voicefilter
1.0.0
Salut tout le monde! C'est Seung-won de Minds Lab, Inc. Cela fait longtemps que je n'ai pas sorti cette open source, et je ne m'attendais pas à ce que ce référentiel attire une si grande attention pendant longtemps. Je tiens à remercier tout le monde d'avoir accordé une telle attention, ainsi que M. Quan Wang (le premier auteur du journal VoiceFilter) d'avoir fait référence à ce projet dans son article.
En fait, ce projet a été réalisé par moi alors qu'il n'était que 3 mois après avoir commencé à étudier l'apprentissage en profondeur et la séparation de la parole sans superviseur dans le domaine pertinent. À l'époque, je ne savais pas quelle est une compression de la loi de puissance et la bonne façon de valider / tester les modèles. Maintenant que j'ai passé plus de temps sur l'apprentissage en profondeur et la parole depuis lors (j'ai également écrit un article publié sur IntereSpeech 2020?), Je peux observer des erreurs évidentes que j'ai commises. Ces problèmes ont été aimablement soulevés par les utilisateurs de GitHub; Veuillez vous référer aux problèmes et extraire les demandes de cela. Cela étant dit, ce référentiel peut être assez peu fiable, et je voudrais rappeler à tout le monde d'utiliser ce code à ses propres risques (comme spécifié dans la licence).
Malheureusement, je ne peux pas me permettre de plus de temps à réviser ce projet ou à examiner les questions / demandes de traction. Au lieu de cela, je voudrais offrir quelques conseils sur des ressources plus récentes et plus fiables:
Merci d'avoir lu, et je souhaite à tous une bonne santé pendant la situation pandémique mondiale.
Meilleures salutations, parc Seung-won
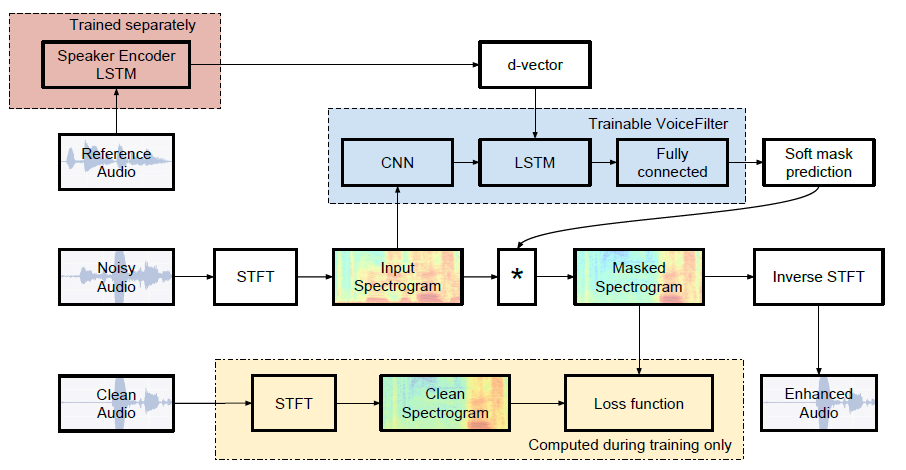
Implémentation non officielle Pytorch de Google AI: VoiceFilter: séparation de voix ciblée par masquage de spectrogramme conditionné par le haut-parleur.
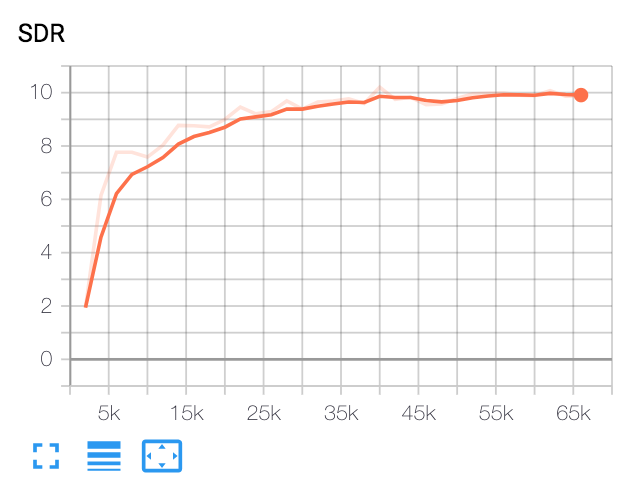
| SDR médian | Papier | La nôtre |
|---|---|---|
| Avant VoiceFilter | 2.5 | 1.9 |
| Après VoiceFilter | 12.6 | 10.2 |
Python et packages
Ce code a été testé sur Python 3.6 avec Pytorch 1.0.1. D'autres packages peuvent être installés par:
pip install -r requirements.txtDivers
FFMPEG-normalize est utilisé pour rééchantillonner et normaliser les fichiers WAV. Voir ReadMe.md de FFMPEG-normaliser pour l'installation.
Télécharger le jeu de données LibRispenech
Pour reproduire le papier VoiceFilter, obtenez un ensemble de données LibRisPesech sur http://www.opensenslr.org/12/. train-clear-100.tar.gz (6.3g) contient une parole de 252 conférenciers, et train-clear-360.tar.gz (23G) contient 922 haut-parleurs. Vous pouvez utiliser l'un ou l'autre, mais plus vous avez de haut-parleurs dans l'ensemble de données, plus la meilleure voix sera.
Rééchantillonner et normaliser les fichiers WAV
Tout d'abord, unzip tar.gz Fichier dans le dossier souhaité:
tar -xvzf train-clear-360.tar.gz Ensuite, copiez utils/normalize-resample.sh au répertoire racine du dossier de données unzripped. Alors:
vim normalize-resample.sh # set "N" as your CPU core number.
chmod a+x normalize-resample.sh
./normalize-resample.sh # this may take long Modifier config.yaml
cd config
cp default.yaml config.yaml
vim config.yamlFichiers WAV prétraités
Afin d'augmenter la vitesse d'entraînement, effectuez STFT pour chaque fichier avant de s'entraîner par:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]Cela créera 100 000 (train) + 1000 (test). (Environ 160g)
Obtenez un modèle pré-entraîné pour le système de reconnaissance des haut-parleurs
VoiceFilter utilise le système de reconnaissance des haut-parleurs (D-Vector Embeddings). Ici, nous fournissons un modèle pré-entraîné pour obtenir des incorporations de vecteur d.
Ce modèle a été formé avec un ensemble de données Voxceleb2, où les énoncés sont adaptés au hasard à des trames de longueur [70, 90]. Les tests sont effectués avec la fenêtre 80 / hop 40 et ont montré un taux d'erreur égal d'environ 1%. Les données utilisées pour le test ont été sélectionnées parmi les 8 premiers haut-parleurs de l'ensemble de données de test Voxceleb1, où 10 énoncés par haut-parleurs sont sélectionnés au hasard.
MISE À JOUR : L'évaluation de la paire sélectionnée Voxceleb1 a montré 7,4% EER.
Le modèle peut être téléchargé sur ce lien GDrive.
Courir
Après avoir spécifié train_dir , test_dir sur config.yaml , exécutez:
python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name] Cela créera chkpt/name et logs/name AU DIRECTORY DE BASE (OPTION -b . En défaut)
Afficher Tensorboardx
tensorboard --logdir ./logs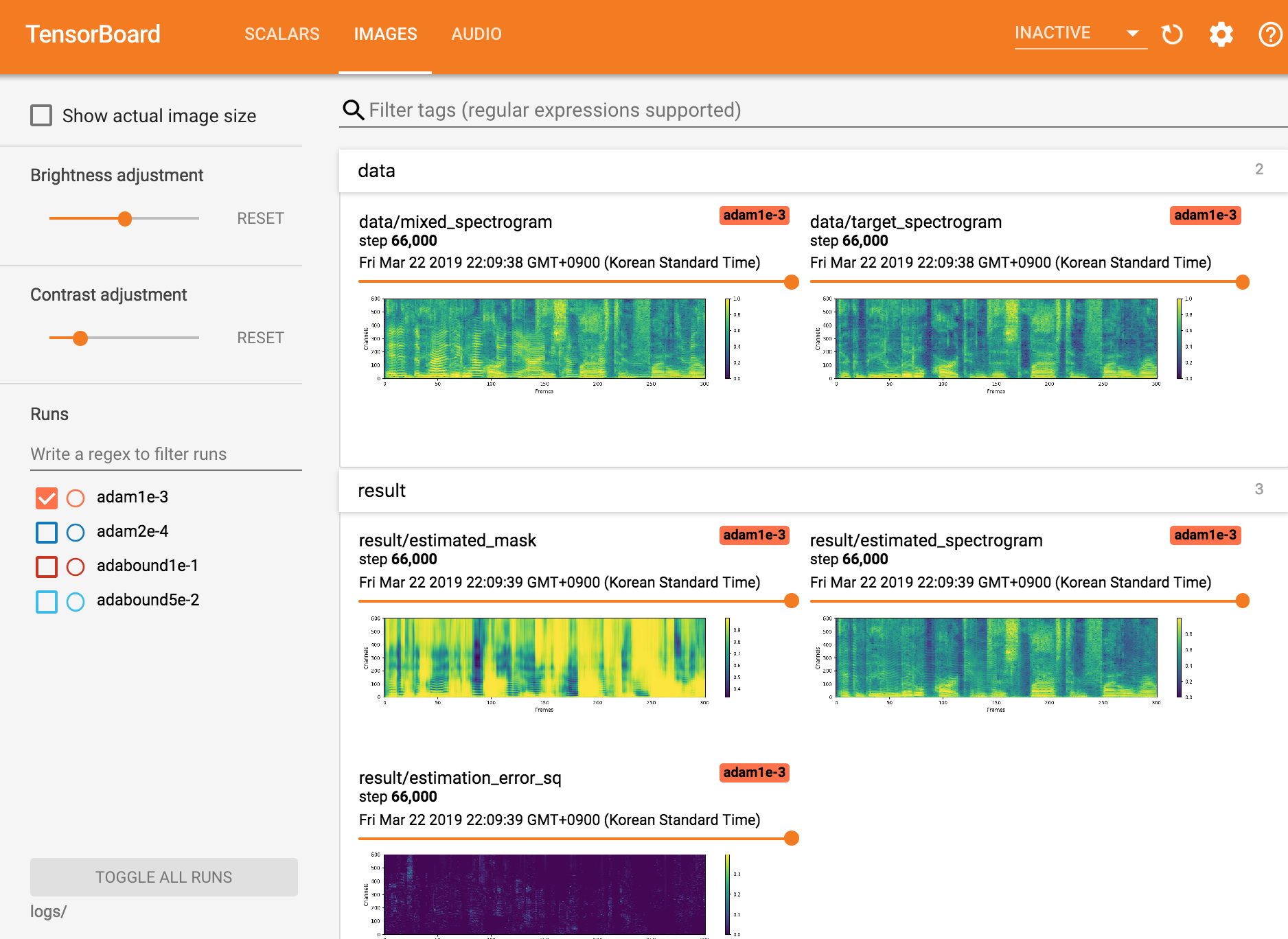
Reprise du point de contrôle
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m namepython inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Park Seungwon à Mindslab ([email protected], [email protected])
Licence Apache 2.0
Ce référentiel contient des codes adaptés / copiés à partir des suivants:


