voicefilter
1.0.0
やあみんな! Minds Lab、IncのSeung-Wonです。このオープンソースをリリースしてから長い時間が経ちましたが、このリポジトリが長い間このような注目を集めるとは思っていませんでした。このような注意を払ってくれたすべての人に感謝したいと思います。また、このプロジェクトを彼の論文で紹介してくれたQuan Wang氏(VoiceFilter Paperの最初の著者)も感謝したいと思います。
実際、このプロジェクトは、関連分野の監督者なしで深い学習と音声分離の勉強を始めてからわずか3か月後に行われたときに私によって行われました。当時、私はパワーローの圧縮が何であるか、モデルを検証/テストする正しい方法を知りませんでした。それ以来、深い学習とスピーチにもっと時間を費やしたので(Speech 2020で公開された論文も書きました)、私が犯したいくつかの明らかな間違いを観察できます。これらの問題は、GitHubユーザーによって親切に提起されました。問題を参照して、そのリクエストをプルしてください。そうは言っても、このリポジトリは非常に信頼できない可能性があります。私は、このコードを自分の責任で(ライセンスで指定して)使用するように全員に思い出させたいと思います。
残念ながら、このプロジェクトの改訂や問題 /プルリクエストのレビューに余分な時間を費やすことはできません。代わりに、より新しい、より信頼性の高いリソースにいくつかのポインターを提供したいと思います。
読んでくれてありがとう、そして私は世界的なパンデミックの状況の間にみんなが健康であることを願っています。
よろしく、スンウォンパーク
Google AIの非公式のPytorch実装:VoiceFilter:Speaker-Conditioned Spectrogramマスキングによるターゲット音声分離。
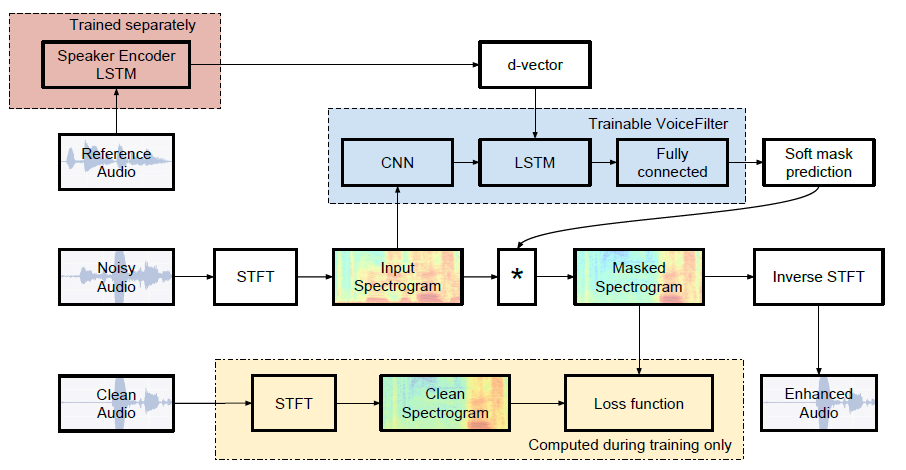
| 中央値SDR | 紙 | 私たちのもの |
|---|---|---|
| VoiceFilterの前 | 2.5 | 1.9 |
| VoiceFilterの後 | 12.6 | 10.2 |
Pythonとパッケージ
このコードは、Pytorch 1.0.1でPython 3.6でテストされました。他のパッケージは以下でインストールできます。
pip install -r requirements.txtその他
FFMPEG-Normalizeは、WAVファイルの再サンプリングと正規化に使用されます。インストールについては、ffmpeg-normalizeのreadme.mdを参照してください。
Librispeechデータセットをダウンロードします
VoiceFilter Paperを複製するには、http://www.openslr.org/12/でLibrispeechデータセットを入手してください。 train-clear-100.tar.gz (6.3g)には252人のスピーカーの音声が含まれており、 train-clear-360.tar.gz (23g)には922人のスピーカーが含まれています。どちらも使用できますが、データセットにあるスピーカーが多いほど、より良いVoiceFilterになります。
WAVファイルを再サンプリングして正規化します
まず、目的のフォルダーへのtar.gzファイルを解凍します。
tar -xvzf train-clear-360.tar.gz次に、 utils/normalize-resample.sh解凍したデータフォルダーのルートディレクトリにコピーします。それから:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long config.yamlを編集します
cd config
cp default.yaml config.yaml
vim config.yamlプリプロセスWAVファイル
トレーニング速度を上げるには、トレーニング前に各ファイルのSTFTを実行します。
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]これにより、100,000(列車) + 1000(テスト)データが作成されます。 (約160g)
スピーカー認識システムの前提型モデルを取得します
VoiceFilterは、スピーカー認識システム(D-Vector Embeddings)を使用します。ここでは、Dベクトル埋め込みを取得するための前提型モデルを提供します。
このモデルは、VoxceleB2データセットでトレーニングされました。このモデルでは、発話は時間の長さにランダムに適合します[70、90]フレームがあります。テストはウィンドウ80 /ホップ40で行われ、等しいエラー率は約1%を示しています。テストに使用されるデータは、VoxceleB1テストデータセットの最初の8つのスピーカーから選択されました。各スピーカーごとに10の発話がランダムに選択されています。
更新:VoxceleB1選択したペアの評価は7.4%EERを示しました。
このモデルは、このGDRIVEリンクでダウンロードできます。
走る
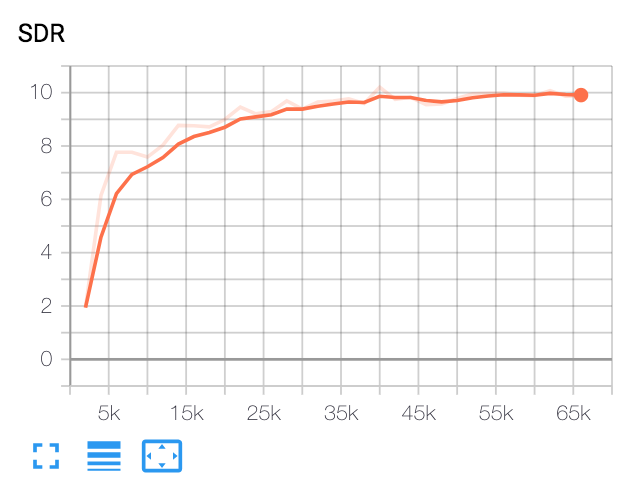
config.yamlでtrain_dirを指定した後、 test_dir 、run:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name]これにより、baseディレクトリ( -bオプション、 .デフォルト)でchkpt/nameとlogs/nameが作成されます
tensorboardxを表示します
tensorboard --logdir ./logs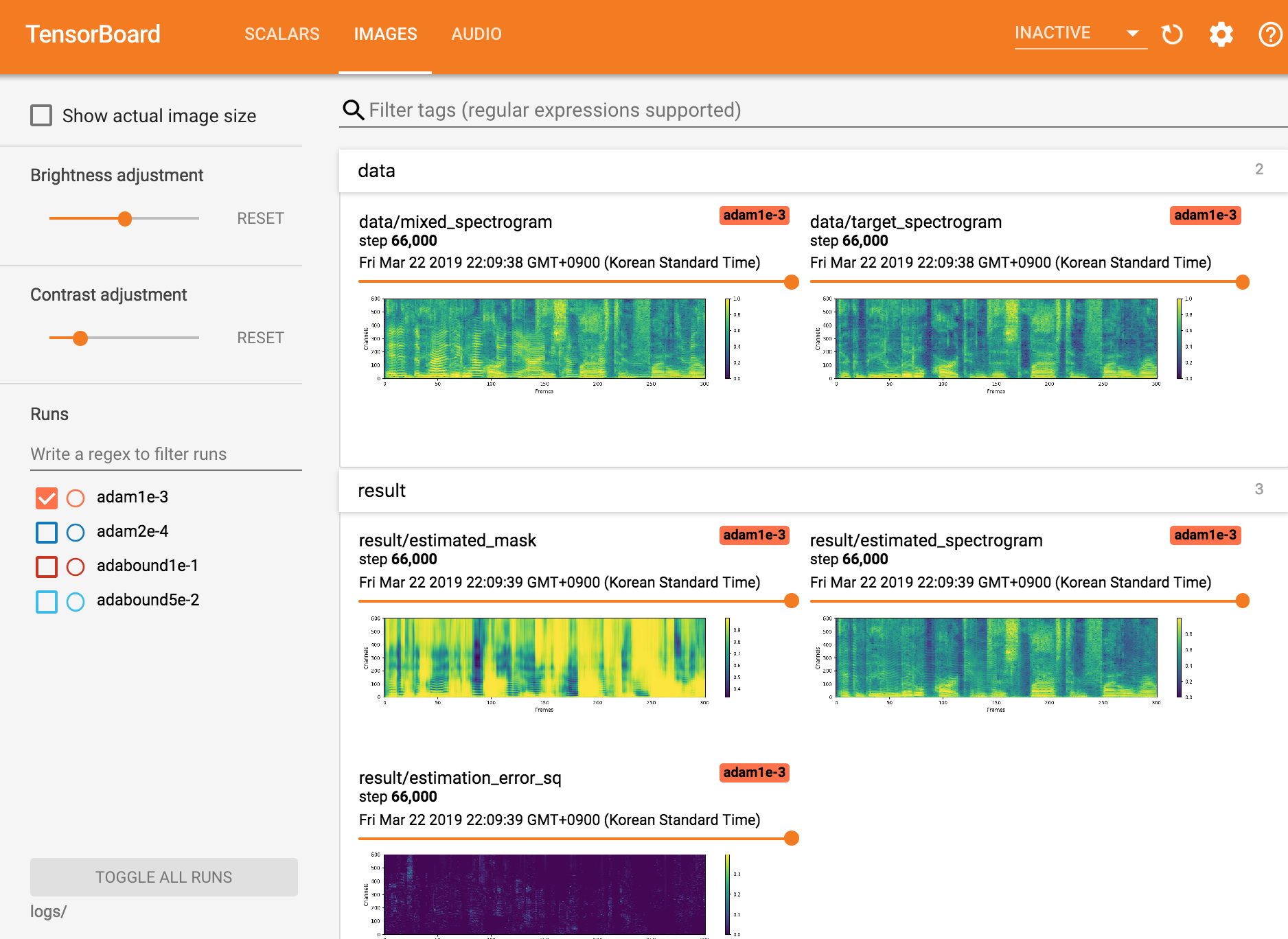
チェックポイントから再開します
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]MindslabのSeungwon Park([email protected]、[email protected])
Apacheライセンス2.0
このリポジトリには、以下から採用/コピーされたコードが含まれています。


