voicefilter
1.0.0
Всем привет! Это Seung-Won From Minds Lab, Inc. Прошло много времени с тех пор, как я выпустил этот открытый источник, и я не ожидал, что этот репозиторий долго привлечет такое большое внимание. Я хотел бы поблагодарить всех за такое внимание, а также мистер Куан Ван (первый автор газеты VoiceFilter) за то, что он направил этот проект в его статье.
На самом деле, этот проект был проведен мной, когда было всего через 3 месяца после того, как я начал изучать глубокое обучение и разделение речи без руководителя в соответствующей области. В то время я не знал, что такое сжатие в сфере власти, и правильный способ проверки/проверки моделей. Теперь, когда я потратил больше времени на глубокое обучение и речь с тех пор (я также написал статью, опубликованную в межспинке 2020?), Я могу наблюдать некоторые очевидные ошибки, которые я сделал. Эти проблемы были любезно подняты пользователями GitHub; Пожалуйста, обратитесь к вопросам и обращайте запросов на это. При этом этот репозиторий может быть довольно ненадежным, и я хотел бы напомнить каждому, чтобы они использовали этот код на свой собственный риск (как указано в лицензии).
К сожалению, я не могу позволить себе дополнительное время для пересмотра этого проекта или просмотра вопросов / запросов. Вместо этого я хотел бы предложить некоторые указатели на более новые, более надежные ресурсы:
Спасибо за чтение, и я желаю всем хорошего здоровья во время глобальной пандемической ситуации.
С уважением, Парк Сын-Вон
Неофициальная реализация Pytorch of Google AI: Voicefilter: Целевое разделение голоса посредством маскировки спектрограммы.
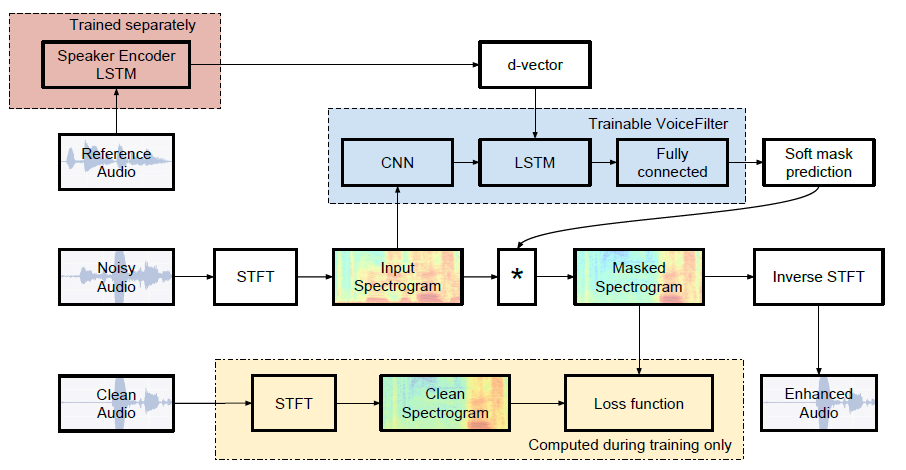
| Медиана SDR | Бумага | Наш |
|---|---|---|
| Перед голосовымфильтер | 2.5 | 1.9 |
| после голосового фантазии | 12.6 | 10.2 |
Питон и пакеты
Этот код был протестирован на Python 3.6 с Pytorch 1.0.1. Другие пакеты могут быть установлены:
pip install -r requirements.txtРазнообразный
FFMPEG-Normalaze используется для повторной выборки и нормализации файлов WAV. См. Readme.md ffmpeg-Normalaze для установки.
Скачать набор данных Librispeech
Чтобы повторить бумагу VoiceFilter, получите набор данных Librispeech по адресу http://www.openslr.org/12/. train-clear-100.tar.gz (6.3g) содержит речь 252 динамиков, а train-clear-360.tar.gz (23g) содержит 922 динамика. Вы можете использовать либо, но чем больше динамиков у вас есть в наборе данных, тем лучше будет голосовой фильтер.
Повторно повторно и нормализовать файлы wav
Во -первых, файл Unzip tar.gz в нужную папку:
tar -xvzf train-clear-360.tar.gz Затем скопируйте utils/normalize-resample.sh в корневой каталог неразличимых папки данных. Затем:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long Редактировать config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlPreprocess WAV -файлы
Чтобы повысить скорость обучения, выполните STFT для каждого файла, прежде чем тренировать:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]Это создаст 100 000 данных (поезда) + 1000 (тест). (Около 160 г)
Получить предварительную модель для системы распознавания динамиков
VoiceFilter использует систему распознавания динамиков (D-векторные встраивания). Здесь мы предоставляем предварительную модель для получения D-векторов.
Эта модель была обучена набору данных VoxCeleb2, где высказывания случайным образом соответствуют длине времени [70, 90] кадров. Тесты выполняются с окном 80 / HOP 40 и показали равную частоту ошибок примерно на 1%. Данные, используемые для тестирования, были выбраны из первых 8 динамиков набора тестирования Voxceleb1, где 10 высказываний на каждый динамик выбраны случайным образом.
Обновление : оценка на выбранной паре Voxceleb1 показала 7,4% EER.
Модель может быть загружена по этой ссылке GDRIVE.
Бегать
После указания train_dir , test_dir at config.yaml , запустите:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] Это создаст chkpt/name и logs/name в Base Directory ( -b опция . По умолчанию)
Посмотреть Tensorboardx
tensorboard --logdir ./logs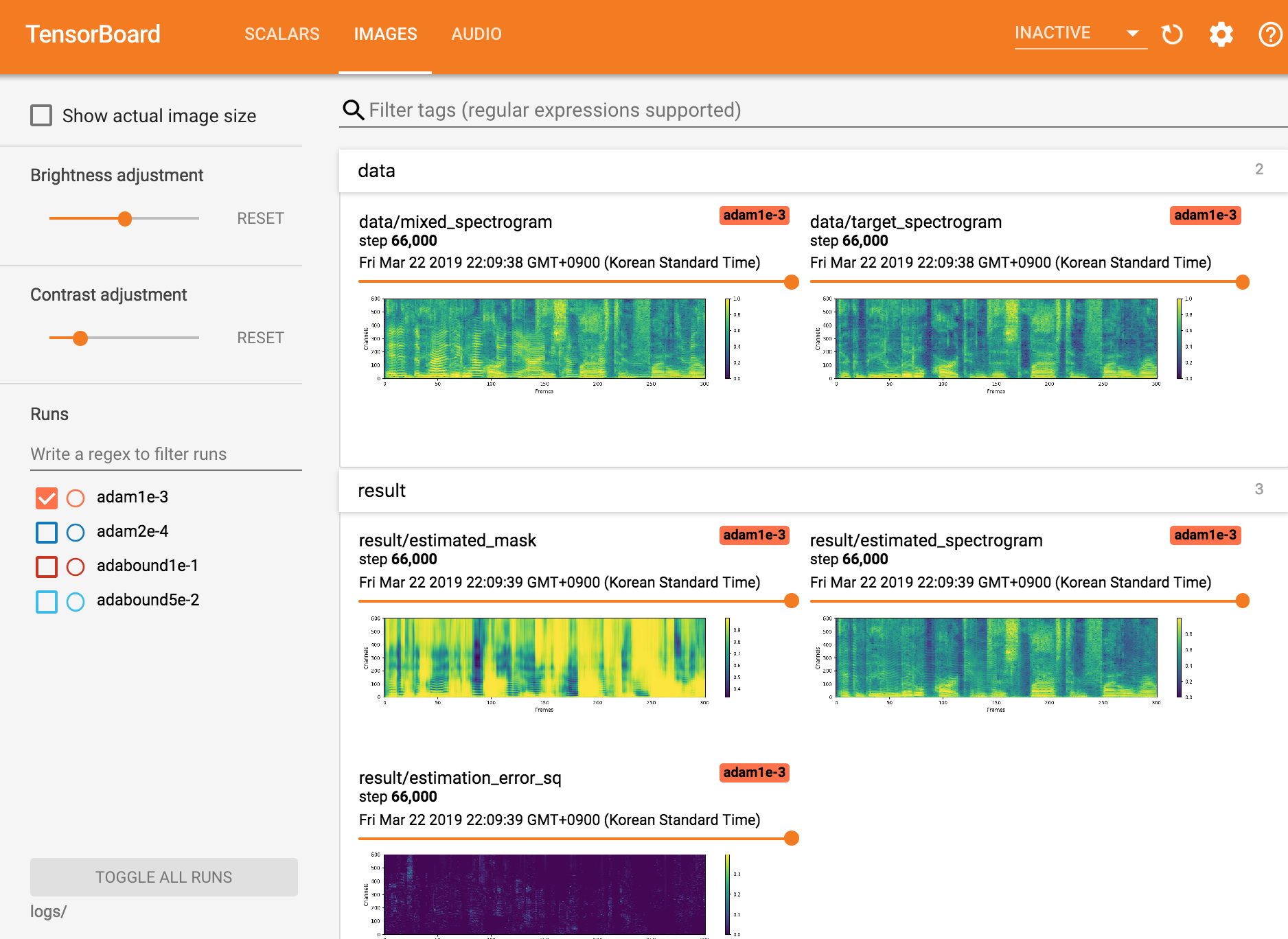
Возобновляя с контрольной точки
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Seungwon Park в Mindslab ([email protected], [email protected])
Apache License 2.0
Этот репозиторий содержит коды, адаптированные/скопированные из последующих действий:


