image to latex
1.0.0
将乳胶数学方程式图像映射到乳胶代码的应用程序。
Deng等人尝试了图像到标记的问题。 (2016)。他们通过解析Arxiv的乳胶来源提取了约100K公式。他们使用PDFLATEX渲染公式,并将渲染的PDF文件转换为PNG格式。其数据集的原始和预处理版本可在线获得。在他们的模型中,CNN首先用于提取图像特征。然后使用RNN编码功能的行。最后,带有注意机制的RNN解码器使用编码的特征。该模型总共有948万个参数。最近,变压器已超过了许多语言任务的RNN,因此我认为我可以在此问题中尝试一下。
使用他们的数据集,我训练了一种模型,该模型使用Resnet-18作为具有2D位置编码的编码器,而变压器则用作交叉渗透损失的解码器。 (类似于Singh等人(2021)中描述的,除了我仅使用重新连接到第3块以降低计算成本,而且我排除了编号编码,因为它不适用于此问题。)该模型大约有300万参数。
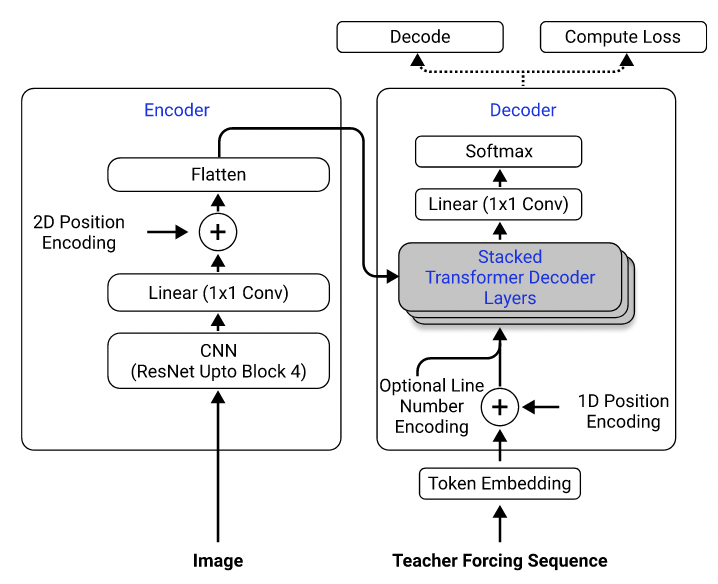
模型架构。取自Singh等。 (2021)。
最初,我使用预处理的数据集来训练我的模型,因为预处理图像被降低到其原始尺寸的一半以提高效率,并分组并填充相似的尺寸以方便批处理。但是,这种严格的预处理结果是一个巨大的限制。尽管该模型可以在测试集上实现合理的性能(以与培训集相同的方式进行了预处理),但它并不能很好地推广到数据集外的图像,这很可能是因为图像质量,填充和字体大小与数据集中的图像差异很大。其他人使用相同的数据集尝试了相同问题的其他人也观察到了这种现象(例如,这个项目,此问题和此问题)。
为此,我使用了原始数据集,并在数据处理管道中包括图像增强(例如随机缩放,高斯噪声)来增加样品的多样性。此外,与Deng等人不同。 (2016年),我没有按大小分组图像。相反,我对它们进行了统一的样本,并将它们填充到批处理中最大图像的大小,以便模型必须学习如何适应不同的填充大小。
我在数据集中遇到的其他问题:
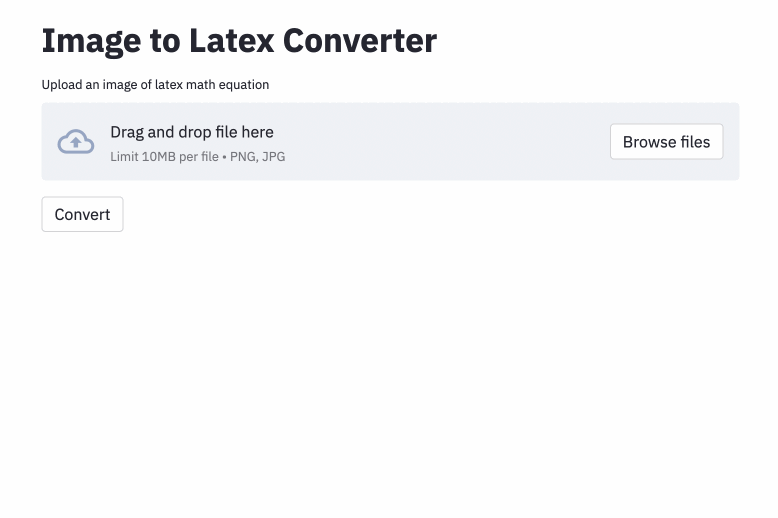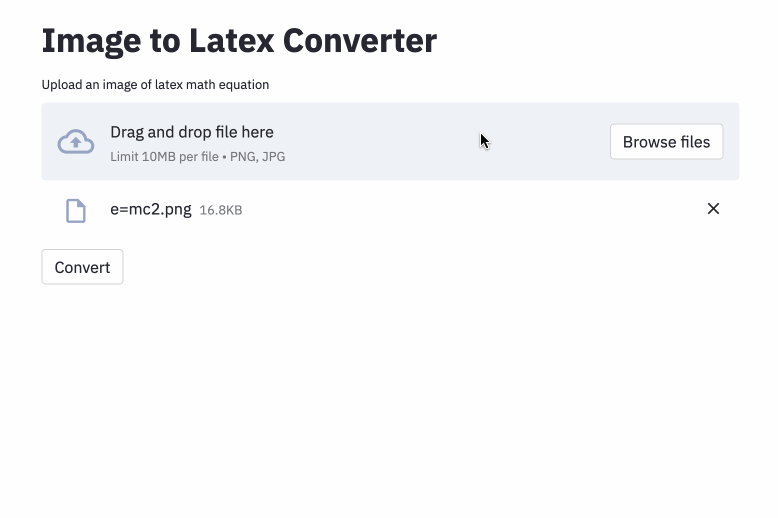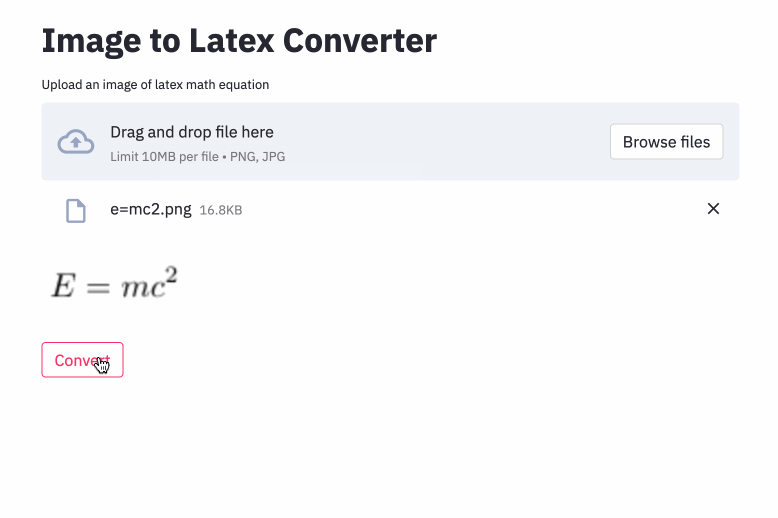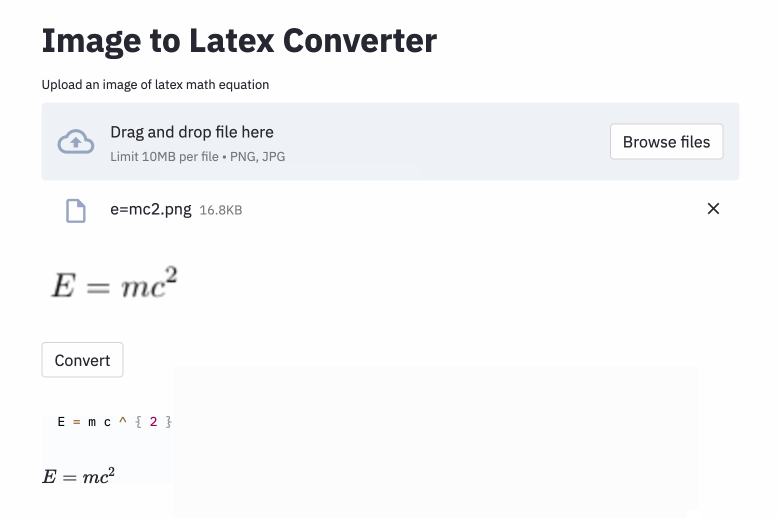
left(和right)看起来与( and )相同),因此我对它们进行了归一化。vspace{2px}和hspace{0.3mm} )。但是,即使对于人类,空间的长度也很难判断。同样,有许多表达相同间距的方法(例如1 cm = 10 mm)。最后,我不希望该模型在空白图像上生成代码,因此我将其删除。 (我只删除了vspace和hspace ,但是事实证明有很多水平间距的命令。我只在错误分析中意识到这一点。)请参见下文。 最佳运行在测试集中的字符错误率(CER)为0.17。这是测试数据集中的一个示例:
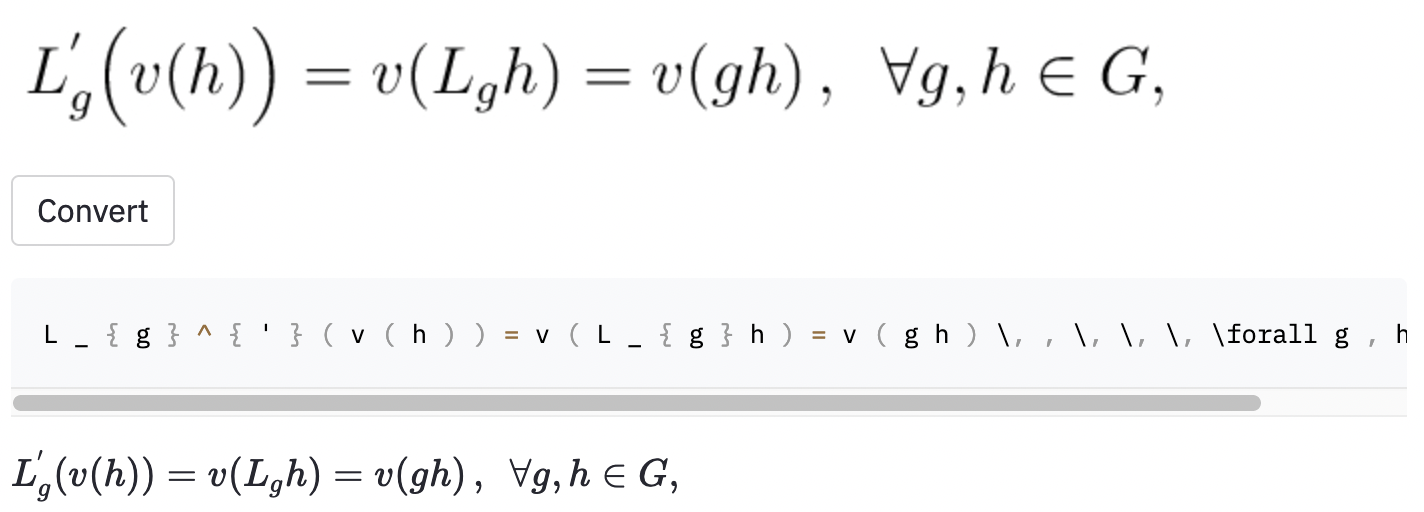
~创建了水平间距,而使用的模型,因此仍被视为误差。我还在一些随机的Wikipedia文章中拍摄了一些屏幕截图,以查看该模型是否将图像概括为数据集外的图像:

cal渲染代码。 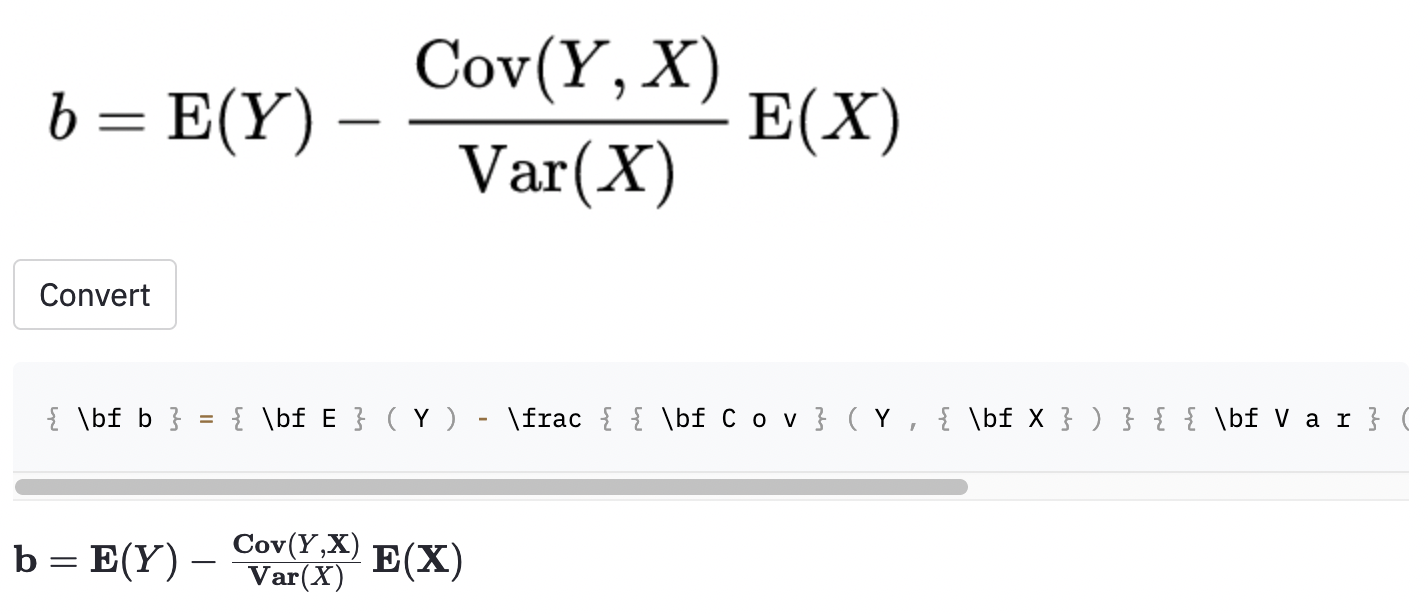
当图像大于数据集中的图像时,该模型似乎也遇到了一些麻烦。也许我应该增加数据增强过程中的重新恢复因素的范围。
我认为我应该更好地定义项目的范围:
( big( , Big( , bigg( , Bigg( )?这些问题应用于指导数据清洁过程。
我找到了一个名为MathPix Snip的精心建立的工具,该工具将手写配方转换为乳胶代码。它的词汇大小约为200。不包括数字和英文字母,它可以产生的乳胶命令的数量实际上略高于100。它仅包括两个水平间距命令( quad和qquad ),并且不识别不同尺寸的括号。我应该做的事情始终局限于有限的词汇,因为现实世界乳胶中有很多歧义。
这项工作的明显可能改进包括(1)训练该模型的更多时代(为了时间,我只训练了15个时代的型号,但验证损失仍在下降),(2)使用束搜索(I仅实现贪婪搜索),(3)使用较大的模型(例如,使用Resnet-34而不是Resnet-34而不是Resnet-34)和一些超级PAREN,并进行了一些超级标准。我没有这样做,因为我的计算资源有限(我正在使用Google Colab)。但是最终,我相信拥有没有模棱两可的标签的数据,并且进行更多数据增强是该问题成功的关键。
模型Performacne并不像我想要的那样好,但是我希望我从这个项目中学到的教训对某人将来有用。
克隆存储库到您的计算机,并将命令行放置在存储库文件夹中:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
然后,创建一个名为venv的虚拟环境并安装所需的软件包:
make venv
make install-dev
运行以下命令以下载IM2LATEX-100K数据集并进行所有预处理。 (图像裁剪步骤可能需要一个多小时。)
python scripts/prepare_data.py
一个示例命令开始培训课程:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
可以在conf/config.yaml或命令行中修改配置。请参阅Hydra的文档以了解更多信息。
最佳的模型检查点将自动上传到权重和偏见(W&B)(在培训开始之前,将要求您注册或登录到W&B)。这是一个示例命令,可以从W&B下载训练有素的模型检查点:
python scripts/download_checkpoint.py RUN_PATH
用运行路径替换run_path。运行路径应为<entity>/<project>/<run_id>的格式。要查找特定实验运行的运行路径,请转到仪表板中的概述选项卡。
例如,您可以使用以下命令下载我的最佳运行
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
该检查点将下载到项目目录下的名为artifacts的文件夹。
以下工具用于说明代码库:
isort :在Python脚本中导入语句。
black :遵守PEP8的代码格式。
flake8 :在Python脚本中报告风格问题的代码林格。
mypy :在Python脚本中执行静态检查。
使用以下命令运行所有检查器和格式化器:
make lint
有关其配置,请参见root Directory处的pyproject.toml和setup.cfg 。
当提交提交时,预先承诺框架会自动完成类似的检查。查看.pre-commit-config.yaml的配置。
创建API以使用训练有素的模型进行预测。使用以下命令使服务器启动并运行:
make api
您可以通过http://0.0.0.0.0:8000/docs通过生成的文档探索API。
要运行简化应用程序,请创建一个新的终端窗口,然后使用以下命令:
make streamlit
该应用程序应自动在浏览器中打开。您也可以通过访问http:// localhost:8501来打开它。为了使应用程序工作,您需要下载实验运行的工件(请参见上文)并运行API。
为API创建Docker映像:
make docker
该项目的灵感来自于UC Berkely课程完整堆栈深度学习的最终项目指南中的“项目思想”部分。其中一些代码是从其实验室中采用的。
MLOP-用ML制造,用于引入Makefile,预先投入,GitHub动作和Python包装。
IM2LATEX-100K数据集的HarvardNLP/IM2markup。


