image to latex
1.0.0
แอปพลิเคชั่นที่แมปรูปภาพของสมการคณิตศาสตร์ LaTex ไปยังโค้ด LaTex
ปัญหาของการสร้างภาพกับมาร์คอัพนั้นพยายามโดย Deng และคณะ (2016) พวกเขาสกัดสูตรประมาณ 100k โดยการแยกแหล่งที่มาของเอกสารจาก arxiv พวกเขาแสดงสูตรโดยใช้ PDFLATEX และแปลงไฟล์ PDF ที่แสดงผลเป็นรูปแบบ PNG ชุดข้อมูลดิบและรุ่นที่ผ่านการประมวลผลล่วงหน้ามีให้บริการออนไลน์ ในโมเดลของพวกเขา CNN จะใช้เป็นครั้งแรกในการแยกคุณสมบัติของภาพ แถวของคุณสมบัติจะถูกเข้ารหัสโดยใช้ RNN ในที่สุดคุณสมบัติที่เข้ารหัสจะถูกใช้โดยตัวถอดรหัส RNN พร้อมกลไกความสนใจ โมเดลมีพารามิเตอร์ทั้งหมด 9.48 ล้านพารามิเตอร์ เมื่อเร็ว ๆ นี้ Transformer ได้แซงหน้า RNN สำหรับงานภาษามากมายดังนั้นฉันคิดว่าฉันอาจลองใช้ปัญหานี้
การใช้ชุดข้อมูลของพวกเขาฉันได้ฝึกอบรมแบบจำลองที่ใช้ RESNET-18 เป็นตัวเข้ารหัสด้วยการเข้ารหัสตำแหน่ง 2D และหม้อแปลงเป็นตัวถอดรหัสที่มีการสูญเสียข้าม (คล้ายกับที่อธิบายไว้ใน Singh et al. (2021) ยกเว้นว่าฉันใช้ resnet เพียงแค่บล็อก 3 เพื่อลดต้นทุนการคำนวณและฉันยกเว้นการเข้ารหัสหมายเลขบรรทัดเนื่องจากไม่ได้ใช้กับปัญหานี้) โมเดลมีพารามิเตอร์ประมาณ 3 ล้านพารามิเตอร์
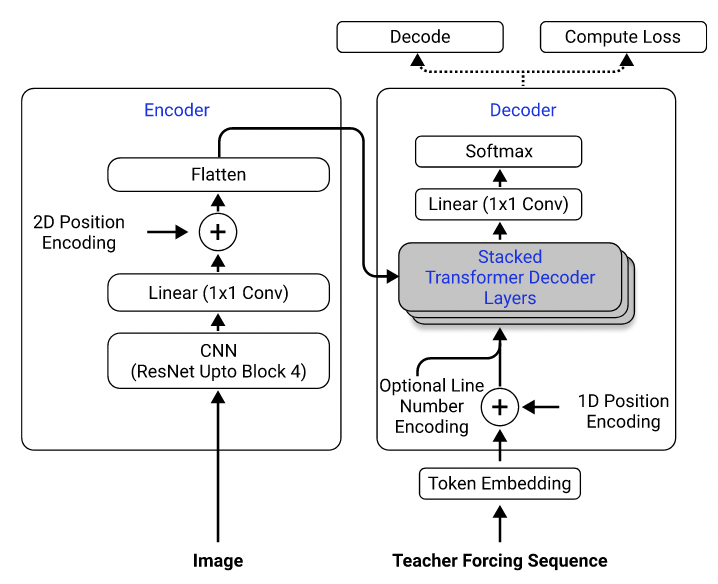
สถาปัตยกรรมแบบจำลอง นำมาจากซิงห์และคณะ (2021)
ในขั้นต้นฉันใช้ชุดข้อมูลที่ประมวลผลล่วงหน้าเพื่อฝึกอบรมแบบจำลองของฉันเนื่องจากภาพที่ประมวลผลล่วงหน้าจะลดขนาดลงครึ่งหนึ่งของขนาดดั้งเดิมเพื่อประสิทธิภาพและถูกจัดกลุ่มและเบาะเป็นขนาดที่ใกล้เคียงกันเพื่ออำนวยความสะดวกในการแบตช์ อย่างไรก็ตามการประมวลผลล่วงหน้าที่เข้มงวดนี้กลายเป็นข้อ จำกัด อย่างมาก แม้ว่าโมเดลจะสามารถบรรลุประสิทธิภาพที่สมเหตุสมผลในชุดทดสอบ (ซึ่งถูกประมวลผลล่วงหน้าเช่นเดียวกับชุดการฝึกอบรม) แต่ก็ไม่ได้พูดคุยกับภาพนอกชุดข้อมูลส่วนใหญ่เป็นเพราะคุณภาพของภาพการขยายและขนาดตัวอักษรนั้นแตกต่างจากภาพในชุดข้อมูล ปรากฏการณ์นี้ได้รับการสังเกตจากคนอื่น ๆ ที่พยายามแก้ไขปัญหาเดียวกันโดยใช้ชุดข้อมูลเดียวกัน (เช่นโครงการนี้ปัญหานี้และปัญหานี้)
ด้วยเหตุนี้ฉันใช้ชุดข้อมูล RAW และรวมการเพิ่มภาพ (เช่นการปรับขนาดแบบสุ่ม, เสียงรบกวนแบบเกาส์) ในไปป์ไลน์การประมวลผลข้อมูลของฉันเพื่อเพิ่มความหลากหลายของตัวอย่าง ยิ่งไปกว่านั้นต่างจาก Deng และคณะ (2016) ฉันไม่ได้จัดกลุ่มภาพตามขนาด แต่ฉันสุ่มตัวอย่างพวกเขาอย่างสม่ำเสมอและเบาะพวกเขากับขนาดของภาพที่ใหญ่ที่สุดในแบทช์เพื่อให้แบบจำลองต้องเรียนรู้วิธีการปรับให้เข้ากับขนาดของแผ่นรองที่แตกต่างกัน
ปัญหาเพิ่มเติมที่ฉันเผชิญในชุดข้อมูล:
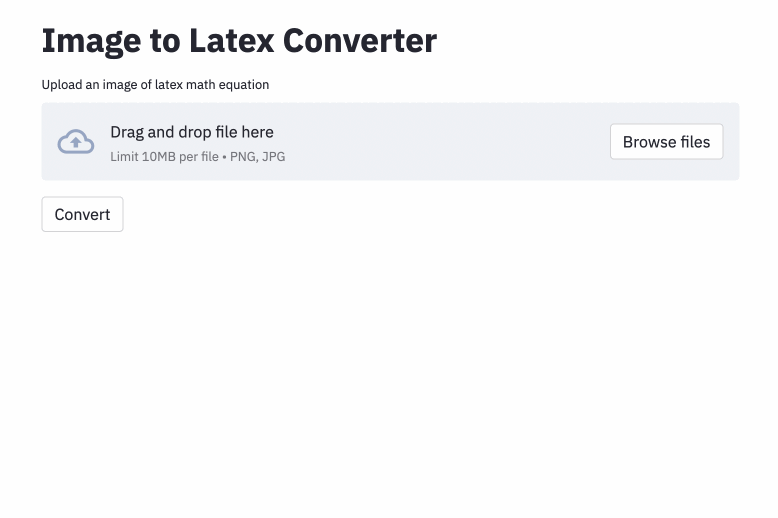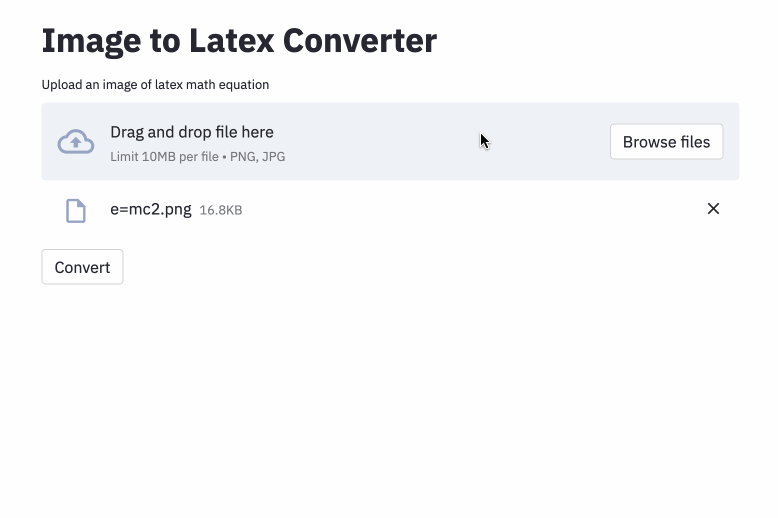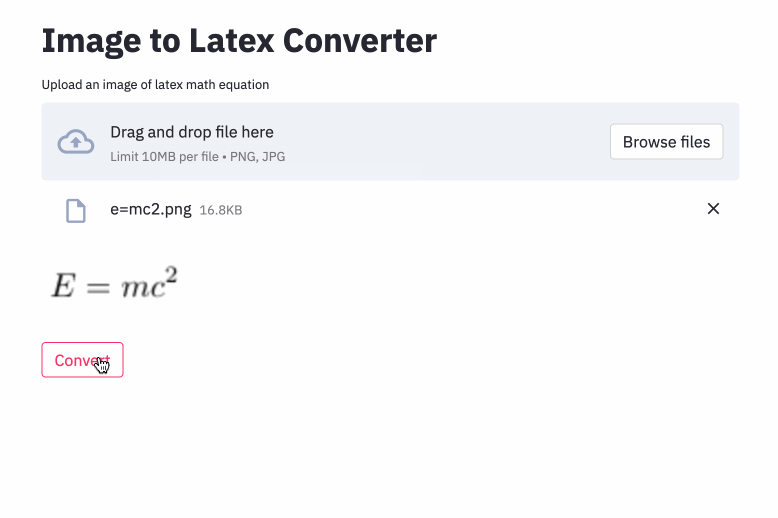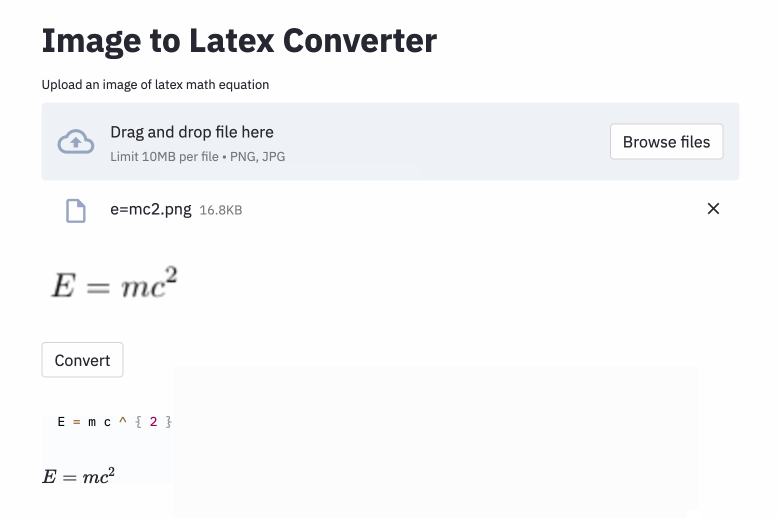
left( และ right) ดูเหมือนกับ ( และ ) ) ดังนั้นฉันจึงทำให้เป็นมาตรฐานvspace{2px} และ hspace{0.3mm} ) อย่างไรก็ตามความยาวของพื้นที่เป็นแบบกระจายที่จะตัดสินแม้กระทั่งกับมนุษย์ นอกจากนี้ยังมีหลายวิธีในการแสดงระยะห่างเดียวกัน (เช่น 1 ซม. = 10 มม.) ในที่สุดฉันไม่ต้องการให้โมเดลสร้างรหัสบนภาพว่างดังนั้นฉันจึงลบออก (ฉันลบ vspace และ hspace เท่านั้น แต่กลับกลายเป็นว่ามีคำสั่งมากมายสำหรับระยะห่างแนวนอนฉันรู้ว่าในระหว่างการวิเคราะห์ข้อผิดพลาดดูด้านล่าง) การวิ่งที่ดีที่สุดมีอัตราความผิดพลาดของอักขระ (CER) 0.17 ในชุดทดสอบ นี่คือตัวอย่างจากชุดข้อมูลทดสอบ:
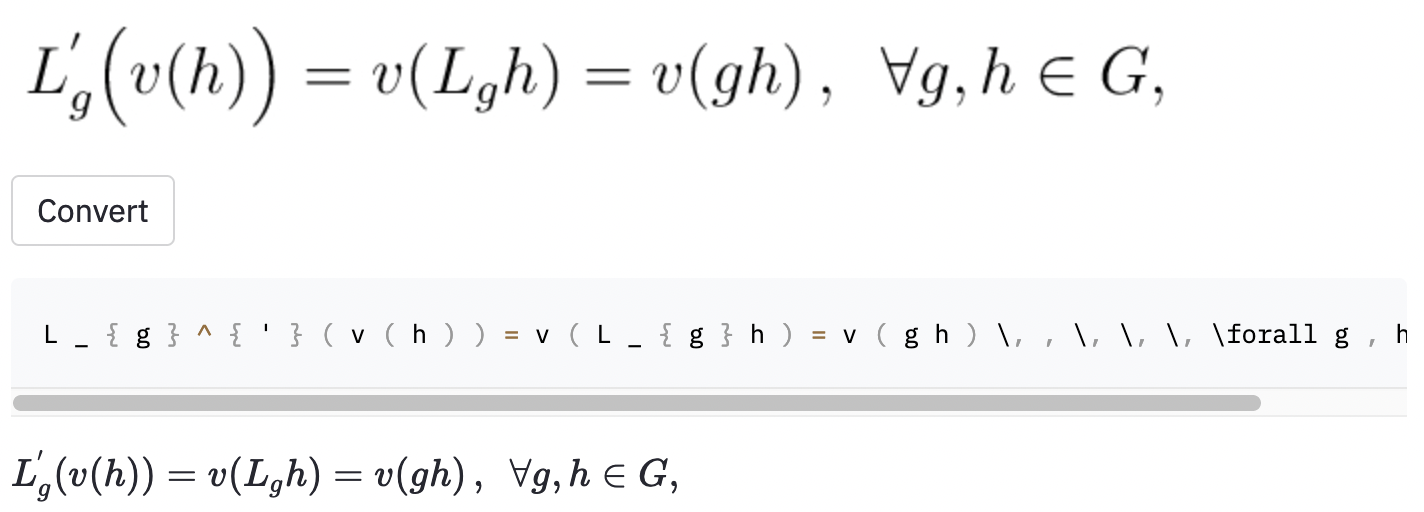
~ ในขณะที่โมเดลที่ใช้ , ดังนั้นสิ่งนี้ยังคงนับเป็นข้อผิดพลาดฉันยังถ่ายภาพหน้าจอบางส่วนในบทความ Wikipedia แบบสุ่มเพื่อดูว่าโมเดลทั่วไปเป็นภาพที่อยู่นอกชุดข้อมูลหรือไม่:

cal 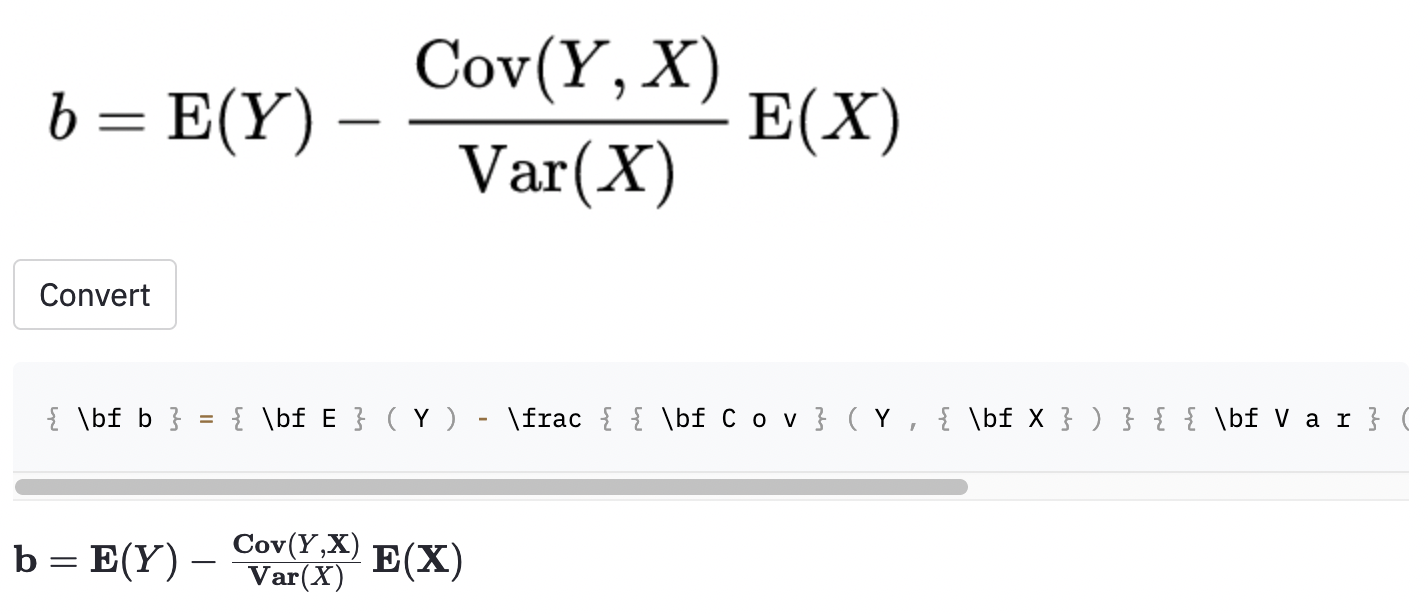
โมเดลดูเหมือนว่าจะมีปัญหาบางอย่างเมื่อภาพมีขนาดใหญ่กว่าสิ่งที่อยู่ในชุดข้อมูล บางทีฉันควรจะเพิ่มช่วงของปัจจัยการลดขนาดในกระบวนการเพิ่มข้อมูล
ฉันคิดว่าฉันควรกำหนดขอบเขตของโครงการให้ดีขึ้น:
( , big( , Big( , bigg( , Bigg( ) หรือไม่?คำถามเหล่านี้ควรใช้เพื่อเป็นแนวทางในกระบวนการทำความสะอาดข้อมูล
ฉันพบเครื่องมือที่สวยงามที่เรียกว่า Mathpix Snip ที่แปลงสูตรที่เขียนด้วยลายมือเป็นรหัส LaTex ขนาดคำศัพท์ของมันอยู่ที่ประมาณ 200 ไม่รวมตัวเลขและตัวอักษรภาษาอังกฤษจำนวนคำสั่ง LaTex ที่สามารถผลิตได้จริงสูงกว่า 100 (ขนาดคำศัพท์ของ IM2Latex-100K เกือบ 500) มันมีเพียงคำสั่งระยะห่างแนวนอนสองคำสั่ง ( quad และ qquad ) และไม่รู้จักวงเล็บขนาดที่แตกต่างกัน Perphas ที่ จำกัด คำศัพท์ที่ จำกัด คือสิ่งที่ฉันควรทำเนื่องจากมีความคลุมเครือมากมายในน้ำยางในโลกแห่งความเป็นจริง
การปรับปรุงที่เป็นไปได้อย่างชัดเจนของงานนี้รวมถึง (1) การฝึกอบรมแบบจำลองสำหรับยุคเพิ่มเติม (เพื่อประโยชน์ของเวลาฉันได้ฝึกฝนแบบจำลองสำหรับ 15 ยุคเท่านั้น แต่การสูญเสียการตรวจสอบยังคงลดลง) (2) การค้นหาลำแสง (ฉันใช้การค้นหาโลภเท่านั้น ฉันไม่ได้ทำสิ่งเหล่านี้เพราะฉันมีทรัพยากรการคำนวณที่ จำกัด (ฉันใช้ Google Colab) แต่ในที่สุดฉันเชื่อว่าการมีข้อมูลที่ไม่มีฉลากที่คลุมเครือและการเพิ่มข้อมูลเพิ่มเติมเป็นกุญแจสู่ความสำเร็จของปัญหานี้
โมเดล Performacne ไม่ดีเท่าที่ฉันต้องการ แต่ฉันหวังว่าบทเรียนที่ฉันเรียนรู้จากโครงการนี้จะมีประโยชน์สำหรับคนที่ต้องการแก้ไขปัญหาที่คล้ายกันในอนาคต
โคลนพื้นที่เก็บข้อมูลไปยังคอมพิวเตอร์ของคุณและวางตำแหน่งบรรทัดคำสั่งของคุณภายในโฟลเดอร์ที่เก็บ:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
จากนั้นสร้างสภาพแวดล้อมเสมือนจริงชื่อ venv และติดตั้งแพ็คเกจที่จำเป็น:
make venv
make install-dev
เรียกใช้คำสั่งต่อไปนี้เพื่อดาวน์โหลดชุดข้อมูล IM2Latex-100k และทำการประมวลผลล่วงหน้าทั้งหมด (ขั้นตอนการปลูกถ่ายภาพอาจใช้เวลามากกว่าหนึ่งชั่วโมง)
python scripts/prepare_data.py
คำสั่งตัวอย่างเพื่อเริ่มเซสชันการฝึกอบรม:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
การกำหนดค่าสามารถแก้ไขได้ใน conf/config.yaml หรือในบรรทัดคำสั่ง ดูเอกสารของไฮดราเพื่อเรียนรู้เพิ่มเติม
จุดตรวจสอบรุ่นที่ดีที่สุดจะถูกอัปโหลดไปยังน้ำหนักและอคติ (W&B) โดยอัตโนมัติ (คุณจะถูกขอให้ลงทะเบียนหรือเข้าสู่ระบบ W & B ก่อนที่การฝึกอบรมจะเริ่ม) นี่คือคำสั่งตัวอย่างในการดาวน์โหลดจุดตรวจสอบโมเดลที่ผ่านการฝึกอบรมจาก W&B:
python scripts/download_checkpoint.py RUN_PATH
แทนที่ Run_Path ด้วยเส้นทางการวิ่งของคุณ เส้นทางการเรียกใช้ควรอยู่ในรูปแบบของ <entity>/<project>/<run_id> หากต้องการค้นหาเส้นทางการเรียกใช้สำหรับการทดลองโดยเฉพาะให้ไปที่แท็บภาพรวมในแดชบอร์ด
ตัวอย่างเช่นคุณสามารถใช้คำสั่งต่อไปนี้เพื่อดาวน์โหลดการเรียกใช้ที่ดีที่สุดของฉัน
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
จุดตรวจสอบจะถูกดาวน์โหลดไปยังโฟลเดอร์ชื่อ artifacts ภายใต้ไดเรกทอรีโครงการ
เครื่องมือต่อไปนี้ใช้ในการผ้าสำลี Codebase:
isort : เรียงลำดับและรูปแบบคำสั่งนำเข้าในสคริปต์ Python
black : รูปแบบรหัสที่ยึดติดกับ PEP8
flake8 : โค้ด linter ที่รายงานปัญหาโวหารในสคริปต์ Python
mypy : ทำการตรวจสอบประเภทคงที่ในสคริปต์ Python
ใช้คำสั่งต่อไปนี้เพื่อเรียกใช้ตัวตรวจสอบและฟอร์แมตทั้งหมด:
make lint
ดู pyproject.toml และ setup.cfg ที่ไดเรกทอรีรูทสำหรับการกำหนดค่า
การตรวจสอบที่คล้ายกันนั้นจะทำโดยอัตโนมัติโดยเฟรมเวิร์กล่วงหน้าเมื่อมีการกระทำ ลองดู .pre-commit-config.yaml สำหรับการกำหนดค่า
API ถูกสร้างขึ้นเพื่อทำการคาดการณ์โดยใช้แบบจำลองที่ผ่านการฝึกอบรม ใช้คำสั่งต่อไปนี้เพื่อให้เซิร์ฟเวอร์ขึ้นและทำงาน:
make api
คุณสามารถสำรวจ API ผ่านเอกสารที่สร้างขึ้นได้ที่ http://0.0.0.0:8000/docs
ในการเรียกใช้แอพ streamlit ให้สร้างหน้าต่างเทอร์มินัลใหม่และใช้คำสั่งต่อไปนี้:
make streamlit
ควรเปิดแอพในเบราว์เซอร์ของคุณโดยอัตโนมัติ คุณสามารถเปิดได้โดยไปที่ http: // localhost: 8501 สำหรับแอพในการทำงานคุณต้องดาวน์โหลดสิ่งประดิษฐ์ของการทดลอง (ดูด้านบน) และให้ API ทำงานได้
เพื่อสร้างภาพนักเทียบท่าสำหรับ API:
make docker
โครงการนี้ได้รับแรงบันดาลใจจากส่วนแนวคิดโครงการในแนวทางโครงการขั้นสุดท้ายของหลักสูตรการเรียนรู้อย่างลึกซึ้งเต็มรูปแบบที่ UC Berkely รหัสบางส่วนถูกนำมาใช้จากห้องปฏิบัติการ
MLOPS - ทำด้วย ML สำหรับการแนะนำ makefile, pre -commit, การกระทำของ GitHub และบรรจุภัณฑ์ Python
HarvardNLP/IM2Markup สำหรับชุดข้อมูล IM2Latex-100K


