voicefilter
1.0.0
Oi pessoal! É Seung-Won da Minds Lab, Inc. Faz muito tempo desde que lançei esse código aberto, e não esperava que esse repositório chamasse uma grande atenção por um longo tempo. Gostaria de agradecer a todos por dar tanta atenção, e também o Sr. Quan Wang (o primeiro autor do The Boyfilter Paper) por encaminhar este projeto em seu artigo.
Na verdade, esse projeto foi feito por mim quando foram apenas três meses depois que eu comecei a estudar profundamente aprendizado e separação de fala sem um supervisor no campo relevante. Naquela época, eu não sabia o que é uma compactação de direito de potência e a maneira correta de validar/testar os modelos. Agora que passei mais tempo em Deep Learning & Discury desde então (também escrevi um artigo publicado no Interspeech 2020?), Observo alguns erros óbvios que cometi. Essas questões foram gentilmente levantadas pelos usuários do GitHub; Consulte os problemas e puxe solicitações para isso. Dito isto, esse repositório pode ser bastante confiável, e eu gostaria de lembrar a todos que usem esse código por seu próprio risco (conforme especificado na licença).
Infelizmente, não posso pagar um tempo extra para revisar este projeto ou revisar os problemas / solicitações de tração. Em vez disso, gostaria de oferecer algumas dicas a recursos mais novos e confiáveis:
Obrigado pela leitura, e desejo a todos uma boa saúde durante a situação global da pandemia.
Atenciosamente, Seung-Won Park
Implementação não oficial de Pytorch do Google AI: Filter de voz: separação de voz direcionada por máscara de espectrograma condicionada ao alto-falante.
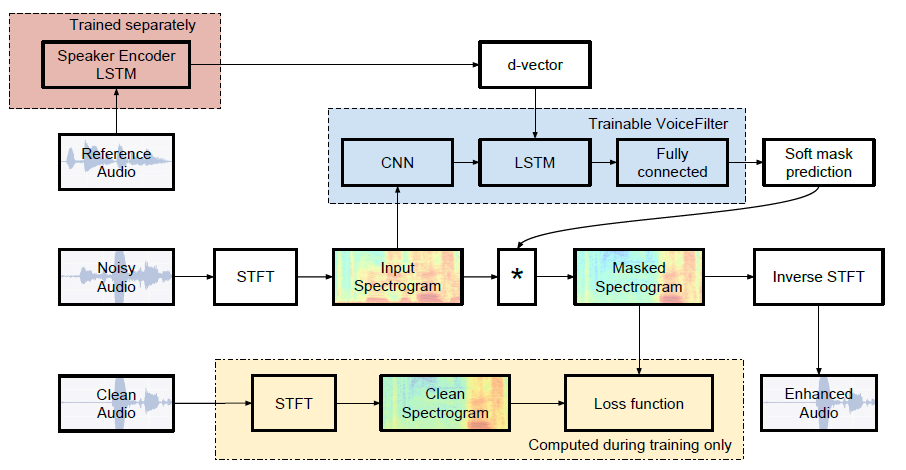
| SDR mediano | Papel | Nosso |
|---|---|---|
| Antes do botefilter | 2.5 | 1.9 |
| Depois do botefilter | 12.6 | 10.2 |
Python e pacotes
Este código foi testado no Python 3.6 com Pytorch 1.0.1. Outros pacotes podem ser instalados por:
pip install -r requirements.txtVariado
FFMPEG Normalize é usado para reamostragem e normalização de arquivos WAV. Consulte ReadMe.md do FFMPEG Normalize para instalação.
Faça o download do conjunto de dados Librispeech
Para replicar o papel do botefilter, obtenha o conjunto de dados da Librispeech em http://www.openslr.org/12/. train-clear-100.tar.gz (6.3g) contém fala de 252 alto-falantes, e train-clear-360.tar.gz (23g) contém 922 alto-falantes. Você pode usar, mas quanto mais alto -falantes você tiver no conjunto de dados, mais otfilter mais melhor será.
Resamme e normalize os arquivos WAV
Primeiro, o arquivo tar.gz da pasta desejada:
tar -xvzf train-clear-360.tar.gz Em seguida, copie utils/normalize-resample.sh para o diretório raiz da pasta de dados descompactada. Então:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long Editar config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlArquivos WAV de pré -processo
Para aumentar a velocidade de treinamento, execute o STFT para cada arquivo antes de treinar por:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]Isso criará dados de 100.000 (trem) + 1000 (teste). (Cerca de 160g)
Obtenha o modelo pré -terenciado para o sistema de reconhecimento de alto -falantes
O botefilter utiliza o sistema de reconhecimento de alto-falantes (incorporação de vetor D). Aqui, fornecemos um modelo pré-terenciado para obter incorporações de vetor D.
Este modelo foi treinado com o conjunto de dados do VoxceleB2, onde as enunciados são adequados ao comprimento do tempo [70, 90]. Os testes são feitos com a janela 80 / Hop 40 e mostraram uma taxa de erro igual a cerca de 1%. Os dados utilizados para teste foram selecionados entre os 8 primeiros alto -falantes do conjunto de dados de teste VoxceleB1, onde 10 enunciados por cada falante são selecionados aleatoriamente.
ATUALIZAÇÃO : Avaliação no par selecionada do VoxceleB1 mostrou 7,4% eer.
O modelo pode ser baixado neste link de gdrive.
Correr
Depois de especificar train_dir , test_dir em config.yaml , execute:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] Isso criará chkpt/name e logs/name no diretório base ( -b opção , . no padrão)
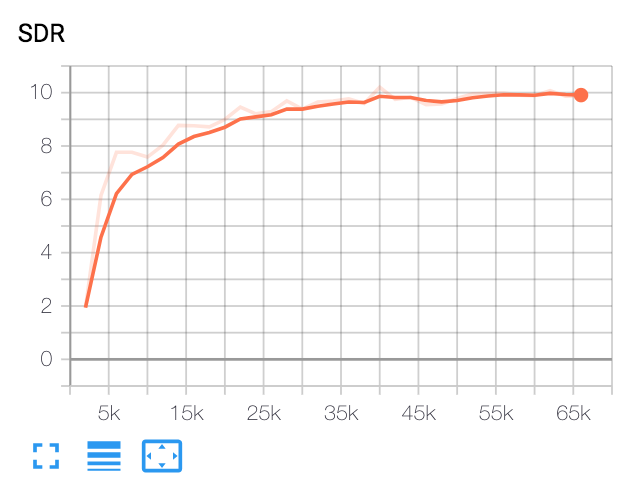
Ver Tensorboardx
tensorboard --logdir ./logs
Retomando do ponto de verificação
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Seungwon Park at Mindslab ([email protected], [email protected])
Licença Apache 2.0
Este repositório contém códigos adaptados/copiados dos seguintes:


