image to latex
1.0.0
Eine Anwendung, die ein Bild einer Latex -Mathematikgleichung in Latexcode ordnet.
Das Problem der Bild-zu-Markt-Erzeugung wurde von Deng et al. (2016). Sie extrahierten etwa 100.000 Formeln, indem sie Latexquellen von Papieren aus dem Arxiv analysierten. Sie machten die Formeln mit PDflatex und konvertierten die gerenderten PDF -Dateien in PNG -Format. Die rohen und vorverarbeiteten Versionen ihres Datensatzes sind online verfügbar. In ihrem Modell wird zuerst ein CNN verwendet, um Bildmerkmale zu extrahieren. Die Zeilen der Funktionen werden dann mit einem RNN codiert. Schließlich werden die codierten Merkmale von einem RNN -Decoder mit Aufmerksamkeitsmechanismus verwendet. Das Modell hat insgesamt 9,48 Millionen Parameter. Vor kurzem hat Transformer RNN für viele Sprachaufgaben überholt, also dachte ich, ich könnte es in diesem Problem versuchen.
Mit ihrem Datensatz habe ich ein Modell trainiert, das Resnet-18 als Encoder mit 2D-Positionscodierung und einen Transformator als Decoder mit Kreuzentropieverlust verwendet. (Ähnlich wie in Singh et al. (2021), außer dass ich RESNET nur bis zu Block 3 verwendet habe, um die Rechenkosten zu senken, und die Leitungsnummer -Codierung ausgeschlossen, da es nicht für dieses Problem gilt.) Das Modell hat rund 3 Millionen Parameter.
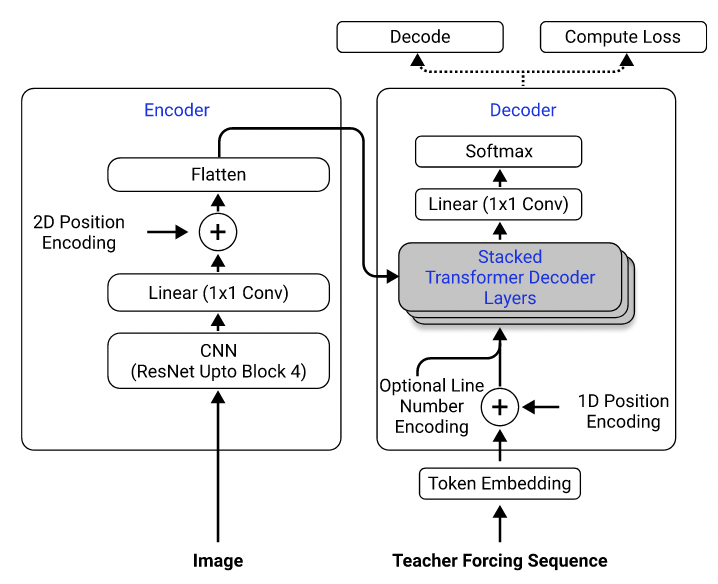
Modellarchitektur. Von Singh et al. (2021).
Zunächst habe ich den vorverarbeiteten Datensatz verwendet, um mein Modell zu trainieren, da die vorverarbeiteten Bilder auf die Hälfte ihrer ursprünglichen Größen für die Effizienz verkleinert und in ähnliche Größen gepolstert werden, um die Charge zu erleichtern. Diese starre Vorverarbeitung stellte sich jedoch als enorme Einschränkung heraus. Obwohl das Modell eine angemessene Leistung im Testsatz erzielen könnte (was auf die gleiche Weise wie das Trainingssatz vorverarbeitet wurde), verallgemeinert es sich nicht gut auf Bilder außerhalb des Datensatzes, wahrscheinlich weil sich die Bildqualität, die Polsterung und die Schriftgröße so unterschiedlich von den Bildern im Datensatz unterscheiden. Dieses Phänomen wurde auch von anderen beobachtet, die das gleiche Problem unter Verwendung desselben Datensatzes (z. B. dieses Projekt, dieses Problems und dieses Problems) versucht haben.
Zu diesem Zweck habe ich den Rohdatensatz verwendet und die Bildvergrößerung (z. B. zufällige Skalierung, Gaußsche Rauschen) in meine Datenverarbeitungspipeline einbezogen, um die Vielfalt der Proben zu erhöhen. Darüber hinaus, im Gegensatz zu Deng et al. (2016), ich habe Bilder nicht nach Größe gruppiert. Vielmehr habe ich sie gleichmäßig probiert und sie auf die Größe des größten Bildes in der Charge gepolstert, damit das Modell lernen muss, wie man sich an verschiedene Polstergrößen anpasst.
Zusätzliche Probleme, mit denen ich im Datensatz konfrontiert bin:
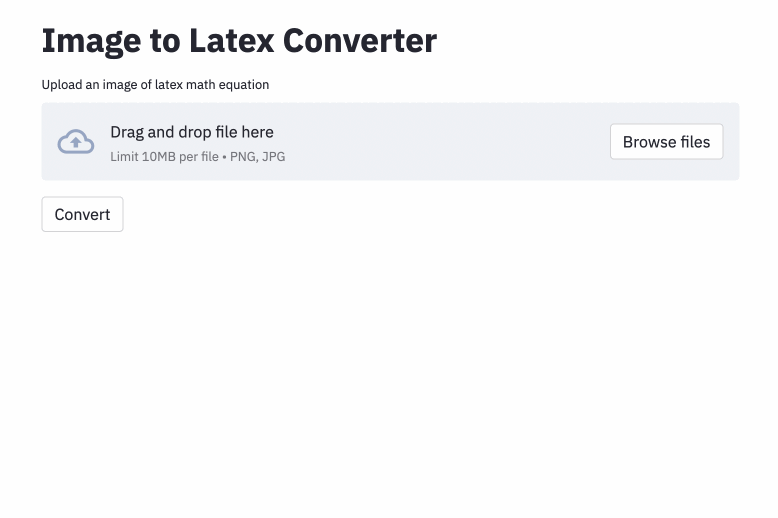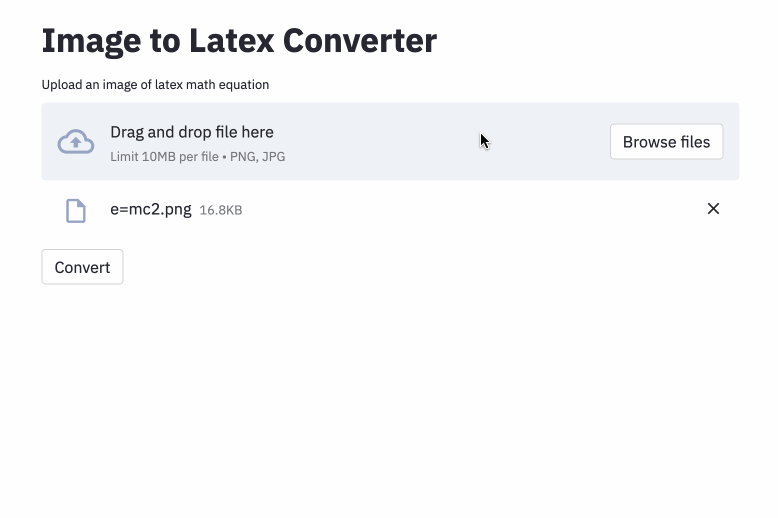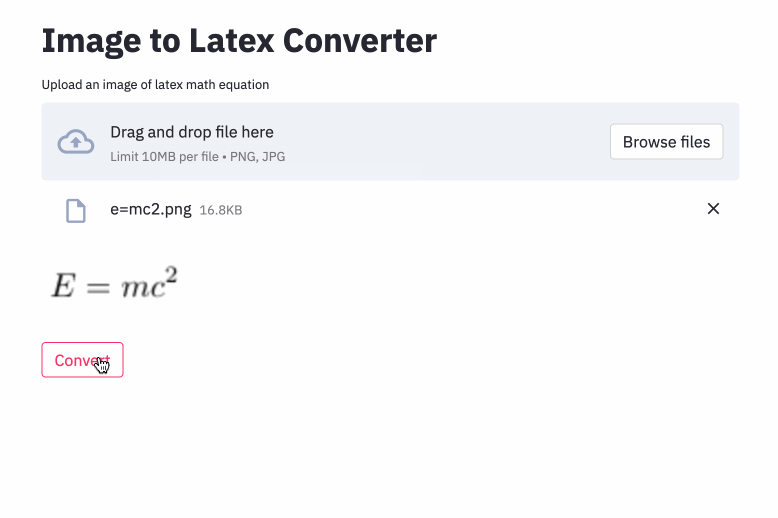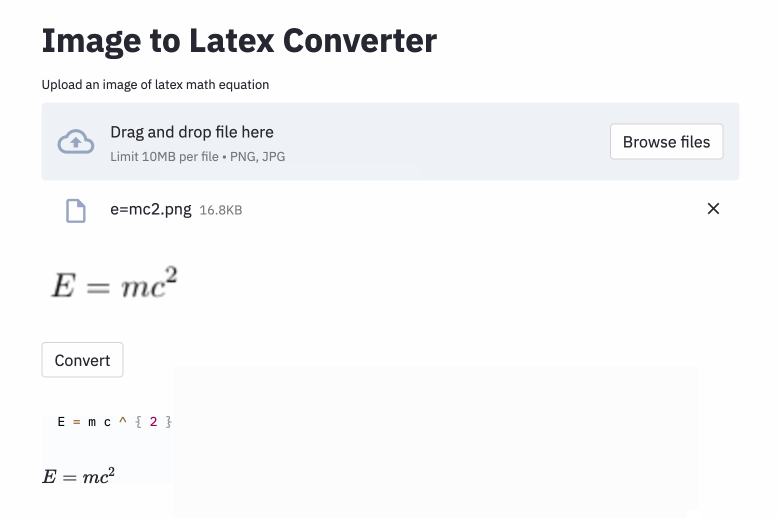
left( und right) sehen genauso aus wie ( und ) ), sodass ich sie normalisiert habe.vspace{2px} und hspace{0.3mm} ). Die Länge des Raums ist jedoch diffkult, auch für Menschen zu urteilen. Es gibt auch viele Möglichkeiten, den gleichen Abstand auszudrücken (z. B. 1 cm = 10 mm). Schließlich möchte ich nicht, dass das Modell Code für leere Bilder generiert, also habe ich sie entfernt. (Ich habe nur vspace und hspace entfernt, aber es stellte sich heraus, dass es viele Befehle für den horizontalen Abstand gibt. Ich habe nur festgestellt, dass während der Fehleranalyse. Siehe unten.) Der beste Lauf hat eine Zeichenfehlerrate (CER) von 0,17 im Testsatz. Hier ist ein Beispiel aus dem Testdatensatz:
~ erstellt, während das Modell verwendet wurde , so dass dies immer noch als Fehler gezählt wurde.Ich habe auch einige Screenshots in einigen zufälligen Wikipedia -Artikeln gemacht, um festzustellen, ob das Modell auf Bilder außerhalb des Datensatzes verallgemeinert wird:

cal nicht rendern. 
Das Modell scheint auch einige Probleme zu haben, wenn das Bild größer ist als die im Datensatz. Vielleicht hätte ich den Spektrum des Umschlüssefaktors im Datenerweiterungsprozess erhöhen sollen.
Ich denke, ich hätte den Umfang des Projekts besser definieren sollen:
( , big( , Big( , bigg( , Bigg( )?Diese Fragen sollten verwendet werden, um den Datenreinigungsprozess zu leiten.
Ich fand ein ziemlich etabliertes Tool namens Mathpix Snip, das handgeschriebene Formeln in Latexcode umwandelt. Die Größe des Wortschatzes beträgt ungefähr 200. Mit Ausnahme von Zahlen und englischen Buchstaben liegt die Anzahl der Latexbefehle, die er erzeugen kann, tatsächlich über 100. Es enthält nur zwei horizontale Abstandsbefehle ( quad und qquad ) und erkennt verschiedene Größen von Klammern nicht. Perphas, die sich auf einen begrenzten Satz Vokabular beschränken, hätte ich hätte tun sollen, da es im realen Latex so viele Unklarheiten gibt.
Zu den offensichtlichen möglichen Verbesserungen dieser Arbeit gehören (1) das Training des Modells für weitere Epochen (zum Zeitpunkt der Zeit habe ich das Modell nur für 15 Epochen geschult, aber der Validierungsverlust geht weiter aus), (2) mit der Strahlsuche (ich habe nur gierige Suche implementiert), (3) mit einem größeren Modell (z. B. RESNET-34) und einem Hyperparameter-Tuning verwenden. Ich habe keine davon gemacht, weil ich nur begrenzte Rechenressourcen hatte (ich habe Google Colab verwendet). Aber letztendlich glaube ich, dass Daten, die keine mehrdeutigen Beschriftungen haben und mehr Datenvergrößerung durchführen, die Schlüssel zum Erfolg dieses Problems sind.
Das Modell Performacne ist nicht so gut, wie ich es will, aber ich hoffe, die Lektionen, die ich aus diesem Projekt gelernt habe, sind für jemanden nützlich, der in Zukunft ähnliche Probleme angehen möchte.
Klonen Sie das Repository auf Ihren Computer und positionieren Sie Ihre Befehlszeile im Ordner "Repository":
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
Erstellen Sie dann eine virtuelle Umgebung mit dem Namen venv und installieren Sie die erforderlichen Pakete:
make venv
make install-dev
Führen Sie den folgenden Befehl aus, um den IM2Latex-100K-Datensatz herunterzuladen und alle Vorverarbeitungen durchzuführen. (Der Bild zu einer Stunde kann über eine Stunde dauern.)
python scripts/prepare_data.py
Ein Beispielbefehl zum Starten einer Trainingseinheit:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
Konfigurationen können in conf/config.yaml oder in Befehlszeile geändert werden. Siehe Hydras Dokumentation, um mehr zu erfahren.
Der beste Modellkontrollpunkt wird auf Gewichte und Vorurteile (W & B) automatisch hochgeladen (Sie werden aufgefordert, sich bei W & B zu registrieren oder sich bei W & B anzumelden). Hier ist ein Beispielbefehl zum Herunterladen eines geschulten Modell -Checkpoint von W & B:
python scripts/download_checkpoint.py RUN_PATH
Ersetzen Sie Run_Path durch den Pfad Ihres Laufs. Der Run -Pfad sollte im Format von <entity>/<project>/<run_id> sein. Um den Laufpfad für einen bestimmten Experiment -Lauf zu finden, gehen Sie zur Registerkarte Übersicht im Dashboard.
Zum Beispiel können Sie den folgenden Befehl verwenden, um meinen besten Lauf herunterzuladen
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
Der Checkpoint wird in einen Ordner mit dem Namen artifacts unter dem Projektverzeichnis heruntergeladen.
Die folgenden Tools werden verwendet, um die Codebasis abzugeben:
isort : Sortiert und Formate importieren Aussagen in Python -Skripten.
black : Eine Codeformaterin, die sich an Pep8 hält.
flake8 : Ein Code -Verlunter, der stilistische Probleme in Python -Skripten meldet.
mypy : führt statische Überprüfung in Python -Skripten durch.
Verwenden Sie den folgenden Befehl, um alle Checkers und Formatierungen auszuführen:
make lint
Siehe pyproject.toml und setup.cfg im Stammverzeichnis für ihre Konfigurationen.
Ähnliche Überprüfungen werden vom Framework vor dem Kommunikation automatisch durchgeführt, wenn ein Commit eingerichtet wird. Schauen Sie sich .pre-commit-config.yaml für die Konfigurationen an.
Eine API wird erstellt, um Vorhersagen mit dem geschulten Modell zu treffen. Verwenden Sie den folgenden Befehl, um den Server in Betrieb zu nehmen:
make api
Sie können die API über die generierte Dokumentation unter http://0.0.0.0:8000/docs erkunden.
Erstellen Sie ein neues Terminalfenster und verwenden Sie den folgenden Befehl: So erstellen Sie die Streamlit -App: Verwenden Sie den folgenden Befehl:
make streamlit
Die App sollte automatisch in Ihrem Browser geöffnet werden. Sie können es auch öffnen, indem Sie http: // localhost: 8501 besuchen. Damit die App funktioniert, müssen Sie die Artefakte eines Experiment -Laufs herunterladen (siehe oben) und die API in Betrieb.
So erstellen Sie ein Docker -Bild für die API:
make docker
Dieses Projekt ist vom Abschnitt Projektideen in den endgültigen Projektrichtlinien des Kurses Full Stack Deep Learning bei UC Berkely inspiriert. Ein Teil des Code wird aus seinen Labors übernommen.
MLOPS - Hergestellt mit ML zur Einführung von Makefile, Pre -Commit-, Github -Aktionen und Python -Verpackungen.
Harvardnlp/IM2Markup für den IM2Latex-100K-Datensatz.


