voicefilter
1.0.0
大家好!這是Minds Lab,Inc。的Seung-Won。自從我發布此開源以來已經很長時間了,我沒想到這個存儲庫會在很長一段時間內引起如此大量的關注。我要感謝大家給予瞭如此關注,以及Quan Wang先生(VoiceFilter論文的第一作者)在他的論文中轉介該項目。
實際上,當我開始在沒有相關領域的主管的情況下研究深度學習和語音分離僅3個月後,我就完成了這個項目。那時,我不知道什麼是冪律壓縮,也不知道驗證/測試模型的正確方法。現在,我已經花了更多時間在深度學習和演講上(我還寫了一篇在Interspeech 2020上發表的論文?),我可以觀察到一些明顯的錯誤。這些問題是由GitHub用戶友好地提出的。請參閱問題並提取請求。話雖這麼說,這個存儲庫可能非常不可靠,我想提醒所有人使用此代碼以自身的風險(如許可證中指定)。
不幸的是,我負擔不起修改該項目或審查問題 /拉的請求的額外時間。相反,我想為新的,更可靠的資源提供一些指示:
感謝您的閱讀,我希望在全球大流行狀況中每個人都身體狀況良好。
最好的問候,Seung-Won公園
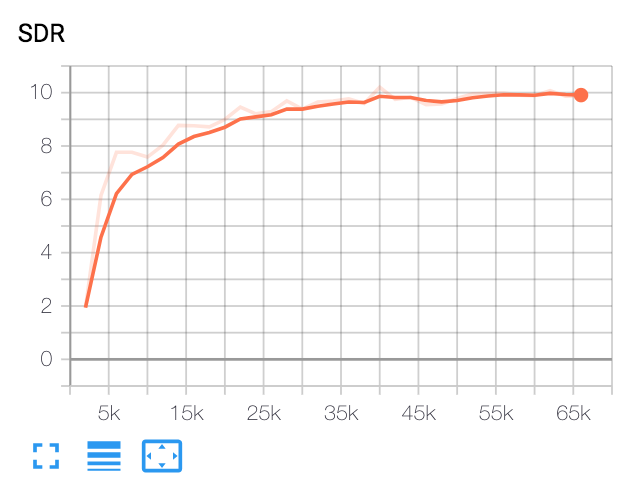
Google AI的非正式Pytorch實現:語音窗體:通過揚聲器條件的頻譜圖掩蔽的有針對性的語音分離。
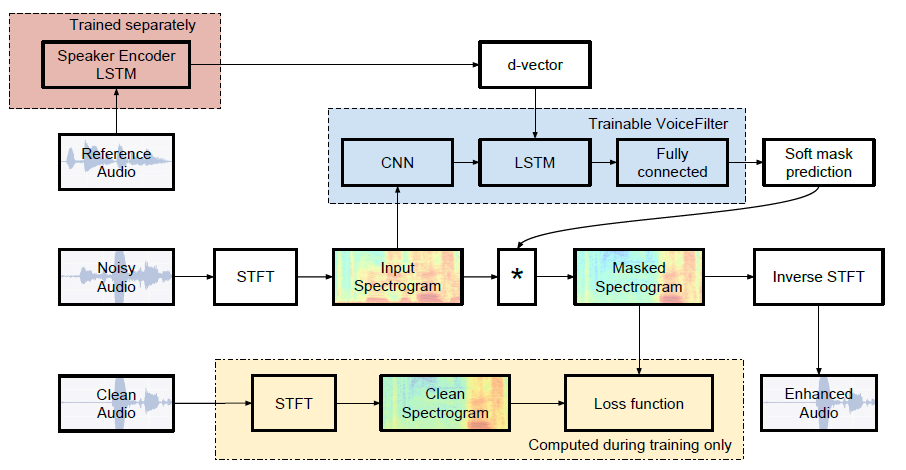
| 中位SDR | 紙 | 我們的 |
|---|---|---|
| 在VoiceFilter之前 | 2.5 | 1.9 |
| 語音窗口之後 | 12.6 | 10.2 |
Python和包裝
該代碼在Pytorch 1.0.1上在Python 3.6上進行了測試。其他軟件包可以通過:
pip install -r requirements.txt各種各樣的
ffmpeg kormalize用於重新採樣和標準化WAV文件。請參閱ffmpeg normalize的readme.md以進行安裝。
下載LibrisPeech數據集
要復制VoiceFilter紙,請在http://www.opensl.org/12/上獲取LibrisPeech數據集。 train-clear-100.tar.gz (6.3g)包含252名演講者的演講,而train-clear-360.tar.gz (23G)包含922位揚聲器。您也可以使用,但是在數據集中使用的揚聲器越多,語音窗口就會越好。
重新採樣和標準化WAV文件
首先,將tar.gz文件解放到所需文件夾:
tar -xvzf train-clear-360.tar.gz接下來,將utils/normalize-resample.sh複製到未拉鍊數據文件夾的根目錄。然後:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long編輯config.yaml
cd config
cp default.yaml config.yaml
vim config.yaml預處理WAV文件
為了提高訓練速度,請在培訓之前對每個文件執行STFT:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]這將創建100,000(火車) + 1000(測試)數據。 (約160克)
獲得辯護的揚聲器識別系統模型
VoiceFilter使用揚聲器識別系統(D-Vector嵌入)。在這裡,我們提供了獲得D-vector嵌入的驗證模型。
該模型是使用Voxceleb2數據集訓練的,在該數據集中,話語隨機長度[70,90]幀隨機擬合。測試是用窗口80 / hop 40進行的,並且顯示出相等的錯誤率約為1%。從Voxceleb1測試數據集的前8位揚聲器中選擇了用於測試的數據,其中每個說話者都會隨機選擇10個話語。
更新:對Voxceleb1選定對的評估顯示7.4%EER。
該模型可以在此GDRIVE鏈接上下載。
跑步
指定train_dir後, config.yaml的test_dir ,運行:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name]這將在基本目錄中創建chkpt/name和logs/name ( -b選項, .默認為。)
查看TensorBoardX
tensorboard --logdir ./logs
從檢查點恢復
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Mindslab([email protected],[email protected])的Seungwon Park
Apache許可證2.0
該存儲庫包含從以下內容中改編/複製的代碼:


