voicefilter
1.0.0
Hallo allerseits! Es ist Seung-Won von Minds Lab, Inc. Es ist lange her, seit ich diese Open-Source veröffentlicht habe, und ich hatte nicht erwartet, dass dieses Repository lange Zeit so viel Aufmerksamkeit erregt. Ich möchte allen dafür danken, dass sie solche Aufmerksamkeit erregt haben, und auch Herr Quan Wang (der Erstautor des VoiceFilter Paper) für die Überweisung dieses Projekts in seinem Papier.
Tatsächlich wurde dieses Projekt von mir durchgeführt, als es nur 3 Monate dauerte, als ich mit dem Studium der Deep Learning & Speech Trennung ohne Vorgesetzte im relevanten Bereich begann. Damals wusste ich nicht, was eine Power-Law-Komprimierung ist und die richtige Art, die Modelle zu validieren/zu testen. Jetzt, da ich seitdem mehr Zeit für Deep Learning & Speech verbracht habe (ich habe auch ein Papier, das bei Interspeech 2020 veröffentlicht wurde, geschrieben habe, kann ich einige offensichtliche Fehler beobachten, die ich gemacht habe. Diese Probleme wurden freundlicherweise von Github -Benutzern aufgeworfen. Bitte beachten Sie die Probleme und ziehen Sie Anfragen dafür an. Davon abgesehen kann dieses Repository ziemlich unzuverlässig sein, und ich möchte alle daran erinnern, diesen Code auf eigenes Risiko zu verwenden (wie in Lizenz angegeben).
Leider kann ich mir keine zusätzliche Zeit bei der Überarbeitung dieses Projekts oder der Überprüfung der Probleme / Zuganfragen leisten. Stattdessen möchte ich neuere, zuverlässigere Ressourcen einige Hinweise anbieten:
Vielen Dank fürs Lesen und ich wünsche allen eine gute Gesundheit während der globalen pandemischen Situation.
Mit freundlichen Grüßen, Seung-Won Park
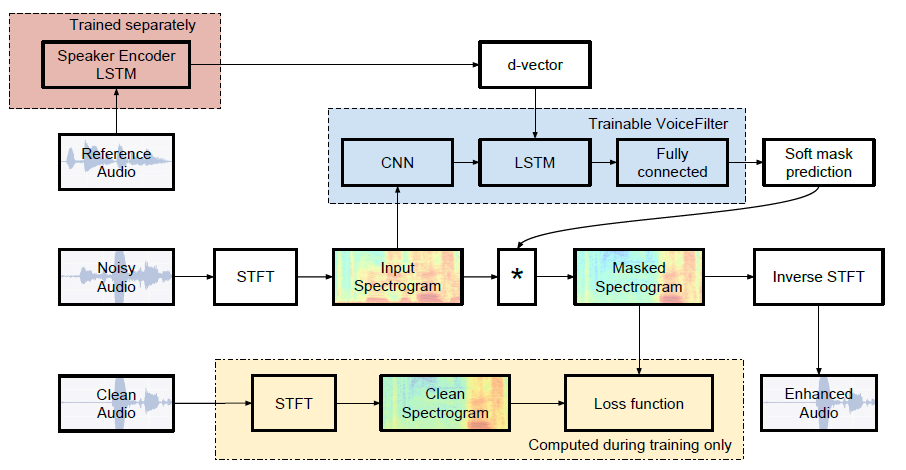
Inoffizielle Pytorch-Implementierung von Google AIs: VoiceFilter: gezielte Sprachtrennung durch Sprecher-konditionierte Spektrogrammmaskierung.
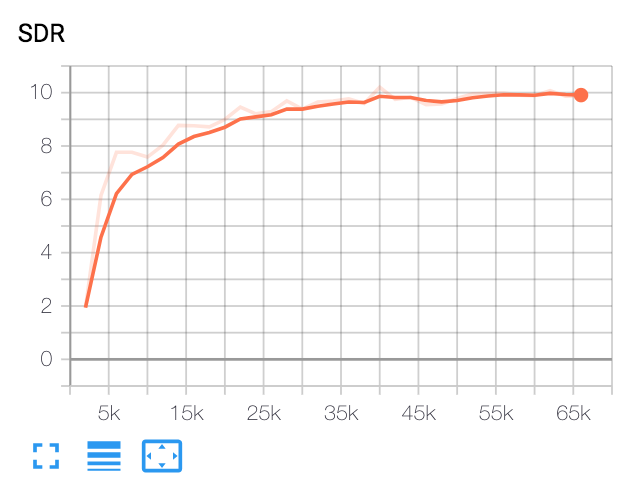
| Median SDR | Papier | Unsere |
|---|---|---|
| vor VoiceFilter | 2.5 | 1.9 |
| Nach VoiceFilter | 12.6 | 10.2 |
Python und Pakete
Dieser Code wurde auf Python 3.6 mit Pytorch 1.0.1 getestet. Andere Pakete können installiert werden von:
pip install -r requirements.txtVerschiedenes
FFMPEG-Normalize wird zum erneuten Abtast- und Normalisieren von WAV-Dateien verwendet. Siehe Readme.md von FFMPEG-Normalize zur Installation.
Laden Sie Librispeech -Datensatz herunter
Um VoiceFilter -Papier zu replizieren, erhalten Sie Librispeech -Datensatz unter http://www.openslr.org/12/. train-clear-100.tar.gz (6,3g) enthält die Sprache von 252 Lautsprechern und train-clear-360.tar.gz (23g) enthält 922 Lautsprecher. Sie können auch verwenden, aber je mehr Sprecher Sie im Datensatz haben, desto besserer Voicefilter werden es sein.
WAV -Dateien wiederproben und normalisieren
Erstens, unzipe tar.gz -Datei zum gewünschten Ordner:
tar -xvzf train-clear-360.tar.gz Kopieren Sie als Nächstes utils/normalize-resample.sh von Resample. Dann:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long Bearbeiten config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlPreprocess -WAV -Dateien
Um die Trainingsgeschwindigkeit zu steigern, führen Sie vor dem Training STFT für jede Datei durch: Führen Sie vor dem Training durch:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]Dadurch werden 100.000 (Zug) + 1000 (Test) Daten erstellt. (Ca. 160 g)
Holen Sie sich ein vorgespanntes Modell für das Lautsprechererkennungssystem
VoiceFilter verwendet das Lautsprechererkennungssystem (D-Vektor-Einbettung). Hier bieten wir ein vorgezogenes Modell für die Erlangung von D-Vektor-Einbettungen an.
Dieses Modell wurde mit Voxceleb2 -Datensatz trainiert, wo Äußerungen zufällig zu Zeitlänge [70, 90] Frames passen. Die Tests werden mit Fenster 80 / Hop 40 durchgeführt und haben die gleiche Fehlerrate etwa 1%gezeigt. Die für den Test verwendeten Daten wurden aus den ersten 8 Lautsprechern des VoxcELEB1 -Testdatensatzes ausgewählt, wobei 10 Äußerungen pro Lautsprecher zufällig ausgewählt werden.
UPDATE : Die Bewertung des Voxceleb1 -ausgewählten Paares zeigte 7,4% EER.
Das Modell kann unter diesem DDRIVE -Link heruntergeladen werden.
Laufen
Nach Angabe von train_dir , test_dir at config.yaml , rennen Sie:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] Dadurch wird chkpt/name und logs/name im Basisverzeichnis erstellt ( -b -Option . in Standard).
Tensorboardx anzeigen
tensorboard --logdir ./logs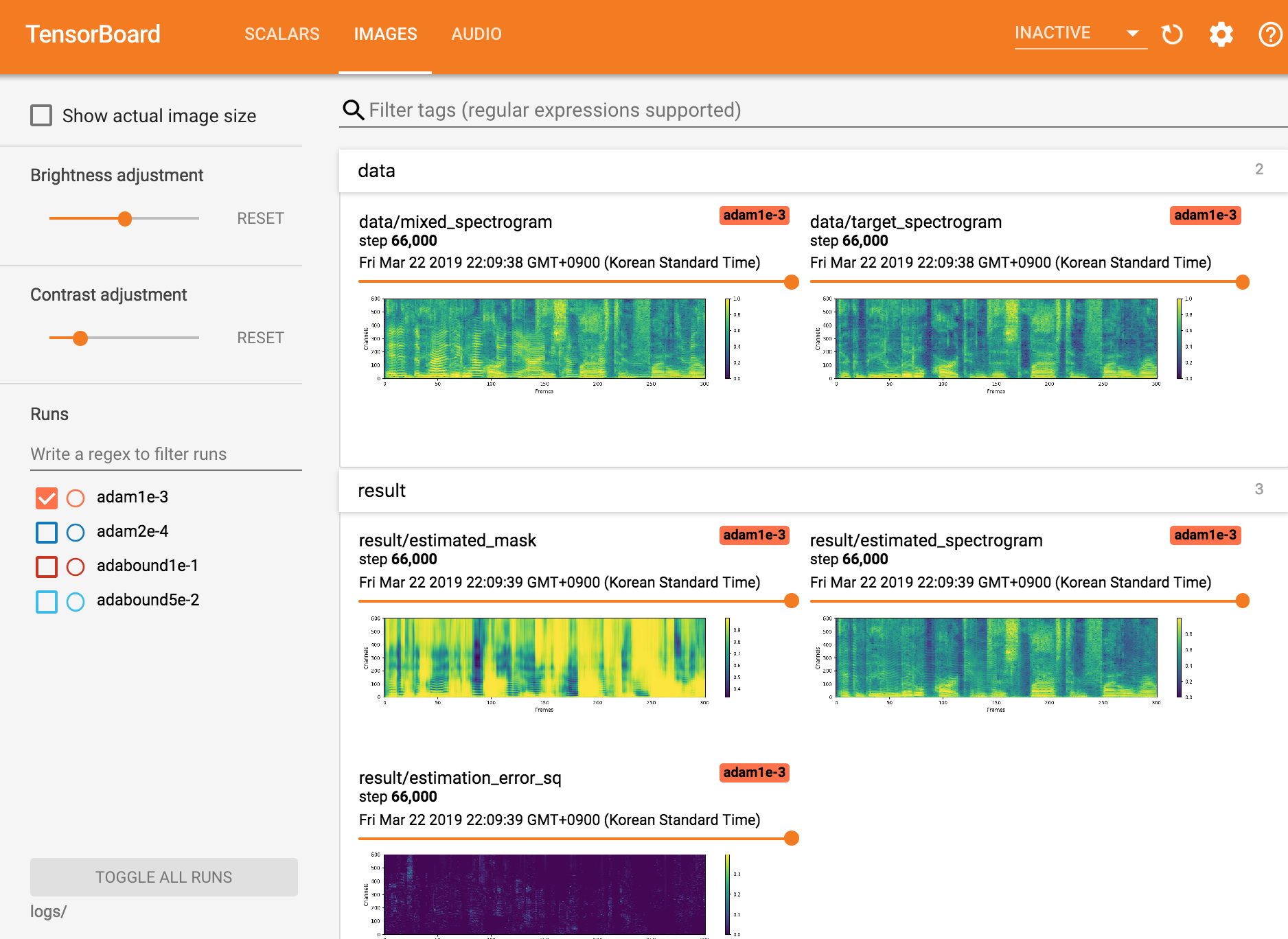
Wiederaufnahme von Checkpoint
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Seungwon Park bei Mindslab ([email protected], [email protected])
Apache -Lizenz 2.0
Dieses Repository enthält Codes, die aus den folgenden Angaben angepasst/kopiert wurden:


