image to latex
1.0.0
Aplikasi yang memetakan gambar persamaan matematika lateks dengan kode lateks.
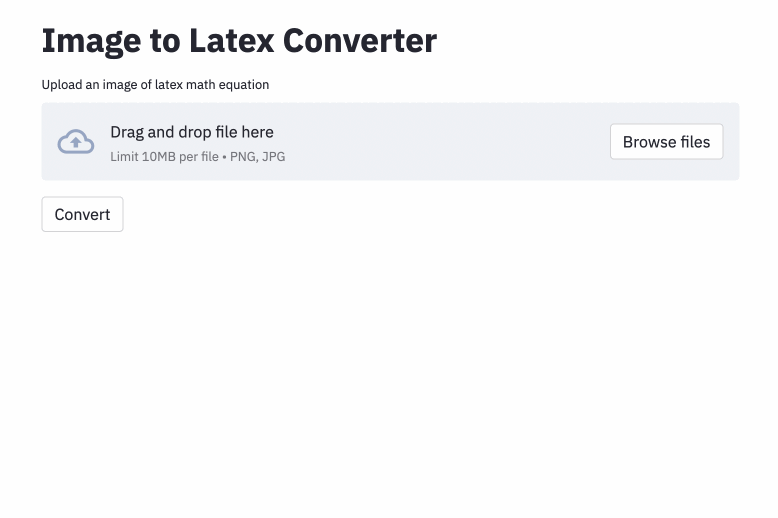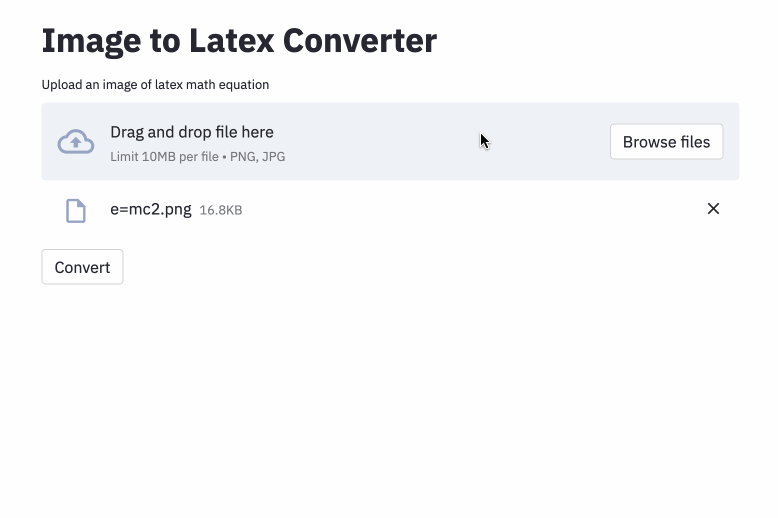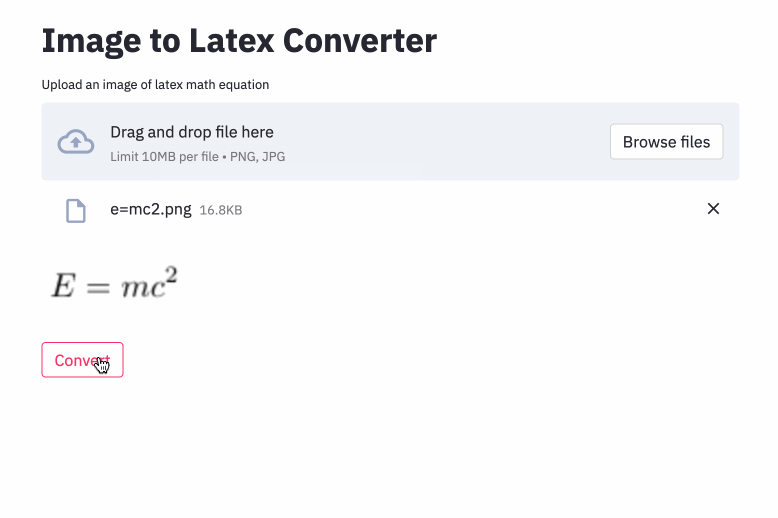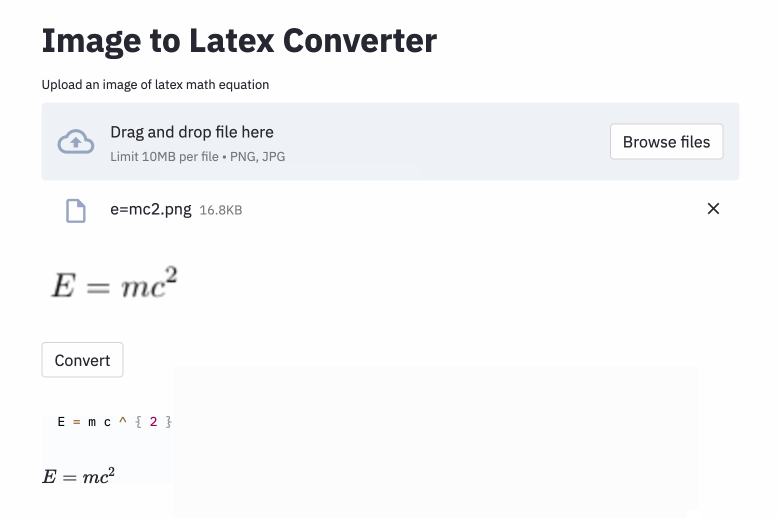
Masalah generasi gambar-ke-markup dicoba oleh Deng et al. (2016). Mereka mengekstraksi sekitar 100 ribu formula dengan parsing sumber lateks makalah dari arxiv. Mereka membuat formula menggunakan PDFLATEX dan mengonversi file PDF yang diberikan ke format PNG. Versi dataset mereka yang mentah dan preproses tersedia secara online. Dalam model mereka, CNN pertama kali digunakan untuk mengekstrak fitur gambar. Barisan fitur kemudian dikodekan menggunakan RNN. Akhirnya, fitur yang dikodekan digunakan oleh decoder RNN dengan mekanisme perhatian. Model ini memiliki total 9,48 juta parameter. Baru -baru ini, Transformer telah menyalip RNN untuk banyak tugas bahasa, jadi saya pikir saya bisa mencobanya dalam masalah ini.
Menggunakan dataset mereka, saya melatih model yang menggunakan ResNet-18 sebagai encoder dengan pengkodean posisi 2D dan transformator sebagai dekoder dengan kehilangan silang-entropi. (Mirip dengan yang dijelaskan dalam Singh et al. (2021), kecuali bahwa saya menggunakan resnet hanya hingga blok 3 untuk mengurangi biaya komputasi, dan saya mengecualikan pengkodean nomor garis karena tidak berlaku untuk masalah ini.) Model ini memiliki sekitar 3 juta parameter.
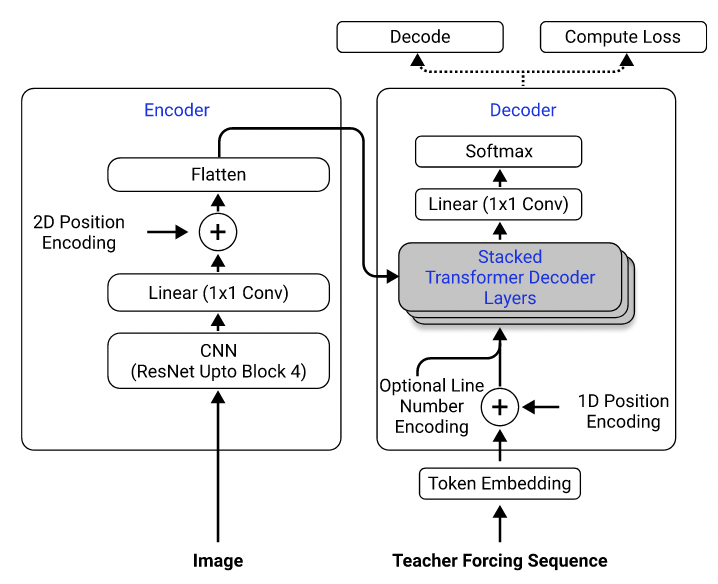
Arsitektur Model. Diambil dari Singh et al. (2021).
Awalnya, saya menggunakan dataset praproses untuk melatih model saya, karena gambar praproses downsampled ke setengah dari ukuran aslinya untuk efisiensi, dan dikelompokkan dan empuk menjadi ukuran yang sama untuk memfasilitasi batching. Namun, preprocessing kaku ini ternyata menjadi batasan yang sangat besar. Meskipun model dapat mencapai kinerja yang masuk akal pada set tes (yang diproses dengan cara yang sama seperti set pelatihan), itu tidak menggeneralisasi dengan baik ke gambar di luar dataset, kemungkinan besar karena kualitas gambar, bantalan, dan ukuran font sangat berbeda dari gambar dalam dataset. Fenomena ini juga telah diamati oleh orang lain yang telah mencoba masalah yang sama menggunakan dataset yang sama (misalnya, proyek ini, masalah ini dan masalah ini).
Untuk tujuan ini, saya menggunakan dataset mentah dan memasukkan augmentasi gambar (misalnya penskalaan acak, noise Gaussian) dalam pipa pemrosesan data saya untuk meningkatkan keragaman sampel. Selain itu, tidak seperti Deng et al. (2016), saya tidak mengelompokkan gambar berdasarkan ukuran. Sebaliknya, saya mencicipi mereka secara seragam dan mengangkutnya dengan ukuran gambar terbesar dalam batch, sehingga model harus belajar bagaimana beradaptasi dengan ukuran padding yang berbeda.
Masalah tambahan yang saya hadapi dalam dataset:
left( dan right) terlihat sama seperti ( dan ) ), jadi saya menormalkannya.vspace{2px} dan hspace{0.3mm} ). Namun, panjang ruang itu sulit untuk dinilai bahkan untuk manusia. Juga, ada banyak cara untuk mengekspresikan jarak yang sama (mis. 1 cm = 10 mm). Akhirnya, saya tidak ingin model menghasilkan kode pada gambar kosong, jadi saya menghapusnya. (Saya hanya menghapus vspace dan hspace , tetapi ternyata ada banyak perintah untuk jarak horizontal. Saya hanya menyadari bahwa selama analisis kesalahan. Lihat di bawah.) Lari terbaik memiliki tingkat kesalahan karakter (CER) 0,17 dalam set tes. Berikut adalah contoh dari dataset uji:
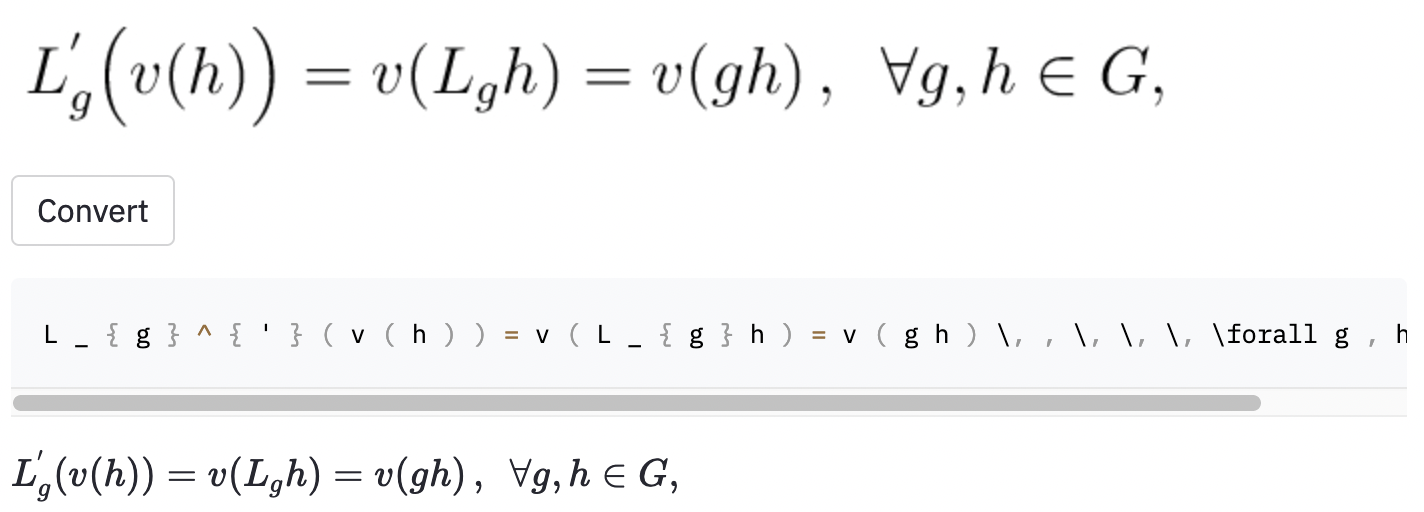
~ , sedangkan model yang digunakan , jadi ini masih dihitung sebagai kesalahan.Saya juga mengambil beberapa tangkapan layar di beberapa artikel Wikipedia acak untuk melihat apakah model tersebut menggeneralisasi ke gambar di luar dataset:

cal . 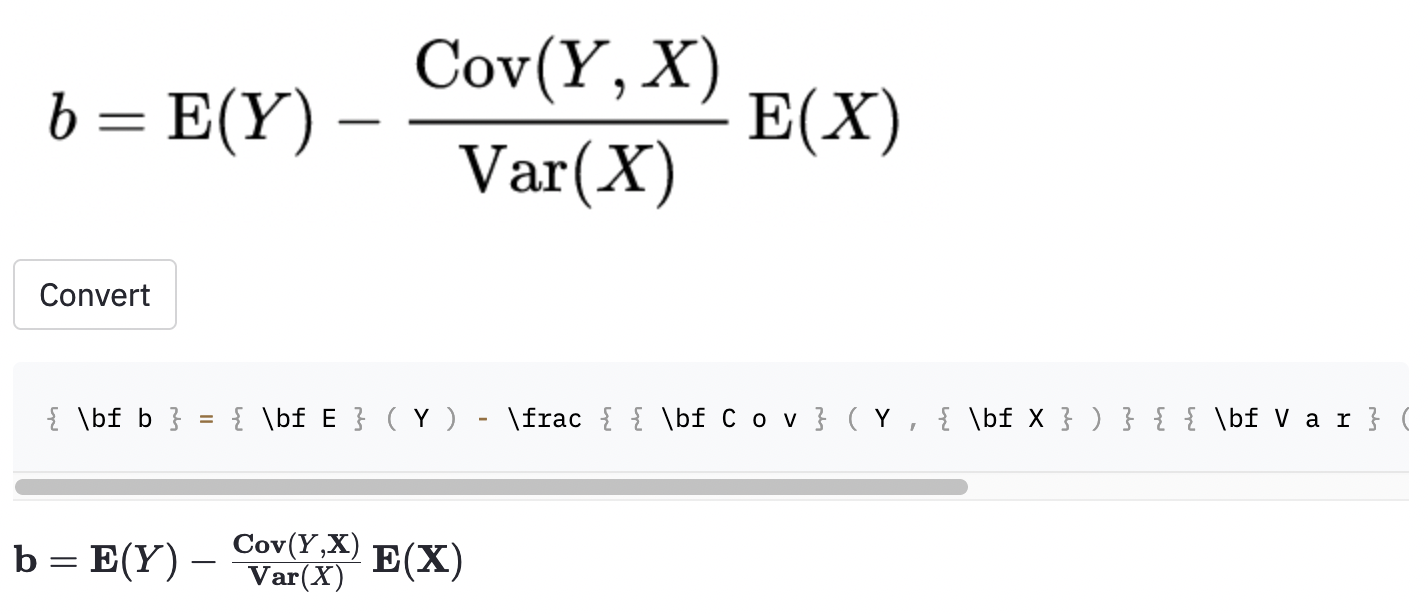
Model ini juga tampaknya memiliki beberapa masalah ketika gambar lebih besar dari apa yang ada di dataset. Mungkin saya seharusnya meningkatkan kisaran faktor rescaling dalam proses augmentasi data.
Saya pikir saya seharusnya mendefinisikan ruang lingkup proyek dengan lebih baik:
( , big( , Big( , bigg( , Bigg( )?Pertanyaan -pertanyaan ini harus digunakan untuk memandu proses pembersihan data.
Saya menemukan alat yang cukup mapan bernama Mathpix Snip yang mengubah formula tulisan tangan menjadi kode lateks. Ukuran kosa kata sekitar 200. Tidak termasuk angka dan huruf bahasa Inggris, jumlah perintah lateks yang dapat dihasilkannya sebenarnya tepat di atas 100. (Ukuran kosa kata IM2LATEX-100K hampir 500). Ini hanya mencakup dua perintah jarak horizontal ( quad dan qquad ), dan tidak mengenali berbagai ukuran tanda kurung. Perphas yang membatasi serangkaian kosakata terbatas adalah apa yang seharusnya saya lakukan, karena ada begitu banyak ambiguitas di lateks dunia nyata.
Kemungkinan perbaikan yang jelas dari pekerjaan ini meliputi (1) melatih model untuk lebih banyak zaman (demi waktu, saya hanya melatih model untuk 15 zaman, tetapi kehilangan validasi masih turun), (2) menggunakan pencarian balok (saya hanya menerapkan pencarian serakah), (3) menggunakan model yang lebih besar (mis. Saya tidak melakukan semua ini, karena saya memiliki sumber daya komputasi yang terbatas (saya menggunakan Google Colab). Tetapi pada akhirnya, saya percaya memiliki data yang tidak memiliki label yang ambigu dan melakukan lebih banyak augmentasi data adalah kunci keberhasilan masalah ini.
Model Performacne tidak sebagus yang saya inginkan, tapi saya harap pelajaran yang saya pelajari dari proyek ini berguna bagi seseorang yang ingin mengatasi masalah serupa di masa depan.
Kloning repositori ke komputer Anda dan posisikan baris perintah Anda di dalam folder repositori:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
Kemudian, buat lingkungan virtual bernama venv dan instal paket yang diperlukan:
make venv
make install-dev
Jalankan perintah berikut untuk mengunduh dataset IM2LATEX-100K dan lakukan semua preprocessing. (Langkah tanam gambar dapat memakan waktu lebih dari satu jam.)
python scripts/prepare_data.py
Perintah contoh untuk memulai sesi pelatihan:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
Konfigurasi dapat dimodifikasi dalam conf/config.yaml atau di baris perintah. Lihat dokumentasi Hydra untuk mempelajari lebih lanjut.
Pos Pemeriksaan Model Terbaik akan diunggah ke Bobot & Bias (W&B) secara otomatis (Anda akan diminta untuk mendaftar atau masuk ke W&B sebelum pelatihan dimulai). Berikut adalah contoh perintah untuk mengunduh pos pemeriksaan model terlatih dari W&B:
python scripts/download_checkpoint.py RUN_PATH
Ganti run_path dengan jalur lari Anda. Jalur yang dijalankan harus dalam format <entity>/<project>/<run_id> . Untuk menemukan jalur lari untuk percobaan tertentu, buka tab Ikhtisar di dasbor.
Misalnya, Anda dapat menggunakan perintah berikut untuk mengunduh jalan terbaik saya
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
Pos Pemeriksaan akan diunduh ke folder bernama artifacts di bawah Direktori Proyek.
Alat berikut digunakan untuk meletakkan basis kode:
isort : Sorts dan format pernyataan impor dalam skrip Python.
black : Formatter kode yang menganut pep8.
flake8 : Linter kode yang melaporkan masalah gaya dalam skrip Python.
mypy : Melakukan pemeriksaan jenis statis dalam skrip Python.
Gunakan perintah berikut untuk menjalankan semua checker dan formatters:
make lint
Lihat pyproject.toml dan setup.cfg di direktori root untuk konfigurasi mereka.
Pemeriksaan serupa dilakukan secara otomatis oleh kerangka kerja pra-komit ketika komit dibuat. Lihat .pre-commit-config.yaml untuk konfigurasi.
API dibuat untuk membuat prediksi menggunakan model terlatih. Gunakan perintah berikut untuk menjalankan dan menjalankan server:
make api
Anda dapat menjelajahi API melalui dokumentasi yang dihasilkan di http://0.0.0.0:8000/docs.
Untuk menjalankan aplikasi StreamLit, buat jendela terminal baru dan gunakan perintah berikut:
make streamlit
Aplikasi harus dibuka di browser Anda secara otomatis. Anda juga dapat membukanya dengan mengunjungi http: // localhost: 8501. Agar aplikasi berfungsi, Anda perlu mengunduh artefak dari percobaan yang dijalankan (lihat di atas) dan minta API dan berjalan.
Untuk membuat gambar Docker untuk API:
make docker
Proyek ini terinspirasi oleh bagian Project Ideas dalam pedoman proyek akhir dari kursus penuh tumpukan pembelajaran mendalam di UC Berkely. Beberapa kode diadopsi dari laboratoriumnya.
MLOPS - Dibuat dengan ML untuk memperkenalkan Makefile, Pra -Komit, Tindakan GitHub dan kemasan Python.
Harvardnlp/im2markup untuk dataset IM2LATEX-100K.


