DeepSpeed MII
v0.3.1





แนะนำ MII ซึ่งเป็นห้องสมุด Python โอเพนซอร์ซที่ออกแบบโดย Deepspeed เพื่อให้เป็นประชาธิปไตยในการอนุมานแบบจำลองที่ทรงพลังโดยมุ่งเน้นไปที่ปริมาณสูงเวลาแฝงต่ำและความคุ้มค่า
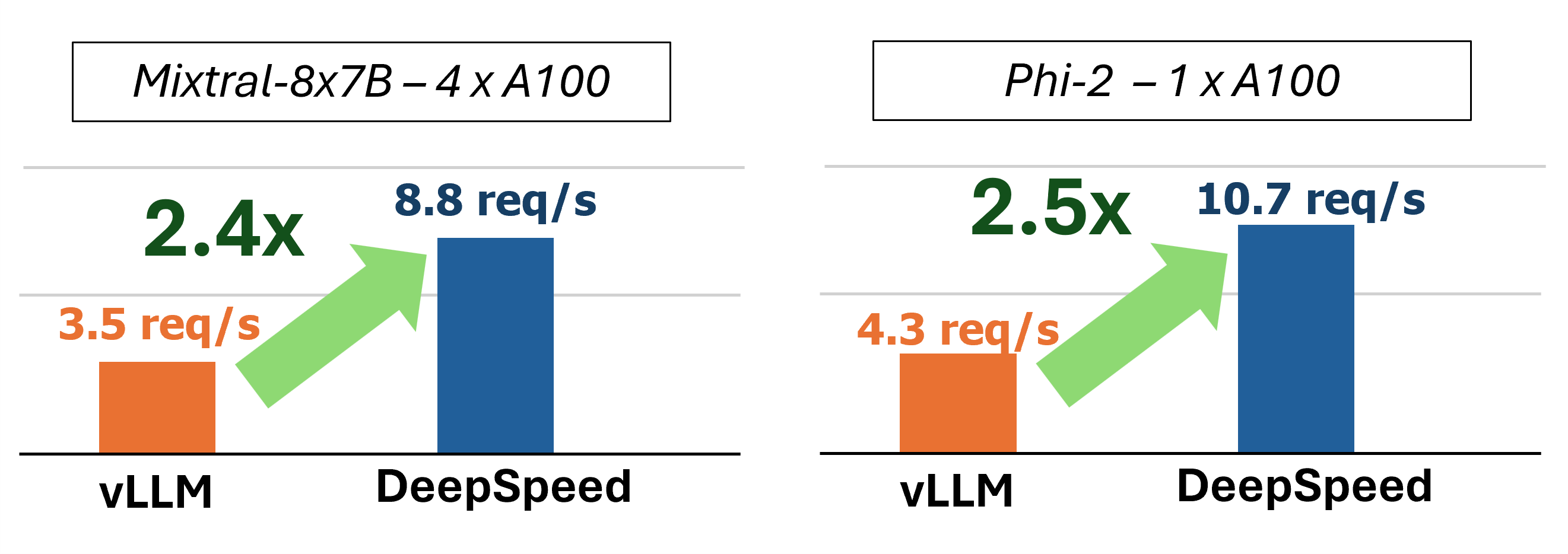
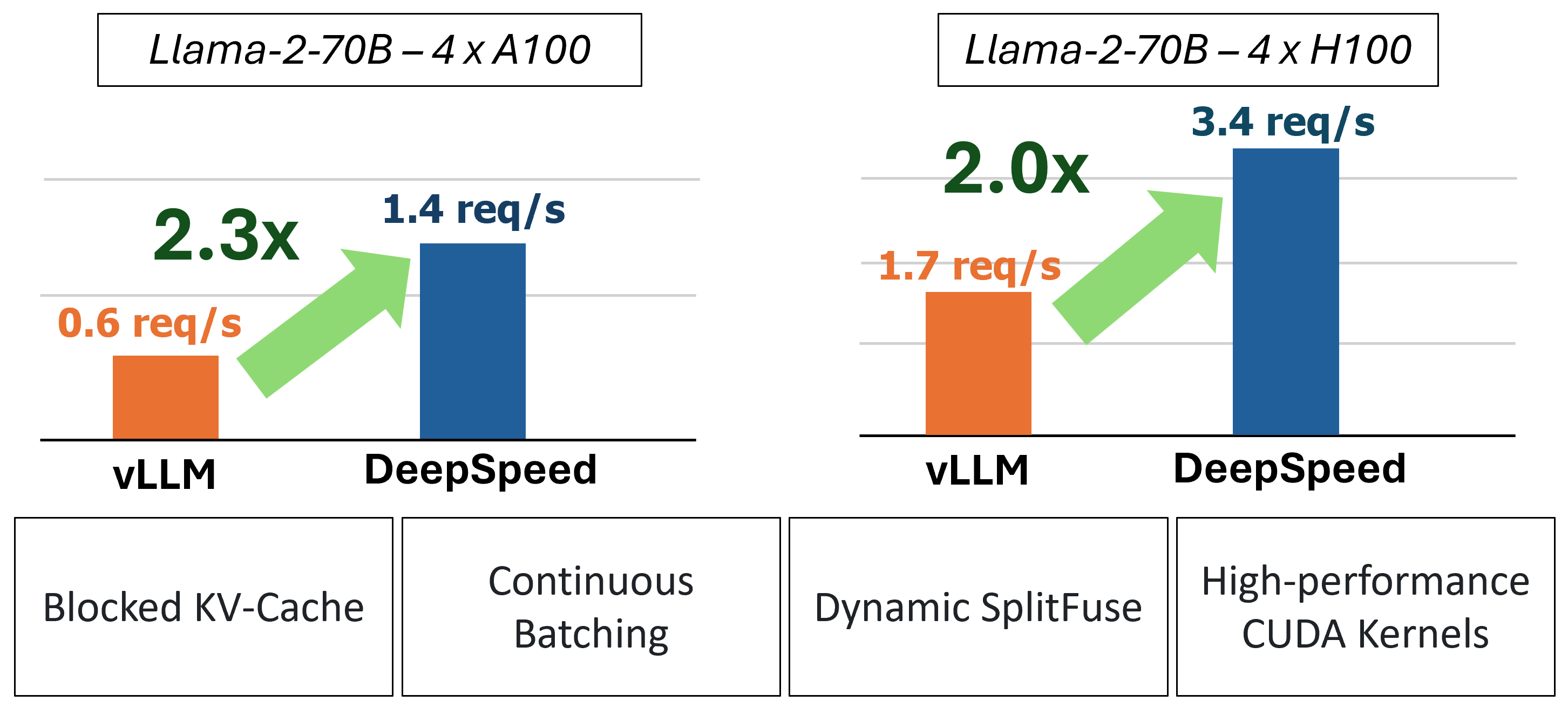
MII ให้การอนุมานการสร้างข้อความแบบเร่งด่วนผ่านการใช้เทคโนโลยีหลักสี่ประการ:
สำหรับการดำน้ำลึกลงไปในการทำความเข้าใจคุณสมบัติเหล่านี้โปรดดูที่บล็อกของเราซึ่งรวมถึงการวิเคราะห์ประสิทธิภาพโดยละเอียด
ในอดีต MII ได้เปิดตัวการเพิ่มประสิทธิภาพประสิทธิภาพที่สำคัญหลายประการสำหรับสถานการณ์การให้บริการที่มีความล่าช้าต่ำ:
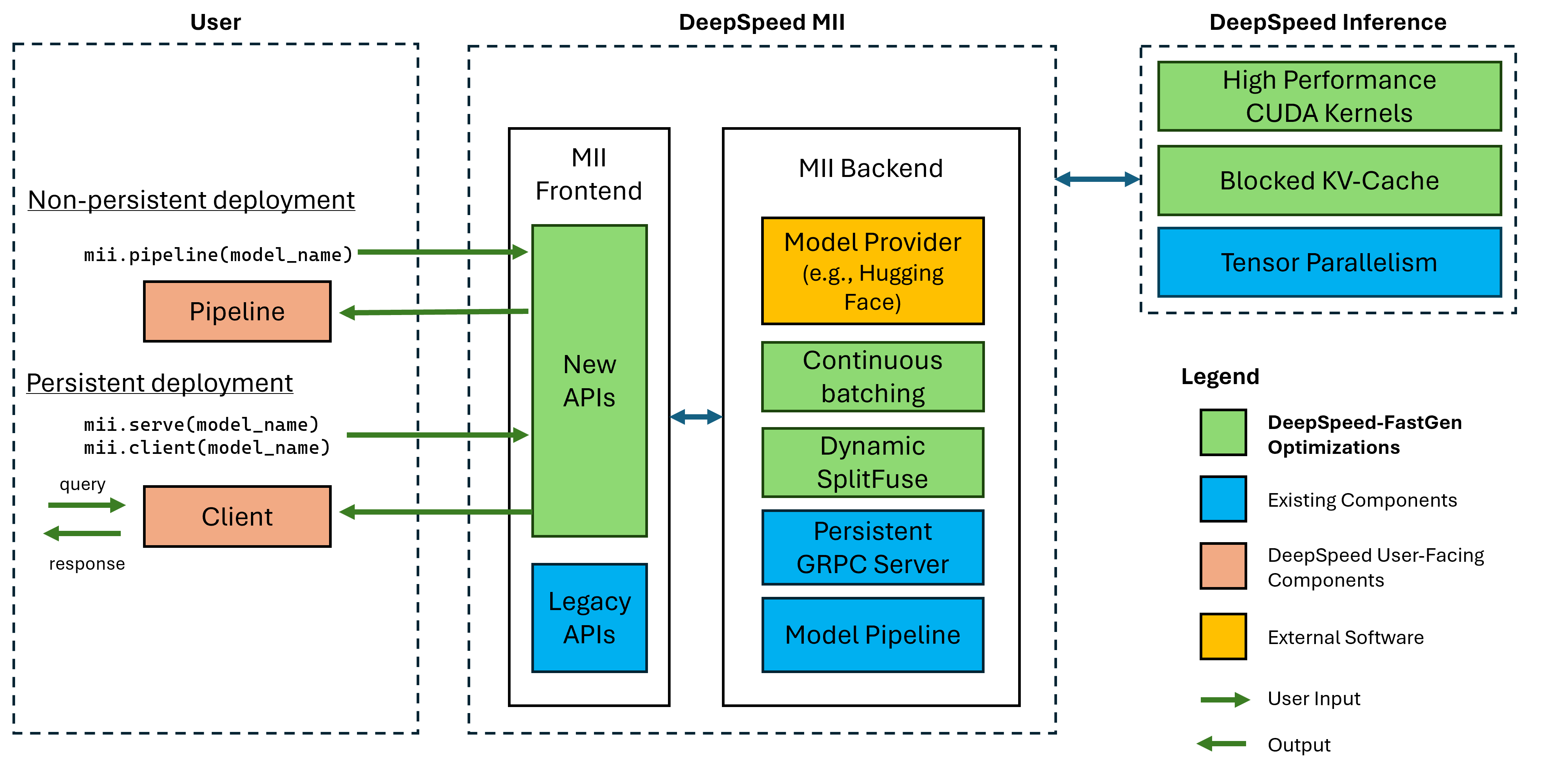
รูปที่ 1: สถาปัตยกรรม MII แสดงให้เห็นว่า MII ปรับแต่งโมเดล OSS โดยอัตโนมัติโดยใช้ DS-INFERNAGE โดยอัตโนมัติก่อนที่จะปรับใช้ การปรับให้เหมาะสมที่สุดในรูปแบบ DeepSpeed-Fastgen ได้รับการเผยแพร่ในโพสต์บล็อกของเรา
MII ที่อยู่ใต้ฮูดนั้นขับเคลื่อนโดยการอนุมานแบบ deepspeed ขึ้นอยู่กับสถาปัตยกรรมของโมเดลขนาดของรุ่นขนาดแบทช์และทรัพยากรฮาร์ดแวร์ที่มีอยู่ MII จะใช้ชุดการเพิ่มประสิทธิภาพระบบที่เหมาะสมโดยอัตโนมัติเพื่อลดเวลาแฝงและเพิ่มปริมาณงาน
ปัจจุบัน MII รองรับรุ่นมากกว่า 37,000 รุ่นในสถาปัตยกรรมรุ่นยอดนิยมแปดรุ่น เราวางแผนที่จะเพิ่มโมเดลเพิ่มเติมในระยะเวลาอันใกล้นี้หากมีสถาปัตยกรรมโมเดลเฉพาะที่คุณต้องการสนับสนุนโปรดยื่นปัญหาและแจ้งให้เราทราบ รุ่นปัจจุบันทั้งหมดใช้ประโยชน์จากการกอดใบหน้าในแบ็กเอนด์ของเราเพื่อให้ทั้งน้ำหนักรุ่นและโทเค็นที่สอดคล้องกันของโมเดล สำหรับการเปิดตัวปัจจุบันของเราเราสนับสนุนสถาปัตยกรรมโมเดลต่อไปนี้:
| ครอบครัวนางแบบ | ช่วงขนาด | ~ จำนวนรุ่น |
|---|---|---|
| เหยี่ยว | 7b - 180b | 600 |
| ลาม่า | 7b - 65b | 57,000 |
| Llama-2 | 7b - 70b | 1,200 |
| Llama-3 | 8B - 405B | 1,600 |
| ผิดพลาด | 7b | 23,000 |
| Mixtral (Moe) | 8x7b | 2,900 |
| เลือก | 0.1b - 66b | 2,200 |
| Phi-2 | 2.7B | 1,500 |
| Qwen | 7b - 72b | 500 |
| Qwen2 | 0.5B - 72B | 3700 |
MII Legacy APIs รองรับรุ่นที่แตกต่างกันกว่า 50,000 รุ่นรวมถึง Bert, Roberta, การแพร่กระจายที่เสถียรและโมเดลการสร้างข้อความอื่น ๆ เช่น Bloom, GPT-J ฯลฯ สำหรับรายการทั้งหมดโปรดดูตารางรุ่นที่รองรับมรดกของเรา
DeepSpeed-MII ช่วยให้ผู้ใช้สามารถสร้างการปรับใช้ที่ไม่ได้ใช้งานและถาวรสำหรับรุ่นที่รองรับในรหัสเพียงไม่กี่บรรทัด
วิธีการเริ่มต้นใช้งานคือการเปิดตัว PYPI ของ DeepSpeed-Mii ซึ่งหมายความว่าคุณสามารถเริ่มต้นได้ภายในไม่กี่นาทีผ่าน:
pip install deepspeed-miiเพื่อความสะดวกในการใช้งานและการลดลงอย่างมีนัยสำคัญในเวลารวบรวมที่ยาวนานซึ่งหลายโครงการต้องการในพื้นที่นี้เราจะแจกจ่ายล้องูหลามที่รวบรวมไว้ล่วงหน้าซึ่งครอบคลุมเมล็ดพันธุ์ที่กำหนดเองส่วนใหญ่ของเราผ่านห้องสมุดใหม่ที่เรียกว่า Deepspeed-Kernels เราพบว่าห้องสมุดนี้สามารถพกพาได้มากในสภาพแวดล้อมที่มี Nvidia GPU ที่มีความสามารถในการคำนวณ 8.0+ (Ampere+), Cuda 11.6+ และ Ubuntu 20+ ในกรณีส่วนใหญ่คุณไม่ควรแม้แต่จะรู้ว่าห้องสมุดนี้มีอยู่เนื่องจากเป็นการพึ่งพา DeepSpeed-Mii และจะติดตั้งด้วย อย่างไรก็ตามหากด้วยเหตุผลใดก็ตามที่คุณต้องรวบรวมเมล็ดของเราด้วยตนเองโปรดดูเอกสารการติดตั้งขั้นสูงของเรา
ไปป์ไลน์ที่ไม่เป็นไปได้เป็นวิธีที่ยอดเยี่ยมในการลอง DeepSpeed-Mii ท่อที่ไม่ได้ใช้เป็นเพียงรอบระยะเวลาของสคริปต์ Python ที่คุณใช้งาน ตัวอย่างเต็มรูปแบบสำหรับการใช้งานการปรับใช้ไปป์ไลน์ที่ไม่ใช้ความคิดนั้นมีเพียง 4 บรรทัด ลองดูสิ!
import mii
pipe = mii . pipeline ( "mistralai/Mistral-7B-v0.1" )
response = pipe ([ "DeepSpeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) response กลับที่ส่งคืนเป็นรายการของวัตถุ Response เราสามารถเข้าถึงรายละเอียดหลายอย่างเกี่ยวกับการสร้าง (เช่น response[0].prompt_length ):
generated_text: str ที่สร้างขึ้นโดยโมเดลprompt_length: int ในพรอมต์ดั้งเดิมgenerated_length: int ของโทเค็นที่สร้างขึ้นfinish_reason: str เหตุผลสำหรับการหยุดรุ่น stop ระบุว่าโทเค็น EOS ถูกสร้างขึ้นและ length หมายถึงการสร้างถึง max_new_tokens หรือ max_length หากคุณต้องการใช้หน่วยความจำอุปกรณ์ฟรีและทำลายท่อให้ใช้วิธี destroy :
pipe . destroy () การใช้ประโยชน์จากระบบ Multi-GPU เพื่อประสิทธิภาพที่มากขึ้นนั้นง่ายด้วย MII เมื่อเรียกใช้กับตัวเรียกใช้งาน deepspeed Tensor Parallelism จะถูกควบคุมโดยอัตโนมัติโดย --num_gpus FLAG:
# Run on a single GPU
deepspeed --num_gpus 1 mii-example.py
# Run on multiple GPUs
deepspeed --num_gpus 2 mii-example.pyในขณะที่มีเพียงชื่อโมเดลหรือเส้นทางที่จำเป็นในการยืนการปรับใช้ไปป์ไลน์แบบไม่ใช้
ตัวเลือก mii.pipeline() :
model_name_or_path: str หรือเส้นทางท้องถิ่นไปยังโมเดล HuggingFacemax_length: int ตั้งค่าความยาวโทเค็นสูงสุดเริ่มต้นสำหรับการตอบกลับด้วยพรอมต์ +all_rank_output: bool เมื่อเปิดใช้งานอันดับทั้งหมดจะส่งคืนข้อความที่สร้างขึ้น โดยค่าเริ่มต้นอันดับ 0 เท่านั้นที่จะส่งคืนข้อความ ผู้ใช้ยังสามารถควบคุมลักษณะการสร้างสำหรับพรอมต์แต่ละรายการ (เช่นเมื่อโทร pipe() ) ด้วยตัวเลือกต่อไปนี้:
max_length: int ตั้งค่าความยาวโทเค็นสูงสุดต่อการฉายสำหรับการตอบสนอง +min_new_tokens: int ตั้งค่าจำนวนโทเค็นขั้นต่ำที่สร้างขึ้นในการตอบสนอง max_length จะมีความสำคัญกว่าการตั้งค่านี้max_new_tokens: int ตั้งค่าจำนวนสูงสุดของโทเค็นที่สร้างขึ้นในการตอบสนองignore_eos: bool (ค่าเริ่มต้นเป็น False ) การตั้งค่าเป็น True ป้องกันการสร้างจากการสิ้นสุดเมื่อพบโทเค็น EOStop_p: float (ค่าเริ่มต้นเป็น 0.9 ) เมื่อตั้งค่าต่ำกว่า 1.0 , โทเค็นตัวกรองและรักษาความน่าจะเป็นมากที่สุดโดยที่ความน่าจะเป็นโทเค็นรวมเป็น≥ top_ptop_k: int (ค่าเริ่มต้นถึง None ) เมื่อ None การกรอง Top-K จะถูกปิดใช้งาน เมื่อตั้งค่าจำนวนโทเค็นความน่าจะเป็นสูงสุดที่จะเก็บไว้temperature: float (ค่าเริ่มต้นถึง None ) เมื่อ None อุณหภูมิจะถูกปิดใช้งาน เมื่อตั้งค่าให้ปรับเปลี่ยนความน่าจะเป็นโทเค็นdo_sample: bool (ค่าเริ่มต้นเป็น True ) เมื่อ True บันทึกเอาต์พุตตัวอย่าง เมื่อ False ให้ใช้การสุ่มตัวอย่างโลภreturn_full_text: bool False True การปรับใช้อย่างต่อเนื่องเหมาะอย่างยิ่งสำหรับการใช้งานกับแอพพลิเคชั่นที่ใช้งานได้ยาวนานและการผลิต รุ่นถาวรใช้เซิร์ฟเวอร์ GRPC ที่มีน้ำหนักเบาซึ่งสามารถสอบถามได้โดยไคลเอนต์หลายตัวในครั้งเดียว ตัวอย่างเต็มรูปแบบสำหรับการเรียกใช้โมเดลถาวรมีเพียง 5 บรรทัด ลองดูสิ!
import mii
client = mii . serve ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ([ "Deepspeed is" , "Seattle is" ], max_new_tokens = 128 )
print ( response ) response กลับที่ส่งคืนเป็นรายการของวัตถุ Response เราสามารถเข้าถึงรายละเอียดหลายอย่างเกี่ยวกับการสร้าง (เช่น response[0].prompt_length ):
generated_text: str ที่สร้างขึ้นโดยโมเดลprompt_length: int ในพรอมต์ดั้งเดิมgenerated_length: int ของโทเค็นที่สร้างขึ้นfinish_reason: str เหตุผลสำหรับการหยุดรุ่น stop ระบุว่าโทเค็น EOS ถูกสร้างขึ้นและ length หมายถึงการสร้างถึง max_new_tokens หรือ max_lengthหากเราต้องการสร้างข้อความจากกระบวนการอื่น ๆ เราก็สามารถทำได้เช่นกัน:
client = mii . client ( "mistralai/Mistral-7B-v0.1" )
response = client . generate ( "Deepspeed is" , max_new_tokens = 128 )เมื่อเราไม่ต้องการการปรับใช้อย่างต่อเนื่องเราสามารถปิดเซิร์ฟเวอร์จากไคลเอนต์ใด ๆ :
client . terminate_server () การใช้ประโยชน์จากระบบ Multi-GPU เพื่อความหน่วงแฝงและปริมาณงานที่ดีขึ้นนั้นเป็นเรื่องง่ายด้วยการปรับใช้อย่างต่อเนื่อง โมเดลขนานถูกควบคุมโดยอินพุต tensor_parallel กับ mii.serve :
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 )การปรับใช้ที่เกิดขึ้นจะแยกโมเดลผ่าน 2 GPU เพื่อส่งมอบการอนุมานที่เร็วขึ้นและปริมาณงานที่สูงกว่า GPU เดียว
นอกจากนี้เรายังสามารถใช้ประโยชน์จากระบบ Multi-GPU (และ multi-node) ได้โดยการตั้งค่าแบบจำลองหลายรุ่นและใช้ประโยชน์จากการปรับสมดุลโหลดที่ DeepSpeed-MII ให้:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , replica_num = 2 )การปรับใช้ที่ได้จะโหลดแบบจำลองโมเดล 2 แบบ (หนึ่งต่อ GPU) และคำขอที่เข้ามาในการปรับสมดุลระหว่างอินสแตนซ์ของรุ่น 2
แบบจำลองความเท่าเทียมและแบบจำลองยังสามารถรวมกันเพื่อใช้ประโยชน์จากระบบที่มี GPU มากขึ้น ในตัวอย่างด้านล่างเราเรียกใช้แบบจำลองโมเดล 2 แบบแต่ละแบบแยกกันผ่าน 2 GPU ในระบบที่มี 4 GPU:
client = mii . serve ( "mistralai/Mistral-7B-v0.1" , tensor_parallel = 2 , replica_num = 2 )ตัวเลือกระหว่างโมเดลคู่ขนานและแบบจำลองแบบสำหรับประสิทธิภาพสูงสุดจะขึ้นอยู่กับลักษณะของฮาร์ดแวร์โมเดลและเวิร์กโหลด ตัวอย่างเช่นด้วยผู้ใช้รุ่นขนาดเล็กอาจพบว่าแบบจำลองโมเดลนั้นให้เวลาแฝงเฉลี่ยต่ำที่สุดสำหรับการร้องขอ ในขณะเดียวกันโมเดลขนาดใหญ่อาจได้รับปริมาณงานโดยรวมมากขึ้นเมื่อใช้แบบจำลองแบบขนานเท่านั้น
MII ทำให้ง่ายต่อการตั้งค่าและเรียกใช้การอนุมานแบบจำลองผ่าน RESTFUL API โดยการตั้งค่า enable_restful_api=True เมื่อสร้างการปรับใช้ MII แบบถาวร RESTFUL API สามารถรับคำขอได้ที่ http://{HOST}:{RESTFUL_API_PORT}/mii/{DEPLOYMENT_NAME} ตัวอย่างเต็มรูปแบบด้านล่าง:
client = mii . serve (
"mistralai/Mistral-7B-v0.1" ,
deployment_name = "mistral-deployment" ,
enable_restful_api = True ,
restful_api_port = 28080 ,
) - หมายเหตุ: ในขณะที่การให้ deployment_name ไม่จำเป็น (MII จะ autogenerate หนึ่งสำหรับคุณ) มันเป็นวิธีปฏิบัติที่ดีในการจัดหา deployment_name เพื่อให้คุณสามารถมั่นใจได้ว่าคุณจะเชื่อมต่อกับ API ที่ถูกต้องที่ถูกต้อง
จากนั้นคุณสามารถส่งพรอมต์ไปยังเกตเวย์ restful ด้วยไคลเอนต์ HTTP ใด ๆ เช่น curl :
curl --header " Content-Type: application/json " --request POST -d ' {"prompts": ["DeepSpeed is", "Seattle is"], "max_length": 128} ' http://localhost:28080/mii/mistral-deployment หรือ python :
import json
import requests
url = f"http://localhost:28080/mii/mistral-deployment"
params = { "prompts" : [ "DeepSpeed is" , "Seattle is" ], "max_length" : 128 }
json_params = json . dumps ( params )
output = requests . post (
url , data = json_params , headers = { "Content-Type" : "application/json" }
)ในขณะที่มีเพียงชื่อโมเดลหรือเส้นทางที่จำเป็นในการยืนการปรับใช้อย่างต่อเนื่องเราเสนอตัวเลือกการปรับแต่งให้กับผู้ใช้ของเรา
ตัวเลือก mii.serve() :
model_name_or_path: str (จำเป็น) ชื่อหรือเส้นทางท้องถิ่นไปยังโมเดล HuggingFacemax_length: int (ค่าเริ่มต้นเป็นความยาวลำดับสูงสุดในการกำหนดค่ารุ่น) ตั้งค่าความยาวโทเค็นสูงสุดเริ่มต้นสำหรับการตอบกลับ +deployment_name: str (ค่าเริ่มต้นเป็น f"{model_name_or_path}-mii-deployment" ) สตริงการระบุที่ไม่ซ้ำกันสำหรับโมเดลถาวร หากมีให้ควรเรียกคืนวัตถุไคลเอนต์ด้วย client = mii.client(deployment_name)tensor_parallel: int (ค่าเริ่มต้นถึง 1 ) จำนวน GPU เพื่อแยกโมเดลข้ามreplica_num: int (ค่าเริ่มต้นถึง 1 ) จำนวนของแบบจำลองจำลองที่จะยืนขึ้นenable_restful_api: bool (ค่าเริ่มต้นเป็น False ) เมื่อเปิดใช้งานกระบวนการ API เกตเวย์ RESTFUL จะถูกเปิดตัวที่สามารถสอบถามได้ที่ http://{host}:{restful_api_port}/mii/{deployment_name} ดูหัวข้อเกี่ยวกับ RESTFUL APIs สำหรับรายละเอียดเพิ่มเติมrestful_api_port: int (ค่าเริ่มต้นถึง 28080 ) หมายเลขพอร์ตที่ใช้ในการเชื่อมต่อกับ RESTFUL API เมื่อ enable_restful_api ถูกตั้งค่าเป็น True ตัวเลือก mii.client() :
model_or_deployment_name: str ชื่อของโมเดลหรือ deployment_name ส่งผ่านไปยัง mii.serve() ผู้ใช้ยังสามารถควบคุมคุณสมบัติการสร้างสำหรับพรอมต์แต่ละรายการ (เช่นเมื่อโทรหา client.generate() ) ด้วยตัวเลือกต่อไปนี้:
max_length: int ตั้งค่าความยาวโทเค็นสูงสุดต่อการฉายสำหรับการตอบสนอง +min_new_tokens: int ตั้งค่าจำนวนโทเค็นขั้นต่ำที่สร้างขึ้นในการตอบสนอง max_length จะมีความสำคัญกว่าการตั้งค่านี้max_new_tokens: int ตั้งค่าจำนวนสูงสุดของโทเค็นที่สร้างขึ้นในการตอบสนองignore_eos: bool (ค่าเริ่มต้นเป็น False ) การตั้งค่าเป็น True ป้องกันการสร้างจากการสิ้นสุดเมื่อพบโทเค็น EOStop_p: float (ค่าเริ่มต้นเป็น 0.9 ) เมื่อตั้งค่าต่ำกว่า 1.0 , โทเค็นตัวกรองและรักษาความน่าจะเป็นมากที่สุดโดยที่ความน่าจะเป็นโทเค็นรวมเป็น≥ top_ptop_k: int (ค่าเริ่มต้นถึง None ) เมื่อ None การกรอง Top-K จะถูกปิดใช้งาน เมื่อตั้งค่าจำนวนโทเค็นความน่าจะเป็นสูงสุดที่จะเก็บไว้temperature: float (ค่าเริ่มต้นถึง None ) เมื่อ None อุณหภูมิจะถูกปิดใช้งาน เมื่อตั้งค่าให้ปรับเปลี่ยนความน่าจะเป็นโทเค็นdo_sample: bool (ค่าเริ่มต้นเป็น True ) เมื่อ True บันทึกเอาต์พุตตัวอย่าง เมื่อ False ให้ใช้การสุ่มตัวอย่างโลภreturn_full_text: bool False Trueโครงการนี้ยินดีต้อนรับการมีส่วนร่วมและข้อเสนอแนะ การมีส่วนร่วมส่วนใหญ่กำหนดให้คุณต้องยอมรับข้อตกลงใบอนุญาตผู้มีส่วนร่วม (CLA) ประกาศว่าคุณมีสิทธิ์และทำจริงให้สิทธิ์ในการใช้การบริจาคของคุณ สำหรับรายละเอียดเยี่ยมชม https://cla.opensource.microsoft.com
เมื่อคุณส่งคำขอดึง CLA บอทจะพิจารณาโดยอัตโนมัติว่าคุณจำเป็นต้องให้ CLA และตกแต่ง PR อย่างเหมาะสม (เช่นการตรวจสอบสถานะแสดงความคิดเห็น) เพียงทำตามคำแนะนำที่จัดทำโดยบอท คุณจะต้องทำสิ่งนี้เพียงครั้งเดียวใน repos ทั้งหมดโดยใช้ CLA ของเรา
โครงการนี้ได้นำรหัสการดำเนินงานของ Microsoft โอเพ่นซอร์สมาใช้ สำหรับข้อมูลเพิ่มเติมโปรดดูจรรยาบรรณคำถามที่พบบ่อยหรือติดต่อ [email protected] พร้อมคำถามหรือความคิดเห็นเพิ่มเติมใด ๆ
โครงการนี้อาจมีเครื่องหมายการค้าหรือโลโก้สำหรับโครงการผลิตภัณฑ์หรือบริการ การใช้เครื่องหมายการค้าหรือโลโก้ของ Microsoft ที่ได้รับอนุญาตขึ้นอยู่กับและต้องปฏิบัติตามแนวทางเครื่องหมายการค้าและแบรนด์ของ Microsoft การใช้เครื่องหมายการค้าหรือโลโก้ของ Microsoft ในรุ่นที่แก้ไขของโครงการนี้จะต้องไม่ทำให้เกิดความสับสนหรือบอกเป็นสปอนเซอร์ของ Microsoft การใช้เครื่องหมายการค้าหรือโลโก้ของบุคคลที่สามจะอยู่ภายใต้นโยบายของบุคคลที่สามเหล่านั้น


