voicefilter
1.0.0
สวัสดีทุกคน! มันคือ Seung-won จาก Minds Lab, Inc. มันเป็นเวลานานแล้วที่ฉันได้เปิดตัวโอเพนซอร์ซนี้และฉันไม่ได้คาดหวังว่าที่เก็บนี้จะดึงดูดความสนใจเป็นเวลานาน ฉันขอขอบคุณทุกคนที่ให้ความสนใจเช่นนี้และ Mr. Quan Wang (ผู้เขียนคนแรกของ The Voicefilter Paper) สำหรับการอ้างอิงโครงการนี้ในบทความของเขา
ที่จริงแล้วโครงการนี้ทำโดยฉันเมื่อมันเป็นเพียง 3 เดือนหลังจากที่ฉันเริ่มเรียนการเรียนรู้อย่างลึกซึ้งและการแยกการพูดโดยไม่มีหัวหน้างานในสาขาที่เกี่ยวข้อง ย้อนกลับไปตอนนั้นฉันไม่รู้ว่าอะไรคือการบีบอัดกฎหมายและวิธีที่ถูกต้องในการตรวจสอบ/ทดสอบโมเดล ตอนนี้ฉันใช้เวลามากขึ้นในการเรียนรู้และพูดอย่างลึกซึ้งตั้งแต่นั้นมา (ฉันยังเขียนบทความที่ตีพิมพ์ที่ Interspeech 2020?) ฉันสามารถสังเกตข้อผิดพลาดที่ชัดเจนที่ฉันได้ทำ ปัญหาเหล่านั้นได้รับการยกขึ้นโดยผู้ใช้ GitHub; โปรดดูปัญหาและดึงคำขอสำหรับเรื่องนั้น ที่ถูกกล่าวว่าที่เก็บนี้ไม่น่าเชื่อถือและฉันอยากจะเตือนให้ทุกคนใช้รหัสนี้ด้วยความเสี่ยงของตนเอง (ตามที่ระบุไว้ในใบอนุญาต)
น่าเสียดายที่ฉันไม่สามารถจ่ายเวลาพิเศษในการแก้ไขโครงการนี้หรือตรวจสอบปัญหา / คำขอดึง แต่ฉันต้องการเสนอพอยน์เตอร์ให้กับทรัพยากรที่ใหม่กว่าและเชื่อถือได้มากขึ้น:
ขอบคุณสำหรับการอ่านและฉันขอให้ทุกคนมีสุขภาพที่ดีในระหว่างสถานการณ์การระบาดของโลก
ขอแสดงความนับถือ Seung-won Park
การใช้งาน Pytorch อย่างไม่เป็นทางการของ Google AI's: VoiceFilter: การแยกเสียงที่กำหนดเป้าหมายโดยการปิดบังสเปกโตรแกรมแบบลำโพง
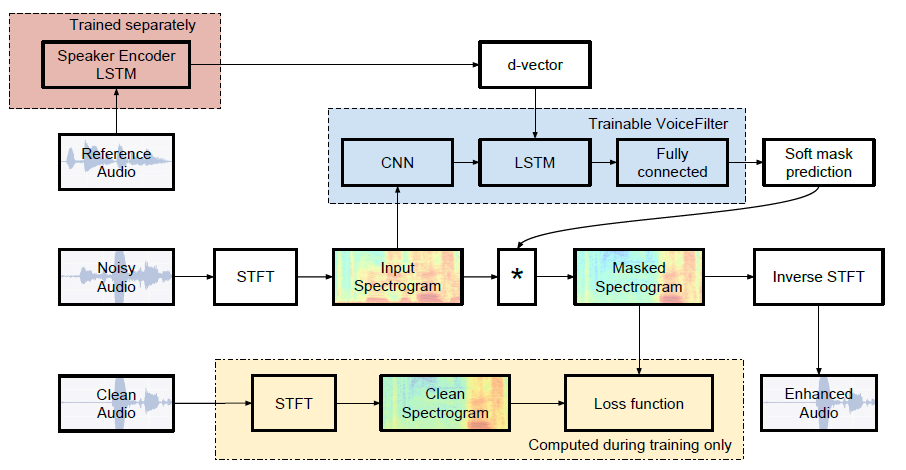
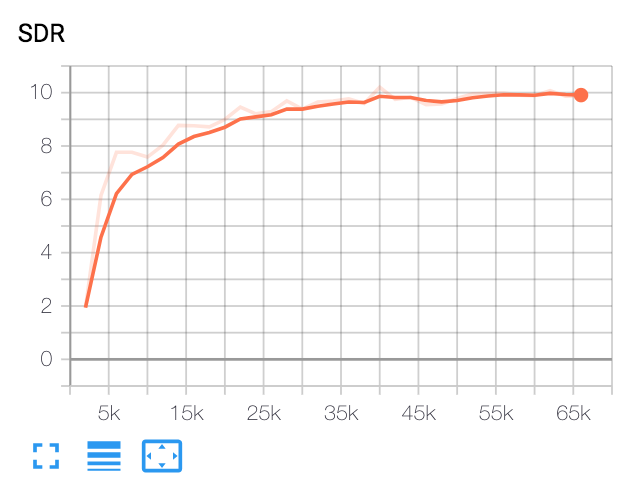
| SDR ค่ามัธยฐาน | กระดาษ | ของเรา |
|---|---|---|
| ก่อนเสียงกรอง | 2.5 | 1.9 |
| หลังจากเสียงกรอง | 12.6 | 10.2 |
งูเหลือมและแพ็คเกจ
รหัสนี้ถูกทดสอบใน Python 3.6 ด้วย Pytorch 1.0.1 แพ็คเกจอื่น ๆ สามารถติดตั้งได้โดย:
pip install -r requirements.txtเบ็ดเตล็ด
FFMPEG-Normalize ใช้สำหรับการสุ่มตัวอย่างใหม่และทำให้ไฟล์ WAV เป็นมาตรฐาน ดู readme.md ของ ffmpeg-normalize สำหรับการติดตั้ง
ดาวน์โหลดชุดข้อมูล librispeech
หากต้องการทำซ้ำกระดาษ VoiceFilter ให้รับชุดข้อมูล librispeech ที่ http://www.openslr.org/12/ train-clear-100.tar.gz (6.3g) มีคำพูดของลำโพง 252 และ train-clear-360.tar.gz (23G) มีลำโพง 922 คุณอาจใช้อย่างใดอย่างหนึ่ง แต่ยิ่งคุณมีลำโพงมากขึ้นในชุดข้อมูลยิ่งเสียงที่ดีขึ้นก็จะยิ่งดีขึ้นเท่านั้น
Resample & Normalize WAV ไฟล์
ก่อนอื่นไฟล์ unzip tar.gz ไปยังโฟลเดอร์ที่ต้องการ:
tar -xvzf train-clear-360.tar.gz ถัดไปคัดลอก utils/normalize-resample.sh ไปยังรูทไดเรกทอรีของโฟลเดอร์ข้อมูลที่ยังไม่ซิป แล้ว:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long แก้ไข config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlไฟล์ WAV ประมวลผลล่วงหน้า
เพื่อเพิ่มความเร็วในการฝึกอบรมให้ดำเนินการ STFT สำหรับแต่ละไฟล์ก่อนการฝึกอบรมโดย:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]สิ่งนี้จะสร้างข้อมูล 100,000 (รถไฟ) + 1,000 (ทดสอบ) (ประมาณ 160 กรัม)
รับแบบจำลองก่อนหน้าสำหรับระบบการจดจำลำโพง
VoiceFilter ใช้ระบบการจดจำลำโพง (D-Vector Embeddings) ที่นี่เรามีแบบจำลองที่ได้รับการฝึกฝนสำหรับการได้รับ D-Vector Embeddings
โมเดลนี้ได้รับการฝึกฝนด้วยชุดข้อมูล Voxceleb2 ซึ่งคำพูดนั้นมีความยาวตามความยาว [70, 90] แบบสุ่ม การทดสอบจะทำด้วยหน้าต่าง 80 / Hop 40 และแสดงอัตราความผิดพลาดที่เท่ากันประมาณ 1% ข้อมูลที่ใช้สำหรับการทดสอบถูกเลือกจาก 8 ลำโพงแรกของชุดข้อมูลการทดสอบ Voxceleb1 โดยที่ 10 คำพูดต่อลำโพงแต่ละตัวถูกสุ่มเลือก
อัปเดต : การประเมินผลของคู่ที่เลือก Voxceleb1 แสดงให้เห็นว่า 7.4% EER
สามารถดาวน์โหลดโมเดลได้ที่ลิงค์ GDRIVE นี้
วิ่ง
หลังจากระบุ train_dir test_dir ที่ config.yaml , Run:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] สิ่งนี้จะสร้าง chkpt/name และ logs/name ที่ไดเรกทอรีพื้นฐาน (ตัวเลือก -b . ในค่าเริ่มต้น)
ดู tensorboardx
tensorboard --logdir ./logs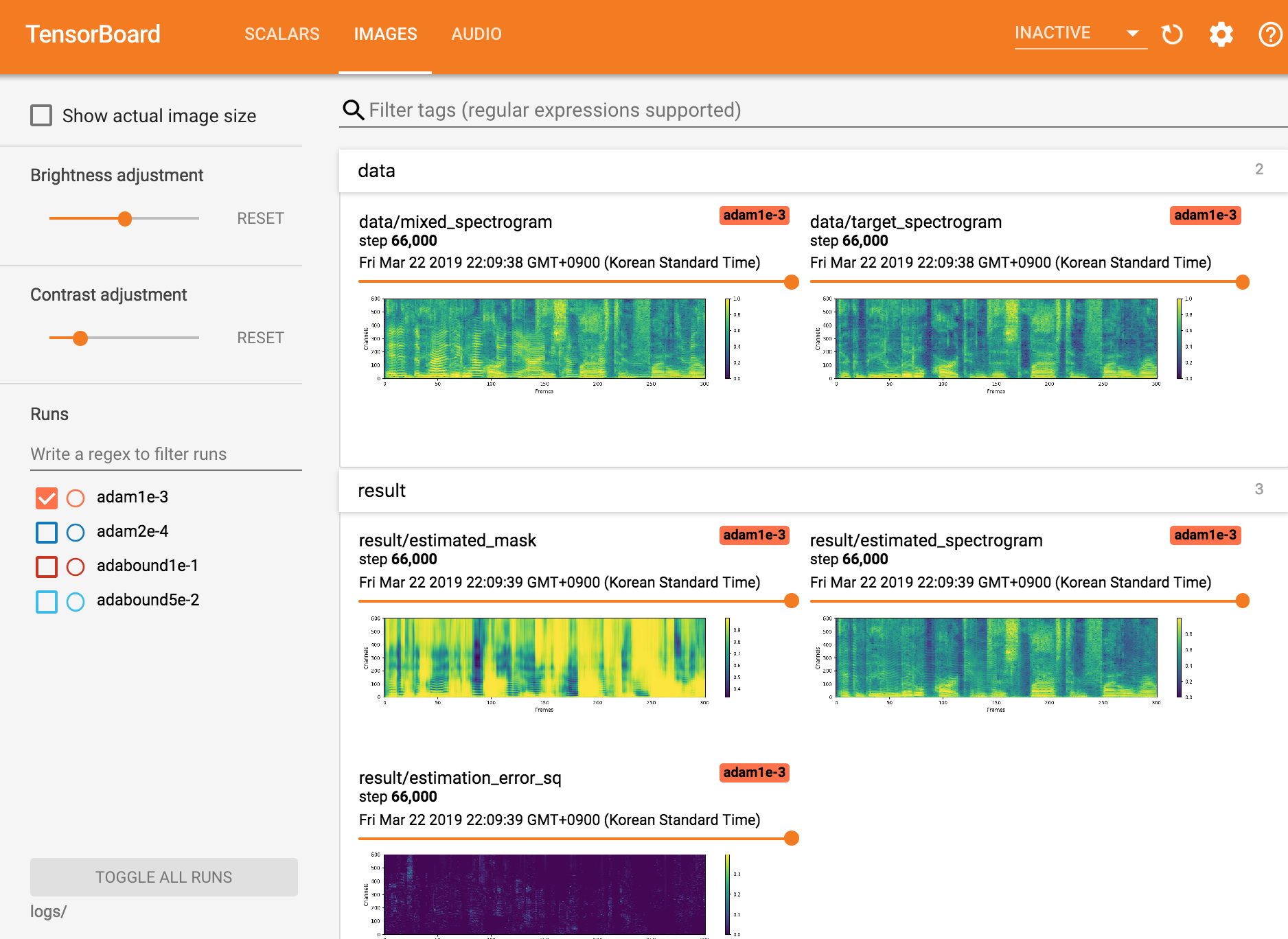
กลับมาจากจุดตรวจสอบ
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Seungwon Park ที่ Mindslab ([email protected], [email protected])
ใบอนุญาต Apache 2.0
ที่เก็บนี้มีรหัสที่ดัดแปลง/คัดลอกมาจากสิ่งต่อไปนี้:


