voicefilter
1.0.0
Hai semuanya! Seung-won dari Minds Lab, Inc. Sudah lama sekali saya telah merilis open-source ini, dan saya tidak berharap repositori ini mengambil begitu banyak perhatian untuk waktu yang lama. Saya ingin mengucapkan terima kasih kepada semua orang karena telah memberikan perhatian seperti itu, dan juga Tn. Quan Wang (penulis pertama dari The Voicefilter Paper) karena merujuk proyek ini dalam makalahnya.
Sebenarnya, proyek ini dilakukan oleh saya ketika baru 3 bulan setelah saya mulai mempelajari pembelajaran yang mendalam & pemisahan bicara tanpa pengawas di bidang yang relevan. Saat itu, saya tidak tahu apa itu kompresi hukum-hukum, dan cara yang benar untuk memvalidasi/menguji model. Sekarang saya telah menghabiskan lebih banyak waktu untuk pembelajaran & pidato yang mendalam sejak saat itu (saya juga menulis sebuah makalah yang diterbitkan di Interspeech 2020?), Saya dapat mengamati beberapa kesalahan jelas yang telah saya buat. Masalah -masalah itu diangkat dengan baik oleh pengguna GitHub; Silakan merujuk ke masalah dan tarik permintaan untuk itu. Yang sedang berkata, repositori ini bisa sangat tidak dapat diandalkan, dan saya ingin mengingatkan semua orang untuk menggunakan kode ini dengan risiko sendiri (sebagaimana ditentukan dalam lisensi).
Sayangnya, saya tidak dapat membeli waktu tambahan untuk merevisi proyek ini atau meninjau permintaan masalah / tarik. Sebaliknya, saya ingin menawarkan beberapa petunjuk ke sumber daya yang lebih baru dan lebih dapat diandalkan:
Terima kasih telah membaca, dan saya berharap semua orang kesehatan yang baik selama situasi pandemi global.
Salam Hormat, Seung-Won Park
Implementasi Pytorch tidak resmi dari Google AI: Voicefilter: Pemisahan suara yang ditargetkan oleh masking spektrogram yang dikondisikan oleh pembicara.
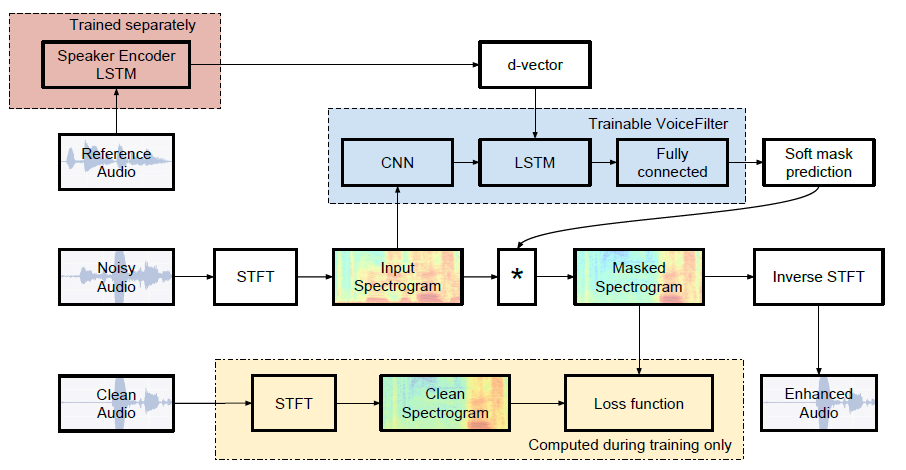
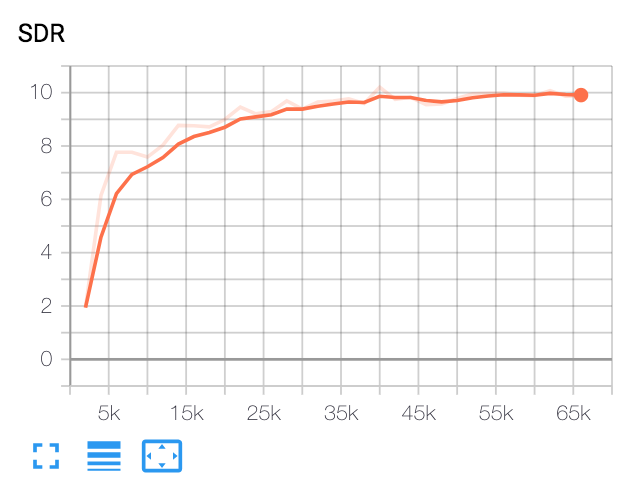
| Median sdr | Kertas | Milik kita |
|---|---|---|
| sebelum voicefilter | 2.5 | 1.9 |
| setelah voicefilter | 12.6 | 10.2 |
Python dan paket
Kode ini diuji pada Python 3.6 dengan Pytorch 1.0.1. Paket lain dapat diinstal oleh:
pip install -r requirements.txtAneka ragam
FFMPEG-Normalize digunakan untuk resampling dan menormalkan file WAV. Lihat ReadMe.MD dari FFMPEG-Normalisasi untuk Instalasi.
Unduh Dataset Librispeech
Untuk mereplikasi kertas voicefilter, dapatkan dataset Librispeech di http://www.openslr.org/12/. train-clear-100.tar.gz (6.3G) berisi pidato 252 pembicara, dan train-clear-360.tar.gz (23G) berisi 922 speaker. Anda dapat menggunakan keduanya, tetapi semakin banyak speaker yang Anda miliki dalam dataset, semakin banyak voicefilter yang lebih baik.
Resample & Normalisasi File WAV
Pertama, file unzip tar.gz ke folder yang diinginkan:
tar -xvzf train-clear-360.tar.gz Selanjutnya, salin utils/normalize-resample.sh ke root direktori folder data unzip. Kemudian:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long Edit config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlPreprocess WAV File
Untuk meningkatkan kecepatan pelatihan, lakukan STFT untuk setiap file sebelum pelatihan oleh:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]Ini akan membuat data 100.000 (kereta) + 1000 (uji). (Sekitar 160g)
Dapatkan model pretrained untuk sistem pengenalan speaker
Voicefilter menggunakan sistem pengenalan speaker (embeddings vektor D). Di sini, kami menyediakan model pretrained untuk mendapatkan embeddings vektor D.
Model ini dilatih dengan dataset Voxceleb2, di mana ucapan secara acak sesuai dengan panjang waktu [70, 90]. Tes dilakukan dengan Window 80 / Hop 40 dan telah menunjukkan tingkat kesalahan yang sama sekitar 1%. Data yang digunakan untuk pengujian dipilih dari 8 speaker pertama dari dataset uji Voxceleb1, di mana 10 ucapan per setiap speaker dipilih secara acak.
Pembaruan : Evaluasi pada pasangan yang dipilih Voxceleb1 menunjukkan 7,4% EER.
Model dapat diunduh di tautan GDRIVE ini.
Berlari
Setelah menentukan train_dir , test_dir di config.yaml , jalankan:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] Ini akan membuat chkpt/name dan logs/name di direktori dasar ( -b opsi . Di default)
Lihat Tensorboardx
tensorboard --logdir ./logs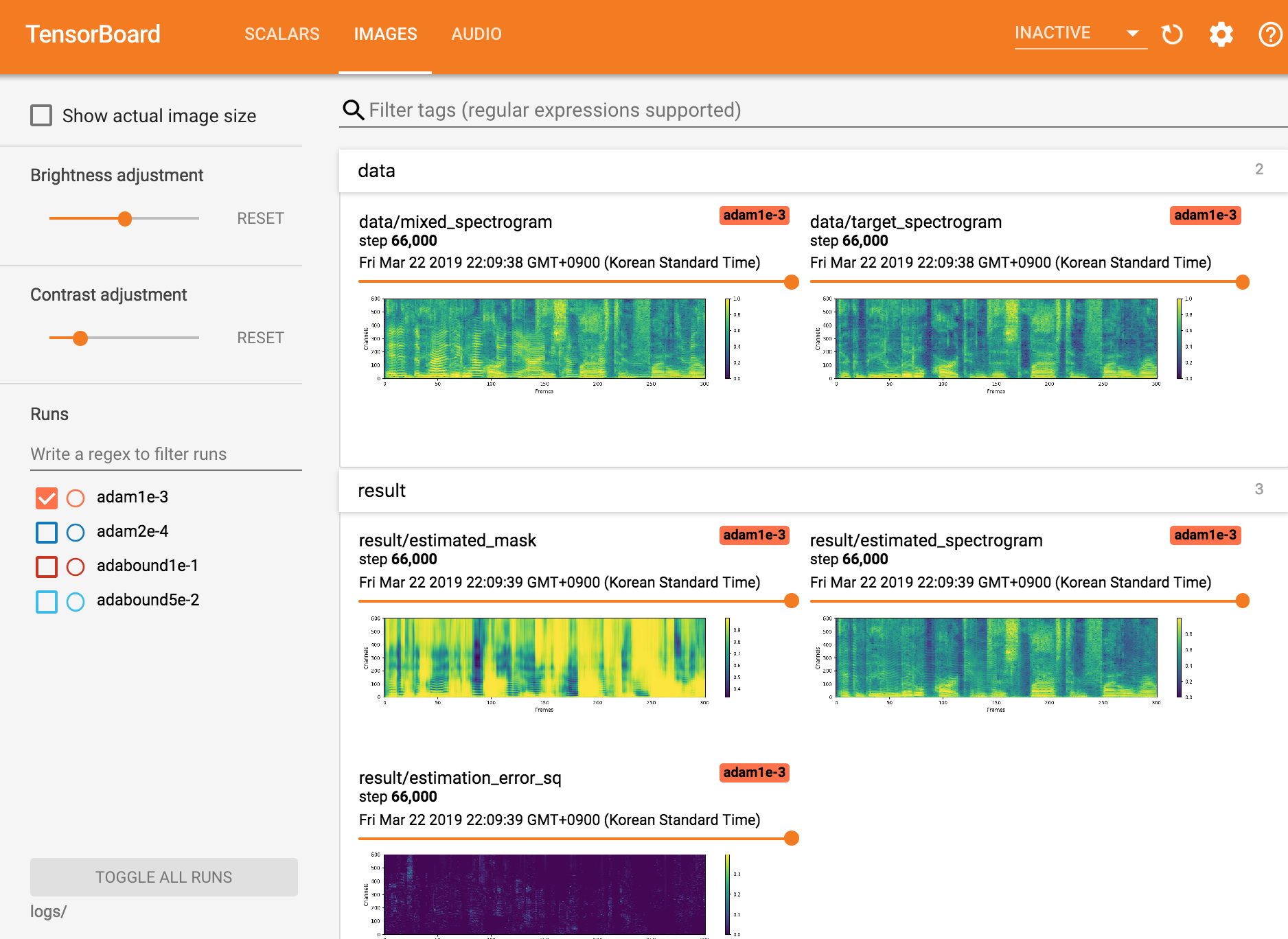
Melanjutkan dari pos pemeriksaan
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Taman Seungwon di Mindslab ([email protected], [email protected])
Lisensi Apache 2.0
Repositori ini berisi kode yang diadaptasi/disalin dari pengikut:


