voicefilter
1.0.0
大家好!这是Minds Lab,Inc。的Seung-Won。自从我发布此开源以来已经很长时间了,我没想到这个存储库会在很长一段时间内引起如此大量的关注。我要感谢大家给予了如此关注,以及Quan Wang先生(VoiceFilter论文的第一作者)在他的论文中转介该项目。
实际上,当我开始在没有相关领域的主管的情况下研究深度学习和语音分离仅3个月后,我就完成了这个项目。那时,我不知道什么是幂律压缩,也不知道验证/测试模型的正确方法。现在,我已经花了更多时间在深度学习和演讲上(我还写了一篇在Interspeech 2020上发表的论文?),我可以观察到一些明显的错误。这些问题是由GitHub用户友好地提出的。请参阅问题并提取请求。话虽这么说,这个存储库可能非常不可靠,我想提醒所有人使用此代码以自身的风险(如许可证中指定)。
不幸的是,我负担不起修改该项目或审查问题 /拉的请求的额外时间。相反,我想为新的,更可靠的资源提供一些指示:
感谢您的阅读,我希望在全球大流行状况中每个人都身体状况良好。
最好的问候,Seung-Won公园
Google AI的非正式Pytorch实现:语音窗体:通过扬声器条件的频谱图掩蔽的有针对性的语音分离。
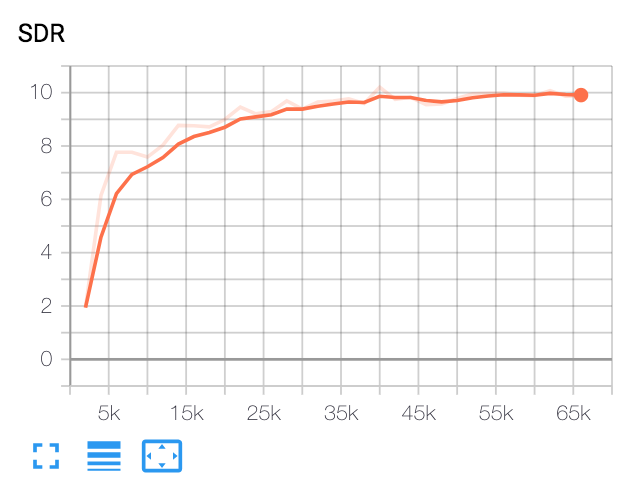
| 中位SDR | 纸 | 我们的 |
|---|---|---|
| 在VoiceFilter之前 | 2.5 | 1.9 |
| 语音窗口之后 | 12.6 | 10.2 |
Python和包装
该代码在Pytorch 1.0.1上在Python 3.6上进行了测试。其他软件包可以通过:
pip install -r requirements.txt各种各样的
ffmpeg kormalize用于重新采样和标准化WAV文件。请参阅ffmpeg normalize的readme.md以进行安装。
下载LibrisPeech数据集
要复制VoiceFilter纸,请在http://www.opensl.org/12/上获取LibrisPeech数据集。 train-clear-100.tar.gz (6.3g)包含252名演讲者的演讲,而train-clear-360.tar.gz (23G)包含922位扬声器。您也可以使用,但是在数据集中使用的扬声器越多,语音窗口就会越好。
重新采样和标准化WAV文件
首先,将tar.gz文件解放到所需文件夹:
tar -xvzf train-clear-360.tar.gz接下来,将utils/normalize-resample.sh复制到未拉链数据文件夹的根目录。然后:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long编辑config.yaml
cd config
cp default.yaml config.yaml
vim config.yaml预处理WAV文件
为了提高训练速度,请在培训之前对每个文件执行STFT:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]这将创建100,000(火车) + 1000(测试)数据。 (约160克)
获得辩护的扬声器识别系统模型
VoiceFilter使用扬声器识别系统(D-Vector嵌入)。在这里,我们提供了获得D-vector嵌入的验证模型。
该模型是使用Voxceleb2数据集训练的,在该数据集中,话语随机长度[70,90]帧随机拟合。测试是用窗口80 / hop 40进行的,并且显示出相等的错误率约为1%。从Voxceleb1测试数据集的前8位扬声器中选择了用于测试的数据,其中每个说话者都会随机选择10个话语。
更新:对Voxceleb1选定对的评估显示7.4%EER。
该模型可以在此GDRIVE链接上下载。
跑步
指定train_dir后, config.yaml的test_dir ,运行:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name]这将在基本目录中创建chkpt/name和logs/name ( -b选项, .默认为。)
查看TensorBoardX
tensorboard --logdir ./logs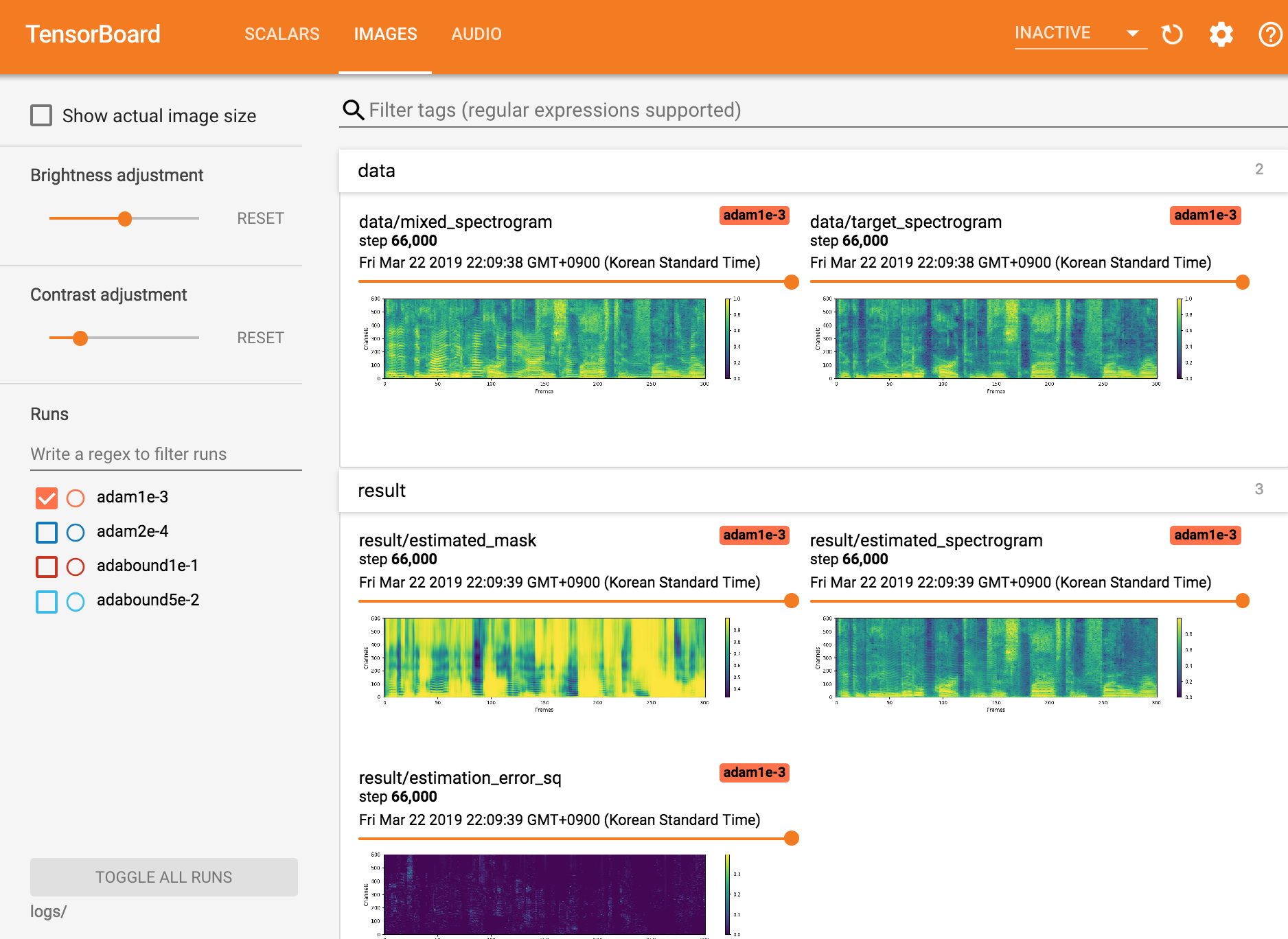
从检查点恢复
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Mindslab([email protected],[email protected])的Seungwon Park
Apache许可证2.0
该存储库包含从以下内容中改编/复制的代码:


