image to latex
1.0.0
將乳膠數學方程式圖像映射到乳膠代碼的應用程序。
Deng等人嘗試了圖像到標記的問題。 (2016)。他們通過解析Arxiv的乳膠來源提取了約100K公式。他們使用PDFLATEX渲染公式,並將渲染的PDF文件轉換為PNG格式。其數據集的原始和預處理版本可在線獲得。在他們的模型中,CNN首先用於提取圖像特徵。然後使用RNN編碼功能的行。最後,帶有註意機制的RNN解碼器使用編碼的特徵。該模型總共有948萬個參數。最近,變壓器已超過了許多語言任務的RNN,因此我認為我可以在此問題中嘗試一下。
使用他們的數據集,我訓練了一種模型,該模型使用Resnet-18作為具有2D位置編碼的編碼器,而變壓器則用作交叉滲透損失的解碼器。 (類似於Singh等人(2021)中描述的,除了我僅使用重新連接到第3塊以降低計算成本,而且我排除了編號編碼,因為它不適用於此問題。)該模型大約有300萬參數。
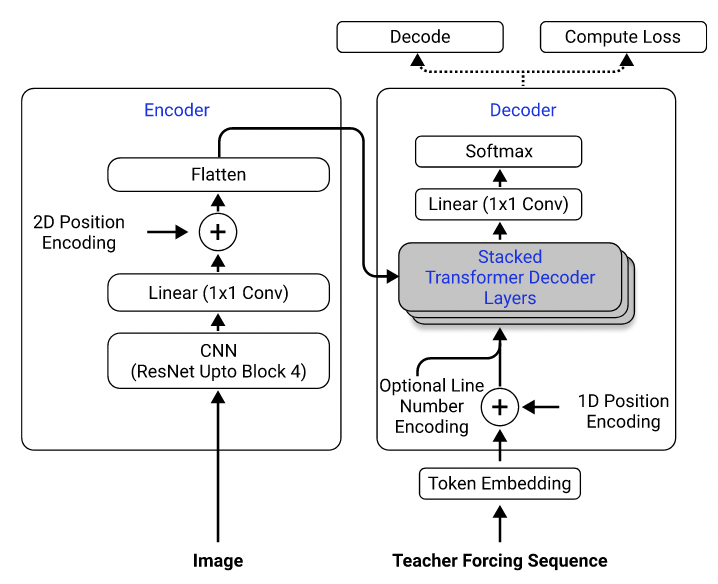
模型架構。取自Singh等。 (2021)。
最初,我使用預處理的數據集來訓練我的模型,因為預處理圖像被降低到其原始尺寸的一半以提高效率,並分組並填充相似的尺寸以方便批處理。但是,這種嚴格的預處理結果是一個巨大的限制。儘管該模型可以在測試集上實現合理的性能(以與培訓集相同的方式進行了預處理),但它並不能很好地推廣到數據集外的圖像,這很可能是因為圖像質量,填充和字體大小與數據集中的圖像差異很大。其他人使用相同的數據集嘗試了相同問題的其他人也觀察到了這種現象(例如,這個項目,此問題和此問題)。
為此,我使用了原始數據集,並在數據處理管道中包括圖像增強(例如隨機縮放,高斯噪聲)來增加樣品的多樣性。此外,與Deng等人不同。 (2016年),我沒有按大小分組圖像。相反,我對它們進行了統一的樣本,並將它們填充到批處理中最大圖像的大小,以便模型必須學習如何適應不同的填充大小。
我在數據集中遇到的其他問題:
left(和right)看起來與( and )相同),因此我對它們進行了歸一化。vspace{2px}和hspace{0.3mm} )。但是,即使對於人類,空間的長度也很難判斷。同樣,有許多表達相同間距的方法(例如1 cm = 10 mm)。最後,我不希望該模型在空白圖像上生成代碼,因此我將其刪除。 (我只刪除了vspace和hspace ,但是事實證明有很多水平間距的命令。我只在錯誤分析中意識到這一點。)請參見下文。 最佳運行在測試集中的字符錯誤率(CER)為0.17。這是測試數據集中的一個示例:
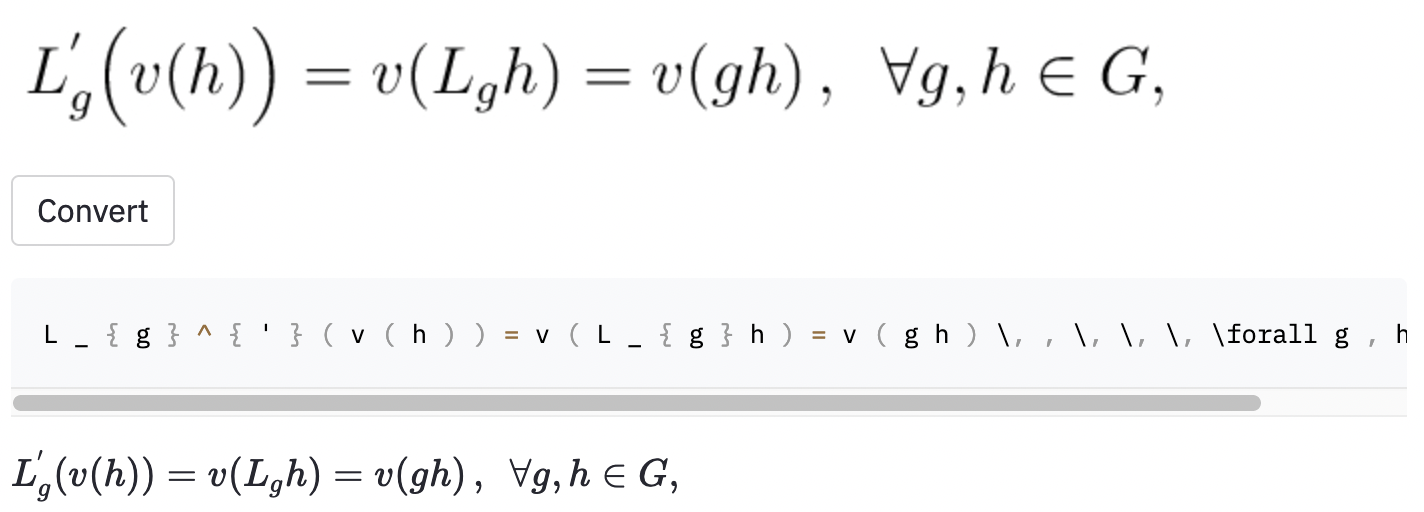
~創建了水平間距,而使用的模型,因此仍被視為誤差。我還在一些隨機的Wikipedia文章中拍攝了一些屏幕截圖,以查看該模型是否將圖像概括為數據集外的圖像:

cal渲染代碼。 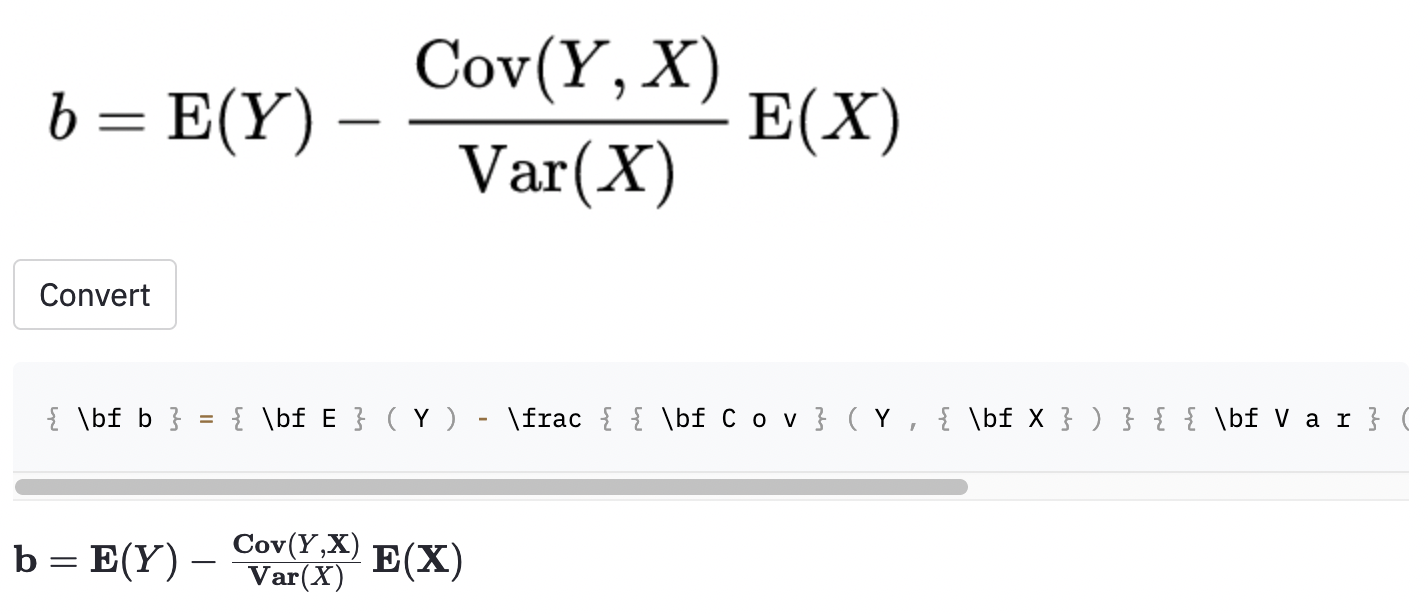
當圖像大於數據集中的圖像時,該模型似乎也遇到了一些麻煩。也許我應該增加數據增強過程中的重新恢復因素的範圍。
我認為我應該更好地定義項目的範圍:
( big( , Big( , bigg( , Bigg( )?這些問題應用於指導數據清潔過程。
我找到了一個名為MathPix Snip的精心建立的工具,該工具將手寫配方轉換為乳膠代碼。它的詞彙大小約為200。不包括數字和英文字母,它可以產生的乳膠命令的數量實際上略高於100。它僅包括兩個水平間距命令( quad和qquad ),並且不識別不同尺寸的括號。我應該做的事情始終局限於有限的詞彙,因為現實世界乳膠中有很多歧義。
這項工作的明顯可能改進包括(1)訓練該模型的更多時代(為了時間,我只訓練了15個時代的型號,但驗證損失仍在下降),(2)使用束搜索(I僅實現貪婪搜索),(3)使用較大的模型(例如,使用Resnet-34而不是Resnet-34而不是Resnet-34)和一些超級PAREN,並進行了一些超級標準。我沒有這樣做,因為我的計算資源有限(我正在使用Google Colab)。但是最終,我相信擁有沒有模棱兩可的標籤的數據,並且進行更多數據增強是該問題成功的關鍵。
模型Performacne並不像我想要的那樣好,但是我希望我從這個項目中學到的教訓對某人將來有用。
克隆存儲庫到您的計算機,並將命令行放置在存儲庫文件夾中:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
然後,創建一個名為venv的虛擬環境並安裝所需的軟件包:
make venv
make install-dev
運行以下命令以下載IM2LATEX-100K數據集並進行所有預處理。 (圖像裁剪步驟可能需要一個多小時。)
python scripts/prepare_data.py
一個示例命令開始培訓課程:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
可以在conf/config.yaml或命令行中修改配置。請參閱Hydra的文檔以了解更多信息。
最佳的模型檢查點將自動上傳到權重和偏見(W&B)(在培訓開始之前,將要求您註冊或登錄到W&B)。這是一個示例命令,可以從W&B下載訓練有素的模型檢查點:
python scripts/download_checkpoint.py RUN_PATH
用運行路徑替換run_path。運行路徑應為<entity>/<project>/<run_id>的格式。要查找特定實驗運行的運行路徑,請轉到儀表板中的概述選項卡。
例如,您可以使用以下命令下載我的最佳運行
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
該檢查點將下載到項目目錄下的名為artifacts的文件夾。
以下工具用於說明代碼庫:
isort :在Python腳本中導入語句。
black :遵守PEP8的代碼格式。
flake8 :在Python腳本中報告風格問題的代碼林格。
mypy :在Python腳本中執行靜態檢查。
使用以下命令運行所有檢查器和格式化器:
make lint
有關其配置,請參見root Directory處的pyproject.toml和setup.cfg 。
當提交提交時,預先承諾框架會自動完成類似的檢查。查看.pre-commit-config.yaml的配置。
創建API以使用訓練有素的模型進行預測。使用以下命令使服務器啟動並運行:
make api
您可以通過http://0.0.0.0.0:8000/docs通過生成的文檔探索API。
要運行簡化應用程序,請創建一個新的終端窗口,然後使用以下命令:
make streamlit
該應用程序應自動在瀏覽器中打開。您也可以通過訪問http:// localhost:8501來打開它。為了使應用程序工作,您需要下載實驗運行的工件(請參見上文)並運行API。
為API創建Docker映像:
make docker
該項目的靈感來自於UC Berkely課程完整堆棧深度學習的最終項目指南中的“項目思想”部分。其中一些代碼是從其實驗室中採用的。
MLOP-用ML製造,用於引入Makefile,預先投入,GitHub動作和Python包裝。
IM2LATEX-100K數據集的HarvardNLP/IM2markup。


