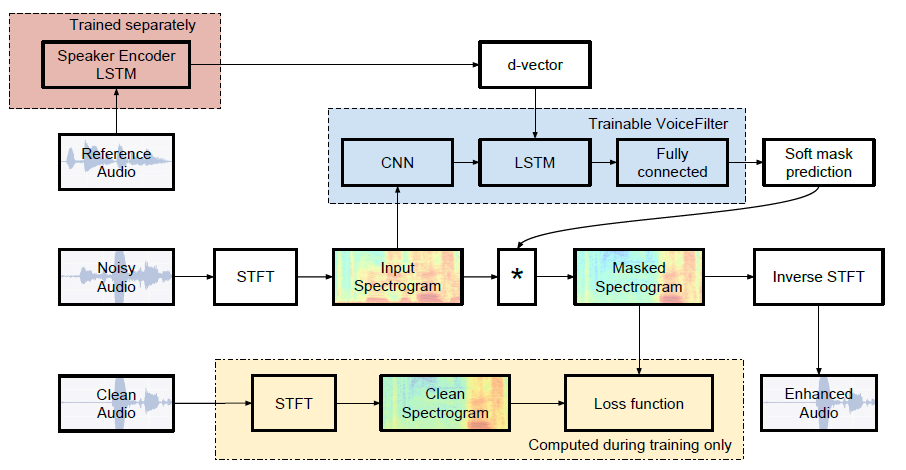
voicefilter
1.0.0
¡Hola a todos! Es Seung-Won de Minds Lab, Inc. Ha pasado mucho tiempo desde que lanzé este código abierto, y no esperaba que este repositorio llamara una gran cantidad de atención durante mucho tiempo. Me gustaría agradecer a todos por prestar tanta atención, y también el Sr. Quan Wang (el primer autor del documento de VoiceFilter) por referir este proyecto en su artículo.
En realidad, este proyecto fue realizado por mí cuando solo fueron 3 meses después de que comencé a estudiar el aprendizaje profundo y la separación del habla sin un supervisor en el campo relevante. En aquel entonces, no sabía qué es una compresión de la ley de potencia y la forma correcta de validar/probar los modelos. Ahora que he pasado más tiempo en el aprendizaje profundo y el discurso desde entonces (también escribí un artículo publicado en Interspeech 2020?), Puedo observar algunos errores obvios que he cometido. Esos problemas fueron planteados amablemente por los usuarios de GitHub; Consulte los problemas y retire las solicitudes para eso. Dicho esto, este repositorio puede ser bastante poco confiable, y me gustaría recordar a todos que usen este código bajo su propio riesgo (como se especifica en la licencia).
Desafortunadamente, no puedo permitirme tiempo extra para revisar este proyecto o revisar las solicitudes de problemas / extracción. En cambio, me gustaría ofrecer algunos consejos a recursos más nuevos y confiables:
Gracias por leer, y les deseo a todos una buena salud durante la situación de la pandemia global.
Saludos cordiales, Seung-Won Park
Implementación no oficial de Pytorch de Google AI: VoiceFilter: separación de voz dirigida por enmascaramiento de espectrograma condicionado por los altavoces.
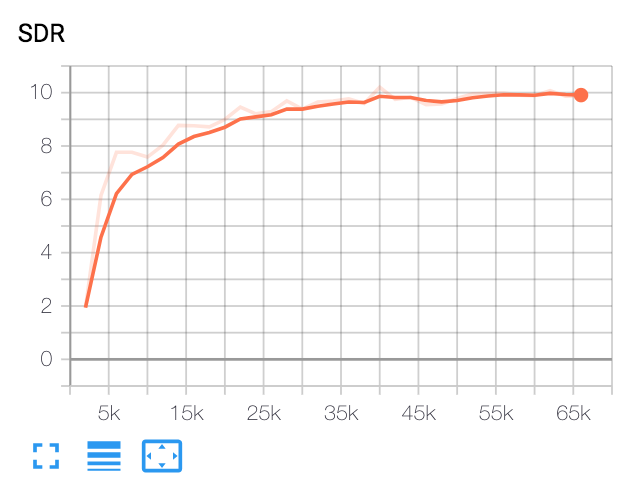
| SDR mediana | Papel | Nuestro |
|---|---|---|
| Antes de VoiceFilter | 2.5 | 1.9 |
| Después de VoiceFilter | 12.6 | 10.2 |
Python y paquetes
Este código se probó en Python 3.6 con Pytorch 1.0.1. Se pueden instalar otros paquetes por:
pip install -r requirements.txtMisceláneas
FFMPEG-normalizar se usa para volver a muestrear y normalizar los archivos WAV. Consulte ReadMe.MD de FFMPEG-normalizar para la instalación.
Descargar el conjunto de datos de Librispeech
Para replicar el papel de VoiceFilter, obtenga un conjunto de datos Librispeech en http://www.openslr.org/12/. train-clear-100.tar.gz (6.3g) contiene un discurso de 252 hablantes, y train-clear-360.tar.gz (23g) contiene 922 altavoces. Tampoco puede usar, pero cuantos más altavoces tenga en el conjunto de datos, más mejor VoiceFilter.
