000 |
| Llama-2 | 7b -70b | 1200 |
| Llama-3 | 8b -405b | 1,600 |
| Mistral | 7b | 23,000 |
| 混合(MOE) | 8x7b | 2,900 |
| 选择 | 0.1b -66b | 2,200 |
| PHI-2 | 2.7b | 1,500 |
| QWEN | 7b -72b | 500 |
| qwen2 | 0.5B -72B | 3700 |
MII传统API支持超过50,000多种不同的模型,包括Bert,Roberta,稳定扩散以及其他文本生成模型,例如Bloom,GPT-J等。有关完整列表,请参阅我们的遗产支持的模型表。
DeepSpeed-MII允许用户在仅几行代码中为受支持的模型创建非持久和持久部署。
Fasest入门的方法是我们的PYPI发布DeepSpeed-MII,这意味着您可以在几分钟之内通过:
pip install deepspeed-mii为了易于使用和在这个空间中许多项目所需的漫长的编译时间的大幅度减少,我们通过一个名为DeepSpeed-Kernels的新图书馆分发了预编译的Python车轮,覆盖了我们的大多数自定义内核。我们发现,该库在具有Compute功能8.0+(Ampere+),CUDA 11.6+和Ubuntu 20+的NVIDIA GPU的环境中非常便宜。在大多数情况下,您甚至不需要知道此库存在,因为它是DeepSpeed-MII的依赖性,并且将与之一起安装。但是,如果出于任何原因需要手动编译我们的内核,请参阅我们的高级安装文档。
非持久管道是尝试DeepSpeed-MII的好方法。非渗透管道仅在您正在运行的Python脚本的过程中出现。运行非持久管道部署的完整示例仅为4行。尝试一下!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response )返回的response是Response对象的列表。我们可以访问有关生成的几个详细信息(例如, response[0].prompt_length ):
generated_text: str文本。prompt_length: int令牌数。generated_length: int生成的代币数量。finish_reason: str停止生成的原因。 stop表示生成EOS令牌, length表示将生成达到max_new_tokens或max_length 。如果要释放设备内存并破坏管道,请使用destroy方法:
pipe . destroy ()使用MII,利用多GPU系统来提高性能非常容易。使用deepspeed Launcher运行时,张量并行性将由--num_gpus自动控制:
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.py虽然仅需要模型名称或路径来站立非固定管道部署,但我们为用户提供自定义选项:
mii.pipeline()选项:
model_name_or_path: str名称或拥抱面模型的本地路径。max_length: int为提示 +响应设置默认的最大令牌长度。all_rank_output: bool启用时,所有等级返回生成的文本。默认情况下,只有等级0将返回文本。用户还可以控制单个提示的生成特性(即,在调用pipe() )的使用以下选项:
max_length: int为及时 +响应设置每个prompt的最大令牌长度。min_new_tokens: int设置响应中生成的最小令牌数。 max_length将优先于此设置。max_new_tokens: int设置响应中生成的最大令牌数。ignore_eos: bool (默认为False )设置为True ,可以防止遇到EOS令牌时产生。top_p: float (默认为0.9 )当设置以下1.0以下时,过滤令牌,仅保留最可能的最可能的位置,即令牌概率和top_p 。top_k: int (默认为None )当None ,top-k过滤将被禁用。设置时,要保留最高概率令牌的数量。temperature: float (默认为None ),当None禁用温度。设置时,调节令牌概率。do_sample: bool (默认为True )当True时,示例输出logits。 False时,使用贪婪的抽样。return_full_text: bool (默认为False ), True ,将输入提示提示为返回的文本持续部署非常适合与长期运行和生产应用一起使用。持久模型使用轻巧的GRPC服务器,该服务器可以一次由多个客户端查询。运行持久模型的完整示例仅为5行。尝试一下!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response )返回的response是Response对象的列表。我们可以访问有关生成的几个详细信息(例如, response[0].prompt_length ):
generated_text: str文本。prompt_length: int令牌数。generated_length: int生成的代币数量。finish_reason: str停止生成的原因。 stop表示生成EOS令牌, length表示将生成达到max_new_tokens或max_length 。如果我们想从其他过程中生成文本,我们也可以这样做:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )当我们不再需要持续部署时,我们可以从任何客户端关闭服务器:
client . terminate_server ()持续部署利用多GPU系统来提高延迟和吞吐量也很容易。模型并行性由tensor_parallel input to mii.serve控制:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )与单个GPU相比,最终的部署将使模型在2 GPU上将模型分开,以提供更快的推理和更高的吞吐量。
我们还可以通过设置多个模型复制品并利用DeepSpeed-MII提供的负载平衡来利用多GPU(和多节点)系统:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )由此产生的部署将加载2个模型复制品(每GPU一个)和2个模型实例之间的负载平衡收入请求。
模型并行性和复制品也可以合并,以利用更多GPU的系统。在下面的示例中,我们运行了2个模型复制品,每个复制品在具有4个GPU的系统上跨2 GPU:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )模型并行性和模型复制品之间的选择最大性能取决于硬件,模型和工作负载的性质。例如,使用小型模型,用户可能会发现模型复制品为请求提供了最低的平均延迟。同时,仅使用模型并行性时,大型模型可能会达到更大的总体吞吐量。
MII通过设置enable_restful_api=True在创建持久的MII部署时,可以轻松地通过RESTFUL API设置和运行模型推断。 RESTFUL API可以在http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} 。下面提供了一个完整的示例:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ?注意:虽然没有必要提供deployment_name (MII将为您自动化一个),但最好提供deployment_name ,以确保您可以与正确的Restful API接口。
然后,您可以使用任何HTTP客户端将提示发送到Restful网关,例如curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment或python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)虽然仅需要模型名称或路径来站立持续部署,但我们为用户提供自定义选项。
mii.serve()选项:
model_name_or_path: str (必需)名称或拥抱面模型的本地路径。max_length: int (默认为模型配置中的最大序列长度)设置了提示 +响应的默认最大令牌长度。deployment_name: str (默认为f"{model_name_or_path}-mii-deployment" )一个唯一的识别字符串,用于持久模型。如果提供,则应使用client = mii.client(deployment_name)检索客户端对象。tensor_parallel: int (默认为1 )gpu的数量,以将模型跨越。replica_num: int (默认为1 )要站起来的模型副本数量。enable_restful_api: bool (默认为False )启用时,将启动一个恢复的API网关进程,可以在http://{host}:{restful_api_port}/mii/{deployment_name} 。有关更多详细信息,请参见有关RESTFUL API的部分。restful_api_port: int (默认为28080 )当enable_restful_api设置为True时,用于与Restful API接口的端口号。 mii.client()选项:
model_or_deployment_name: str模型或deployment_name的str名称传递给mii.serve()用户还可以控制单个提示的生成特性(即,在调用client.generate() )的使用以下选项:
max_length: int为及时 +响应设置每个prompt的最大令牌长度。min_new_tokens: int设置响应中生成的最小令牌数。 max_length将优先于此设置。max_new_tokens: int设置响应中生成的最大令牌数。ignore_eos: bool (默认为False )设置为True ,可以防止遇到EOS令牌时产生。top_p: float (默认为0.9 )当设置以下1.0以下时,过滤令牌,仅保留最可能的最可能的位置,即令牌概率和top_p 。top_k: int (默认为None )当None ,top-k过滤将被禁用。设置时,要保留最高概率令牌的数量。temperature: float (默认为None ),当None禁用温度。设置时,调节令牌概率。do_sample: bool (默认为True )当True时,示例输出logits。 False时,使用贪婪的抽样。return_full_text: bool (默认为False ), True ,将输入提示提示为返回的文本该项目欢迎贡献和建议。大多数捐款要求您同意撰写贡献者许可协议(CLA),宣布您有权并实际上授予我们使用您的贡献的权利。有关详细信息,请访问https://cla.opensource.microsoft.com。
当您提交拉动请求时,CLA机器人将自动确定您是否需要提供CLA并适当装饰PR(例如状态检查,评论)。只需按照机器人提供的说明即可。您只需要使用我们的CLA在所有存储库中进行一次。
该项目采用了Microsoft开源的行为代码。有关更多信息,请参见《行为守则常见问题守则》或与其他问题或评论联系[email protected]。
该项目可能包含用于项目,产品或服务的商标或徽标。 Microsoft商标或徽标的授权使用受到了Microsoft的商标和品牌准则的约束。在此项目的修改版本中使用Microsoft商标或徽标不得引起混乱或暗示Microsoft赞助。任何使用第三方商标或徽标都遵守这些第三方政策。


