voicefilter
1.0.0
안녕하세요 여러분! Minds Lab, Inc.의 Seung-Won입니다.이 오픈 소스를 발표 한 지 오래되었습니다.이 저장소가 오랫동안 많은 관심을 끌기를 기대하지 않았습니다. 나는 그러한 관심을 기울여 주신 모든 분들 과이 프로젝트를 그의 논문에서 추천 한 Quan Wang (Voicefilter Paper의 첫 번째 저자)에게 감사의 말씀을 전합니다.
실제로,이 프로젝트는 관련 분야의 감독자없이 딥 러닝 및 연설 분리를 공부하기 시작한 지 3 개월 만에 이루어졌습니다. 당시에는 전력 법률 압축이 무엇인지, 모델을 검증/테스트하는 올바른 방법을 몰랐습니다. 그 이후로 딥 러닝 및 연설에 더 많은 시간을 보냈으므로 (나는 또한 Interspeech 2020에 출판 된 논문을 썼습니까?), 내가 저지른 몇 가지 명백한 실수를 관찰 할 수 있습니다. 이러한 문제는 Github 사용자에 의해 친절하게 제기되었습니다. 문제를 참조하고 요청을 가져 오십시오. 즉,이 저장소는 상당히 신뢰할 수 없을 수 있으며, 라이센스에 지정된대로 모든 사람 이이 코드를 자신의 위험으로 사용하도록 상기시키고 싶습니다.
불행히도, 나는이 프로젝트를 수정하거나 문제 / 풀 요청을 검토하는 데 추가 시간을 감당할 수 없습니다. 대신, 나는보다 새롭고 신뢰할 수있는 리소스에 몇 가지 포인터를 제공하고 싶습니다.
읽어 주셔서 감사합니다. 전 세계 유행성 상황에서 모든 사람들이 건강을 기원합니다.
그 안부, 승록 공원
Google AI의 비공식 Pytorch 구현 : VoiceFilter : 스피커 조절 된 스펙트로 그램 마스킹에 의한 대상 음성 분리.
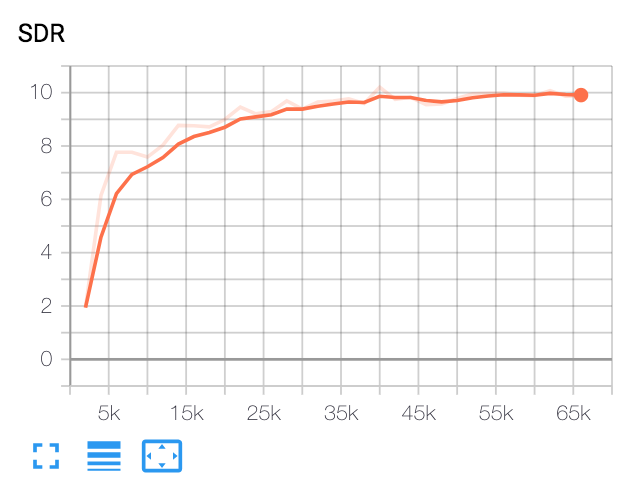
| 중앙 SDR | 종이 | 우리 것 |
|---|---|---|
| VoiceFilter 전에 | 2.5 | 1.9 |
| VoiceFilter 후 | 12.6 | 10.2 |
파이썬 및 패키지
이 코드는 Pytorch 1.0.1을 사용하여 Python 3.6에서 테스트되었습니다. 다른 패키지는 다음과 같이 설치할 수 있습니다.
pip install -r requirements.txt여러 가지 잡다한
FFMPEG-Normanimes는 WAV 파일을 리샘플링하고 정규화하는 데 사용됩니다. 설치하려면 FFMPEG-NARMILATE의 ReadMe.Md를 참조하십시오.
LibrisPeech 데이터 세트를 다운로드하십시오
VoiceFilter 용지를 복제하려면 http://www.openslr.org/12/에서 librispeech 데이터 세트를 가져옵니다. train-clear-100.tar.gz (6.3g)에는 252 개의 스피커가 포함되어 있으며 train-clear-360.tar.gz (23g)에는 922 개의 스피커가 포함되어 있습니다. 둘 중 하나를 사용할 수 있지만 데이터 세트에 스피커가 많을수록 더 나은 VoiceFilter가 더 좋습니다.
WAV 파일을 재 샘플 및 정상화하십시오
먼저 원하는 폴더로 zip tar.gz 파일 :
tar -xvzf train-clear-360.tar.gz 다음으로 utils/normalize-resample.sh 압축 된 데이터 폴더의 루트 디렉토리로 복사하십시오. 그 다음에:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long config.yaml 편집
cd config
cp default.yaml config.yaml
vim config.yaml전처리 wav 파일
교육 속도를 높이려면 교육 전에 각 파일에 대한 STFT를 수행하십시오.
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]이렇게하면 100,000 (기차) + 1000 (테스트) 데이터가 생성됩니다. (약 160g)
스피커 인식 시스템을위한 사전 예방 모델을 얻으십시오
VoiceFilter는 스피커 인식 시스템 (D- 벡터 임베드)을 사용합니다. 여기서, 우리는 d- 벡터 임베딩을 얻기위한 사전 고정 된 모델을 제공합니다.
이 모델은 VoxceleB2 데이터 세트로 훈련되었으며, 여기서 발화는 무작위로 시간 길이에 적합합니다 [70, 90] 프레임. 테스트는 Window 80 / Hop 40으로 수행되며 약 1%동일한 오류율을 보여주었습니다. 테스트에 사용 된 데이터는 Voxceleb1 테스트 데이터 세트의 첫 8 개의 스피커에서 선택되었으며, 각 스피커 당 10 개의 발언이 무작위로 선택됩니다.
업데이트 : VoxcelEB1 선택된 쌍에 대한 평가는 7.4% EER을 보여주었습니다.
이 GDRIVE 링크에서 모델을 다운로드 할 수 있습니다.
달리다
train_dir 지정한 후 config.yaml 에서 test_dir , run :
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] 이렇게하면 Base Directory ( -b 옵션, . 기본값)에서 chkpt/name 및 logs/name 생성됩니다.
Tensorboardx를 봅니다
tensorboard --logdir ./logs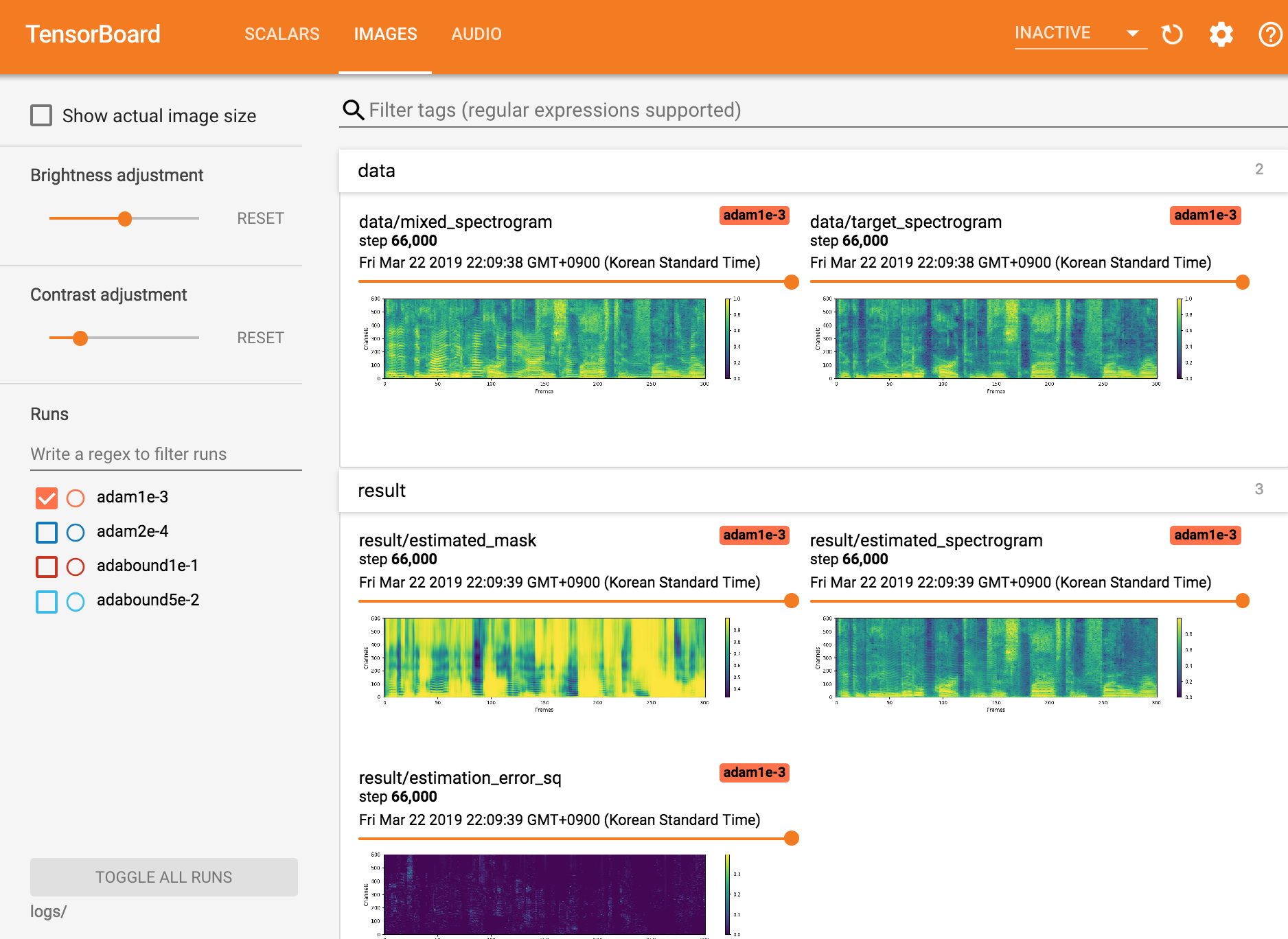
체크 포인트에서 재개
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Mindslab의 Seungwon Park ([email protected], [email protected])
아파치 라이센스 2.0
이 저장소에는 다음과 같은 내용에서 적응/복사 된 코드가 포함되어 있습니다.