Volver a muestrear los archivos WAV
Primero, descifrar el archivo tar.gz a la carpeta deseada:
tar -xvzf train-clear-360.tar.gz A continuación, copie utils/normalize-resample.sh al directorio raíz de la carpeta de datos descomprimidas. Entonces:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long Editar config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlArchivos wav preprocesos
Para aumentar la velocidad de entrenamiento, realice STFT para cada archivos antes de capacitar por:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]Esto creará 100,000 datos (trenes) + 1000 (prueba). (Alrededor de 160 g)
Obtenga el modelo previamente para el sistema de reconocimiento de altavoces
VoiceFilter utiliza el Sistema de reconocimiento de altavoces (incrustaciones del vector D). Aquí, proporcionamos un modelo previo a la detención para obtener incrustaciones del vector D.
Este modelo fue entrenado con un conjunto de datos VoxCeleb2, donde las expresiones se ajustan aleatoriamente a los marcos de longitud de tiempo [70, 90]. Las pruebas se realizan con la ventana 80 / HOP 40 y han mostrado una tasa de error igual de aproximadamente el 1%. Los datos utilizados para la prueba se seleccionaron de los primeros 8 altavoces del conjunto de datos de prueba de VoxCeleb1, donde se seleccionan al azar 10 expresiones por cada altavoces.
ACTUALIZACIÓN : La evaluación en el par seleccionado VoxCeleb1 mostró 7.4% EER.
El modelo se puede descargar en este enlace RDRIVE.
Correr
Después de especificar train_dir , test_dir en config.yaml , ejecutar:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] Esto creará chkpt/name y logs/name en el directorio base ( -b opción . En predeterminado)
Ver tensorboardx
tensorboard --logdir ./logs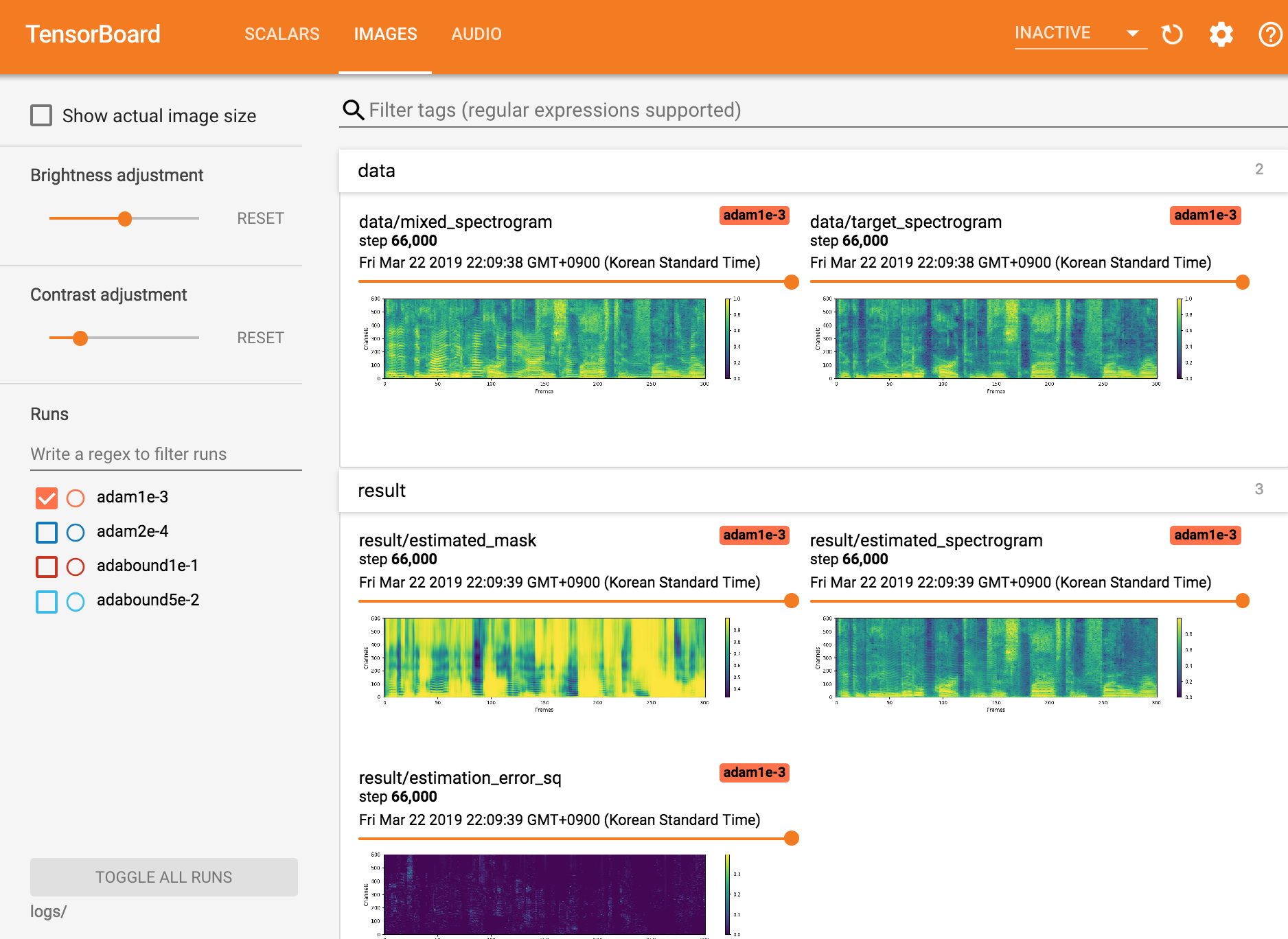
Reanudando desde el punto de control
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Parque Seungwon en Mindslab ([email protected], [email protected])
Licencia de Apache 2.0
Este repositorio contiene códigos adaptados/copiados de los siguientes:


