voicefilter
1.0.0
مرحباً جميعاً! لقد مرّ Seung-Won From Minds Lab ، Inc. لقد مضى وقت طويل منذ أن أصدرت هذا المصدر المفتوح ، ولم أكن أتوقع أن يحظى هذا المستودع بمثل هذا الاهتمام لفترة طويلة. أود أن أشكر الجميع على هذا الاهتمام ، وكذلك السيد كوان وانغ (المؤلف الأول لورقة FoundFilter) لإحالة هذا المشروع في ورقته.
في الواقع ، تم تنفيذ هذا المشروع من قبلي عندما كان بعد 3 أشهر فقط من بدء دراسة التعلم العميق والكلام دون مشرف في المجال ذي الصلة. في ذلك الوقت ، لم أكن أعرف ما هو ضغط قانون القوة ، والطريقة الصحيحة للتحقق من/اختبار النماذج. الآن بعد أن أمضيت وقتًا أطول في التعلم العميق والكلام منذ ذلك الحين (كتبت أيضًا ورقة تم نشرها في Interspeech 2020؟) ، يمكنني ملاحظة بعض الأخطاء الواضحة التي ارتكبتها. وقد أثيرت هذه القضايا بلطف من قبل مستخدمي جيثب. يرجى الرجوع إلى المشكلات وسحب الطلبات لذلك. ومع ذلك ، يمكن أن يكون هذا المستودع غير موثوق به تمامًا ، وأود أن أذكر الجميع باستخدام هذا الرمز على مسؤوليتهم الخاصة (كما هو محدد في الترخيص).
لسوء الحظ ، لا يمكنني تحمل وقت إضافي في مراجعة هذا المشروع أو مراجعة المشكلات / طلبات السحب. بدلاً من ذلك ، أود أن أقدم بعض المؤشرات لموارد أحدث وأكثر موثوقية:
شكرا للقراءة ، وأتمنى للجميع صحة جيدة خلال الوضع الوبائي العالمي.
مع أطيب التحيات ، Seung-Won Park
تنفيذ Pytorch غير رسمي لـ Google AI's: Voicefilter: الفصل الصوتي المستهدف بواسطة إخفاء الطيف المكيف.
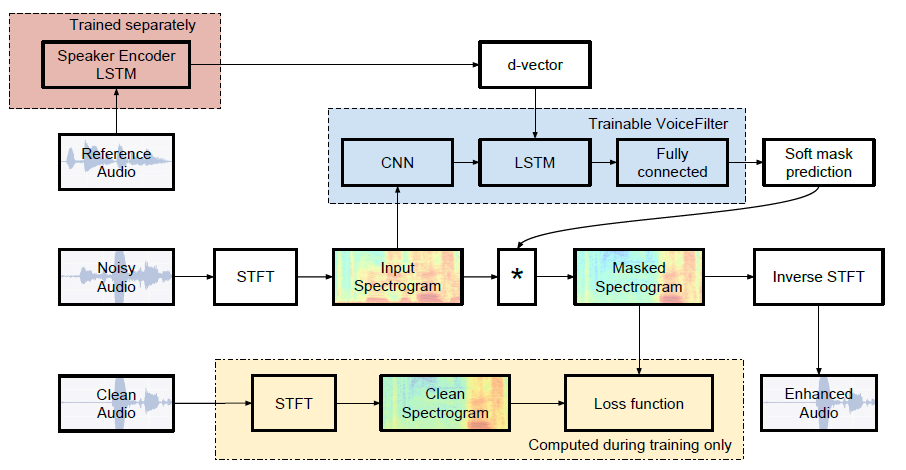
| وسيط SDR | ورق | لنا |
|---|---|---|
| قبل صوت الصوت | 2.5 | 1.9 |
| بعد التصفية الصوتية | 12.6 | 10.2 |
بيثون والحزم
تم اختبار هذا الرمز على Python 3.6 مع Pytorch 1.0.1. يمكن تثبيت حزم أخرى بواسطة:
pip install -r requirements.txtمتنوع
يتم استخدام FFMPEG-Normalize لإعادة أخذ عينات وتطبيع ملفات WAV. انظر readme.md من FFMPEG-NORMINCY للتثبيت.
قم بتنزيل مجموعة بيانات Librispeech
لتكرار ورقة الصوتية ، احصل على مجموعة بيانات Librispeech على http://www.openslr.org/12/. يحتوي train-clear-100.tar.gz (6.3g) على خطاب من 252 مكبرات صوت ، ويحتوي train-clear-360.tar.gz (23g) على 922 مكبرات صوت. يمكنك استخدام أي منهما ، ولكن كلما زاد عدد مكبرات الصوت التي لديك في مجموعة البيانات ، كلما كان تصفية الصوت أفضل.
إعادة تشكيل ملفات WAV وتطبيعها
أولاً ، ملف UNXIP tar.gz إلى المجلد المطلوب:
tar -xvzf train-clear-360.tar.gz بعد ذلك ، نسخ utils/normalize-resample.sh إلى دليل جذر مجلد البيانات غير المدمج. ثم:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long تحرير config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlملفات WAV قبل المعالجة
من أجل زيادة سرعة التدريب ، قم بإجراء STFT لكل ملفات قبل التدريب بواسطة:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]سيؤدي ذلك إلى إنشاء بيانات 100000 (قطار) + 1000 (اختبار). (حوالي 160 جم)
احصل على نموذج ما قبل المسبق لنظام التعرف على المتحدثين
يستخدم VoiceFilter نظام التعرف على السماعات (D-Vector Embeddings). هنا ، نحن نقدم نموذجًا مسبقًا للحصول على تضمينات D-Vector.
تم تدريب هذا النموذج مع مجموعة بيانات VoxCeCeCeLEB2 ، حيث تتناسب الكلام بشكل عشوائي مع طول الوقت [70 ، 90] إطارات. تتم الاختبارات مع النافذة 80 / HOP 40 وأظهرت معدل خطأ متساوٍ بنحو 1 ٪. تم اختيار البيانات المستخدمة للاختبار من أول 8 مكبرات صوت لمجموعة بيانات اختبار VoxceCeCeleb1 ، حيث يتم اختيار 10 كلمات لكل مكبرات صوت بشكل عشوائي.
تحديث : أظهر التقييم على زوج VoxceCeCeleb1 6.4 ٪ EER.
يمكن تنزيل النموذج على رابط GDrive هذا.
يجري
بعد تحديد train_dir ، test_dir في config.yaml ، تشغيل:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] سيؤدي ذلك إلى إنشاء chkpt/name and logs/name في Directory Base ( -b . في الافتراضي)
عرض Tensorboardx
tensorboard --logdir ./logs
استئناف من نقطة التفتيش
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Seungwon Park at Mindslab ([email protected] ، [email protected])
ترخيص Apache 2.0
يحتوي هذا المستودع على رموز تكييف/نسخ من ما يلي:


