DeepSpeed MII
v0.3.1





Memperkenalkan MII, perpustakaan Python open-source yang dirancang oleh Deepspeed untuk mendemokratisasi inferensi model yang kuat dengan fokus pada throughput tinggi, latensi rendah, dan efektivitas biaya.
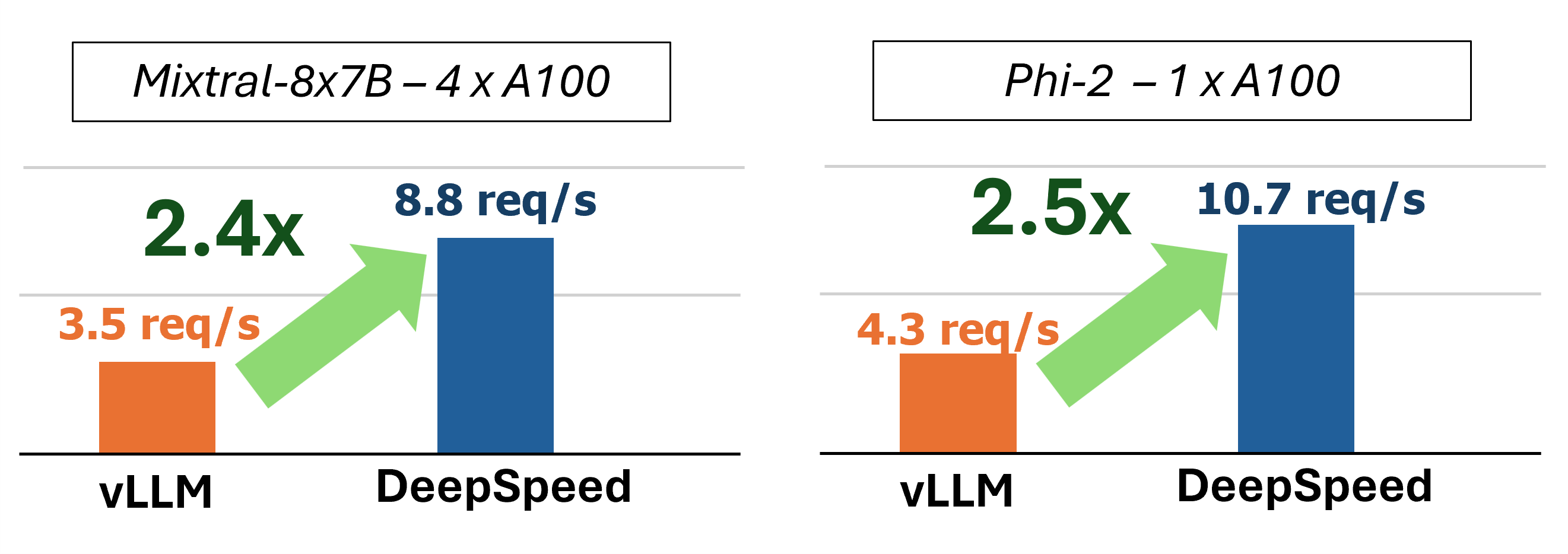
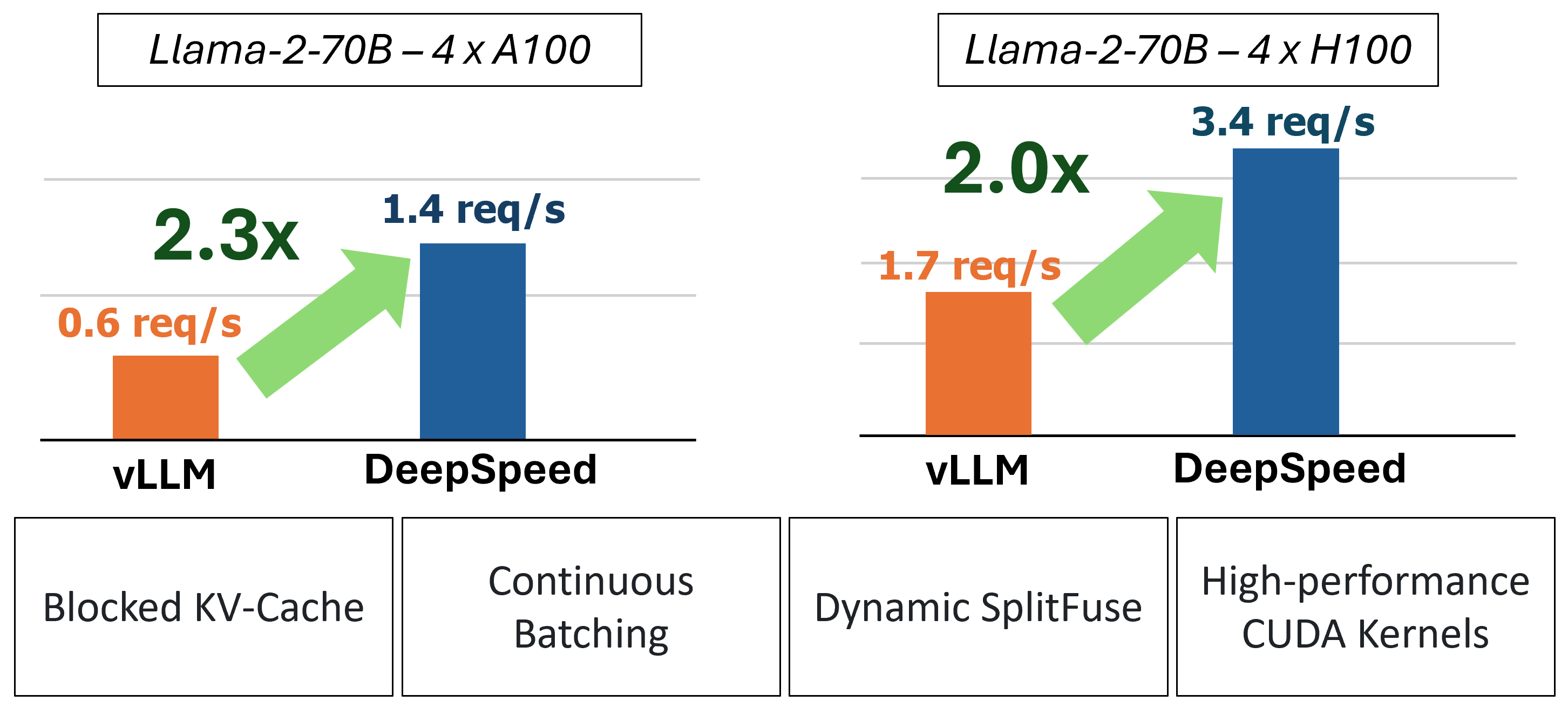
MII memberikan inferensi generasi teks yang dipercepat melalui penggunaan empat teknologi utama:
Untuk menyelam lebih dalam untuk memahami fitur -fitur ini, silakan merujuk ke blog kami yang juga mencakup analisis kinerja terperinci.
Di masa lalu, MII memperkenalkan beberapa optimasi kinerja utama untuk skenario porsi latensi rendah:
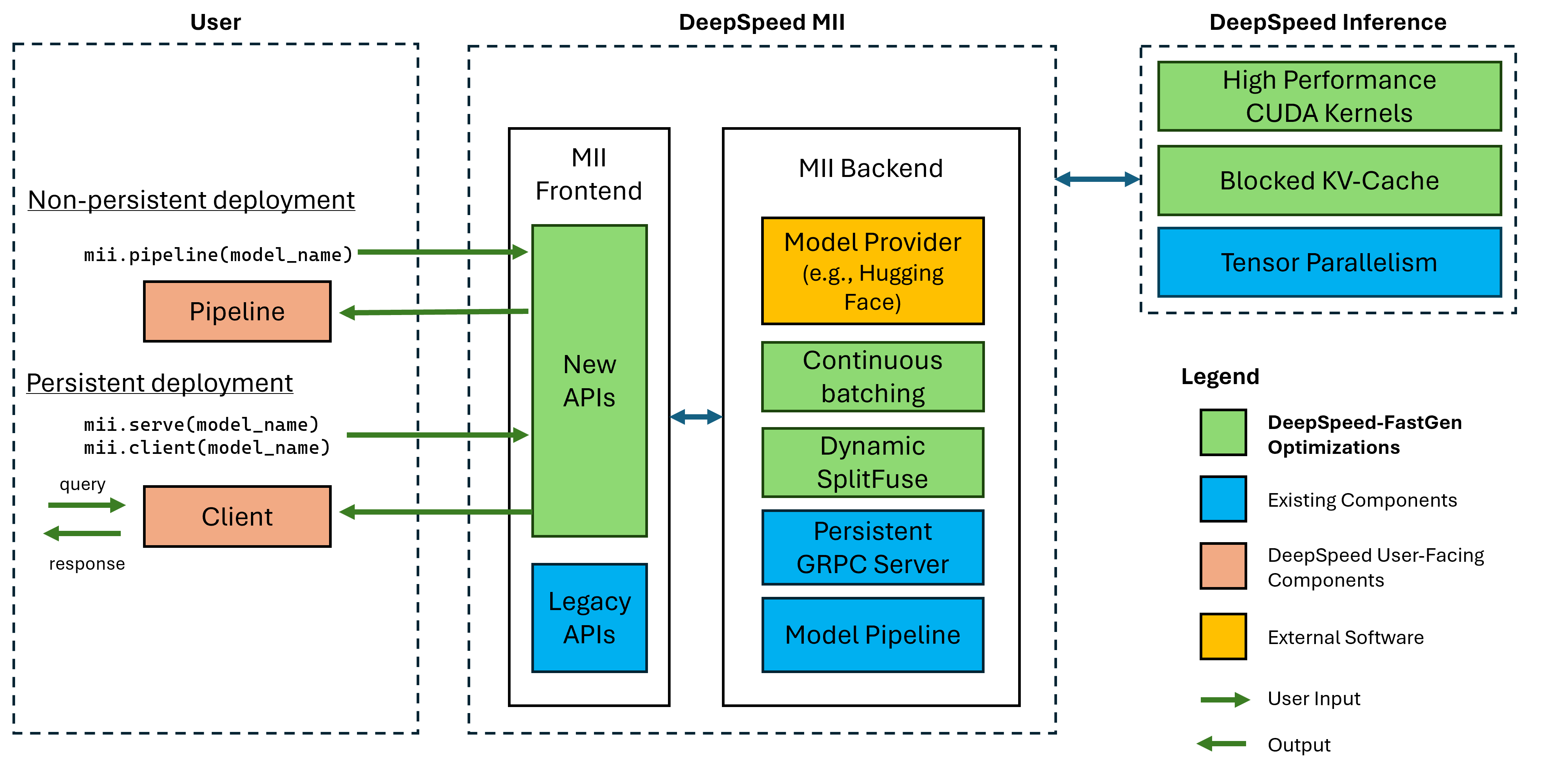
Gambar 1: Arsitektur MII, menunjukkan bagaimana MII secara otomatis mengoptimalkan model OSS menggunakan DS-Inference sebelum menggunakannya. Optimalisasi deep-fastgen dalam gambar telah diterbitkan di posting blog kami.
MII di bawah-tempat ditenagai oleh Inference Inference. Berdasarkan arsitektur model, ukuran model, ukuran batch, dan sumber daya perangkat keras yang tersedia, MII secara otomatis menerapkan set optimisasi sistem yang sesuai untuk meminimalkan latensi dan memaksimalkan throughput.
MII saat ini mendukung lebih dari 37.000 model di delapan arsitektur model populer. Kami berencana untuk menambahkan model tambahan dalam waktu dekat, jika ada arsitektur model khusus yang ingin Anda dukung, silakan mengajukan masalah dan beri tahu kami. Semua model saat ini memanfaatkan wajah pelukan di backend kami untuk memberikan bobot model dan tokenizer yang sesuai model. Untuk rilis kami saat ini, kami mendukung arsitektur model berikut:
| keluarga model | Kisaran ukuran | ~ Hitungan model |
|---|---|---|
| Elang | 7b - 180b | 600 |
| Llama | 7b - 65b | 57.000 |
| Llama-2 | 7b - 70b | 1.200 |
| Llama-3 | 8b - 405b | 1.600 |
| Mistral | 7b | 23.000 |
| Mixtral (MOE) | 8x7b | 2.900 |
| MEMILIH | 0.1b - 66b | 2.200 |
| Phi-2 | 2.7b | 1.500 |
| Qwen | 7b - 72b | 500 |
| Qwen2 | 0.5b - 72b | 3700 |
MII Legacy API mendukung lebih dari 50.000 model yang berbeda termasuk Bert, Roberta, difusi stabil, dan model generasi teks lainnya seperti Bloom, GPT-J, dll. Untuk daftar lengkap, silakan lihat tabel model yang didukung warisan kami.
Deepspeed-MII memungkinkan pengguna untuk membuat penyebaran yang tidak persisten dan gigih untuk model yang didukung hanya dalam beberapa baris kode.
Cara terbaik untuk memulai adalah dengan rilis PYPI kami dari Deeped-MII yang berarti Anda dapat memulai dalam beberapa menit melalui:
pip install deepspeed-miiUntuk kemudahan penggunaan dan pengurangan yang signifikan dalam waktu kompilasi yang panjang yang dibutuhkan banyak proyek di ruang ini kami mendistribusikan roda Python yang telah dikompilasi sebelumnya yang menutupi sebagian besar kernel khusus kami melalui perpustakaan baru yang disebut Deepspeed-Kernels. Kami telah menemukan perpustakaan ini sangat portabel di seluruh lingkungan dengan NVIDIA GPU dengan kemampuan komputasi 8.0+ (Ampere+), CUDA 11.6+, dan Ubuntu 20+. Dalam kebanyakan kasus, Anda bahkan tidak perlu mengetahui perpustakaan ini ada karena merupakan ketergantungan dari Deepspeed-MII dan akan diinstal dengannya. Namun, jika karena alasan apa pun Anda perlu menyusun kernel kami secara manual, silakan lihat dokumen instalasi lanjutan kami.
Pipa yang tidak persisten adalah cara yang bagus untuk mencoba Deeped-MII. Pipa-pipa non-persisten hanya ada selama skrip Python yang Anda jalankan. Contoh lengkap untuk menjalankan penyebaran pipa yang tidak persisten hanya 4 baris. Cobalah!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) response yang dikembalikan adalah daftar objek Response . Kami dapat mengakses beberapa detail tentang generasi (misalnya, response[0].prompt_length ):
generated_text: str yang dihasilkan oleh model.prompt_length: int Jumlah token di prompt asli.generated_length: int jumlah token yang dihasilkan.finish_reason: str Alasan untuk menghentikan generasi. stop menunjukkan token EOS dihasilkan dan length menunjukkan generasi yang dicapai max_new_tokens atau max_length . Jika Anda ingin membebaskan memori perangkat dan menghancurkan pipa, gunakan metode destroy :
pipe . destroy () Mengambil keuntungan dari sistem multi-GPU untuk kinerja yang lebih besar mudah dengan MII. Saat dijalankan dengan peluncur deepspeed , Tensor Parallelism secara otomatis dikendalikan oleh bendera --num_gpus :
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pyMeskipun hanya nama atau jalur model yang diperlukan untuk berdiri penyebaran pipa yang tidak dipersisten, kami menawarkan opsi kustomisasi kepada pengguna kami:
opsi mii.pipeline() :
model_name_or_path: str atau jalur lokal ke model huggingface.max_length: int mengatur panjang token maksimum default untuk respons prompt +.all_rank_output: bool Saat diaktifkan, semua peringkat mengembalikan teks yang dihasilkan. Secara default, hanya peringkat 0 yang akan mengembalikan teks. Pengguna juga dapat mengontrol karakteristik generasi untuk petunjuk individu (yaitu, saat memanggil pipe() ) dengan opsi berikut:
max_length: int mengatur panjang token maksimum per prompt untuk respons prompt +.min_new_tokens: int menetapkan jumlah minimum token yang dihasilkan dalam respons. max_length akan lebih diutamakan daripada pengaturan ini.max_new_tokens: int menetapkan jumlah token maksimum yang dihasilkan dalam respons.ignore_eos: bool (default ke False ) Pengaturan ke True mencegah pembuatan dari akhir ketika token EOS ditemui.top_p: float (default ke 0.9 ) Ketika diatur di bawah 1.0 , filter token dan simpan hanya yang paling mungkin, di mana probabilitas token berjumlah ≥ top_p .top_k: int (default ke None ) Ketika None , penyaringan top-k dinonaktifkan. Saat diatur, jumlah token probabilitas tertinggi untuk disimpan.temperature: float (default ke None ) saat None , suhu dinonaktifkan. Saat diatur, modulasi probabilitas token.do_sample: bool (default ke True ) saat True , sampel logit output. Saat False , gunakan pengambilan sampel serakah.return_full_text: bool (default ke False ) saat True , persiapkan prompt input ke teks yang dikembalikan Penyebaran persisten sangat ideal untuk digunakan dengan aplikasi jangka panjang dan produksi. Model persisten menggunakan server GRPC ringan yang dapat ditanyai oleh banyak klien sekaligus. Contoh lengkap untuk menjalankan model persisten hanya 5 baris. Cobalah!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) response yang dikembalikan adalah daftar objek Response . Kami dapat mengakses beberapa detail tentang generasi (misalnya, response[0].prompt_length ):
generated_text: str yang dihasilkan oleh model.prompt_length: int Jumlah token di prompt asli.generated_length: int jumlah token yang dihasilkan.finish_reason: str Alasan untuk menghentikan generasi. stop menunjukkan token EOS dihasilkan dan length menunjukkan generasi yang dicapai max_new_tokens atau max_length .Jika kita ingin menghasilkan teks dari proses lain, kita bisa melakukannya juga:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )Ketika kami tidak lagi membutuhkan penyebaran yang persisten, kami dapat mematikan server dari klien mana pun:
client . terminate_server () Mengambil keuntungan dari sistem multi-GPU untuk latensi dan throughput yang lebih baik juga mudah dengan penyebaran persisten. Model Parallelism dikendalikan oleh input tensor_parallel ke mii.serve :
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )Penyebaran yang dihasilkan akan membagi model di 2 GPU untuk memberikan inferensi yang lebih cepat dan throughput yang lebih tinggi daripada GPU tunggal.
Kami juga dapat memanfaatkan sistem multi-GPU (dan multi-node) dengan menyiapkan beberapa replika model dan mengambil keuntungan dari keseimbangan beban yang disediakan oleh Deeped-MII:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )Penyebaran yang dihasilkan akan memuat 2 replika model (satu per GPU) dan permintaan masuk keseimbangan beban antara 2 contoh model.
Model paralelisme dan replika juga dapat digabungkan untuk memanfaatkan sistem dengan lebih banyak GPU. Dalam contoh di bawah ini, kami menjalankan 2 replika model, masing -masing terpisah di 2 GPU pada sistem dengan 4 GPU:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )Pilihan antara paralelisme model dan replika model untuk kinerja maksimum akan tergantung pada sifat perangkat keras, model, dan beban kerja. Misalnya, dengan model kecil pengguna dapat menemukan bahwa replika model memberikan latensi rata -rata terendah untuk permintaan. Sementara itu, model besar dapat mencapai throughput keseluruhan yang lebih besar saat hanya menggunakan paralelisme model.
MII memudahkan untuk mengatur dan menjalankan inferensi model melalui API REST dengan mengatur enable_restful_api=True saat membuat penyebaran MII yang persisten. API RESTFUL dapat menerima permintaan di http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} . Contoh lengkap disediakan di bawah ini:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) ? Catatan: Saat menyediakan deployment_name tidak diperlukan (MII akan autogenerate untuk Anda), itu adalah praktik yang baik untuk menyediakan deployment_name sehingga Anda dapat memastikan Anda berinteraksi dengan API RESTful yang benar.
Anda kemudian dapat mengirim petunjuk ke Gateway Restful dengan klien HTTP, seperti curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment atau python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)Meskipun hanya nama model atau jalur yang diperlukan untuk berdiri penempatan yang persisten, kami menawarkan opsi kustomisasi kepada pengguna kami.
opsi mii.serve() :
model_name_or_path: str (Diperlukan) Nama atau jalur lokal ke model Huggingface.max_length: int (default ke panjang urutan maksimum dalam konfigurasi model) mengatur panjang token maksimum default untuk respons prompt +.deployment_name: str (default ke f"{model_name_or_path}-mii-deployment" ) String identifikasi yang unik untuk model persisten. Jika disediakan, objek klien harus diambil dengan client = mii.client(deployment_name) .tensor_parallel: int (default ke 1 ) jumlah GPU untuk membagi model di seluruh.replica_num: int (default ke 1 ) jumlah replika model untuk berdiri.enable_restful_api: bool (default ke False ) Ketika diaktifkan, proses gateway API yang tenang diluncurkan yang dapat ditanya di http://{host}:{restful_api_port}/mii/{deployment_name} . Lihat bagian API RESTful untuk detail lebih lanjut.restful_api_port: int (default ke 28080 ) Nomor port yang digunakan untuk berinteraksi dengan API RESTful saat enable_restful_api diatur ke True . opsi mii.client() :
model_or_deployment_name: str dari model atau deployment_name diteruskan ke mii.serve() Pengguna juga dapat mengontrol karakteristik generasi untuk petunjuk individu (yaitu, saat menelepon client.generate() ) dengan opsi berikut:
max_length: int mengatur panjang token maksimum per prompt untuk respons prompt +.min_new_tokens: int menetapkan jumlah minimum token yang dihasilkan dalam respons. max_length akan lebih diutamakan daripada pengaturan ini.max_new_tokens: int menetapkan jumlah token maksimum yang dihasilkan dalam respons.ignore_eos: bool (default ke False ) Pengaturan ke True mencegah pembuatan dari akhir ketika token EOS ditemui.top_p: float (default ke 0.9 ) Ketika diatur di bawah 1.0 , filter token dan simpan hanya yang paling mungkin, di mana probabilitas token berjumlah ≥ top_p .top_k: int (default ke None ) Ketika None , penyaringan top-k dinonaktifkan. Saat diatur, jumlah token probabilitas tertinggi untuk disimpan.temperature: float (default ke None ) saat None , suhu dinonaktifkan. Saat diatur, modulasi probabilitas token.do_sample: bool (default ke True ) saat True , sampel logit output. Saat False , gunakan pengambilan sampel serakah.return_full_text: bool (default ke False ) saat True , persiapkan prompt input ke teks yang dikembalikanProyek ini menyambut kontribusi dan saran. Sebagian besar kontribusi mengharuskan Anda untuk menyetujui perjanjian lisensi kontributor (CLA) yang menyatakan bahwa Anda memiliki hak untuk, dan benar -benar melakukannya, beri kami hak untuk menggunakan kontribusi Anda. Untuk detailnya, kunjungi https://cla.opensource.microsoft.com.
Saat Anda mengirimkan permintaan tarik, bot CLA akan secara otomatis menentukan apakah Anda perlu memberikan CLA dan menghiasi PR secara tepat (misalnya, pemeriksaan status, komentar). Cukup ikuti instruksi yang disediakan oleh bot. Anda hanya perlu melakukan ini sekali di semua repo menggunakan CLA kami.
Proyek ini telah mengadopsi kode perilaku open source Microsoft. Untuk informasi lebih lanjut, lihat FAQ Kode Perilaku atau hubungi [email protected] dengan pertanyaan atau komentar tambahan.
Proyek ini dapat berisi merek dagang atau logo untuk proyek, produk, atau layanan. Penggunaan resmi merek dagang atau logo Microsoft tunduk dan harus mengikuti pedoman merek dagang & merek Microsoft. Penggunaan merek dagang atau logo Microsoft dalam versi yang dimodifikasi dari proyek ini tidak boleh menyebabkan kebingungan atau menyiratkan sponsor Microsoft. Setiap penggunaan merek dagang atau logo pihak ketiga tunduk pada kebijakan pihak ketiga tersebut.


