image to latex
1.0.0
Приложение, которое отображает изображение математического уравнения латекса в код латексного кода.
Проблема генерации изображения к знаку была предпринята Deng et al. (2016). Они извлекли около 100 тыс. Формул, анализируя латексные источники документов из Arxiv. Они отображали формулы с использованием pdflatex и преобразовали рендерированные файлы PDF в формат PNG. Необработанные и предварительно обработанные версии их набора данных доступны в Интернете. В своей модели CNN сначала используется для извлечения функций изображения. Ряды функций затем кодируются с использованием RNN. Наконец, кодированные особенности используются декодером RNN с механизмом внимания. Модель имеет в общей сложности 9,48 миллиона параметров. Недавно Transformer обогнал RNN для многих языковых задач, поэтому я подумал, что могу попробовать эту проблему.
Используя их набор данных, я обучил модель, которая использует Resnet-18 в качестве кодера с 2D позиционным кодированием и трансформатором в качестве декодера с потерей поперечной энтропии. (Аналогично тому, что описано в Singh et al. (2021), за исключением того, что я использовал Resnet только до блокировки 3, чтобы снизить вычислительные затраты, и я исключил кодирование номера строки, поскольку это не относится к этой проблеме.) Модель имеет около 3 миллионов параметров.
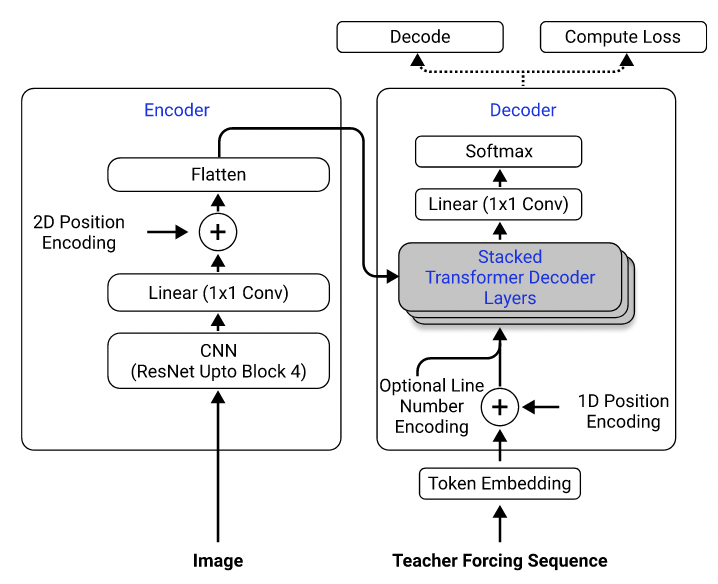
Модель архитектура. Взят из Singh et al. (2021).
Первоначально я использовал предварительный набор данных для обучения своей модели, потому что предварительно обработанные изображения понижаются до половины их первоначальных размеров для эффективности, сгруппированы и подполняются в аналогичные размеры, чтобы облегчить партии. Тем не менее, эта жесткая предварительная обработка оказалась огромным ограничением. Хотя модель может достичь разумной производительности в тестовом наборе (который был предварительно обработан так же, как и учебный набор), она не очень хорошо обобщала изображения вне набора данных, скорее всего, потому что качество изображения, прокладки и размер шрифта настолько отличаются от изображений в наборе данных. Это явление также наблюдалось другими, которые пытались выполнить ту же проблему, используя тот же набор данных (например, этот проект, этот вопрос и этот вопрос).
С этой целью я использовал необработанный набор данных и включил увеличение изображений (например, случайное масштабирование, гауссовый шум) в мой трубопровод обработки данных, чтобы увеличить разнообразие образцов. Более того, в отличие от Deng et al. (2016), я не группировал изображения по размеру. Скорее, я пробовал их равномерно и подбил их к размеру самого большого изображения в партии, так что модель должна научиться адаптироваться к различным размерам прокладки.
Дополнительные проблемы, с которыми я столкнулся в наборе данных:
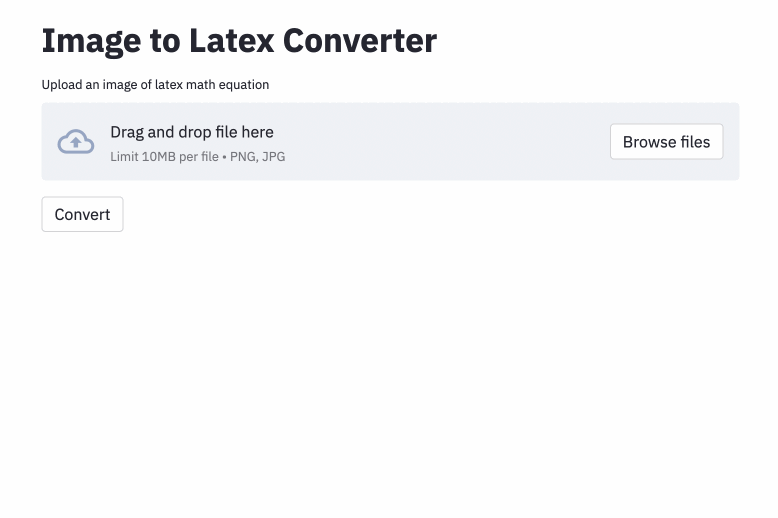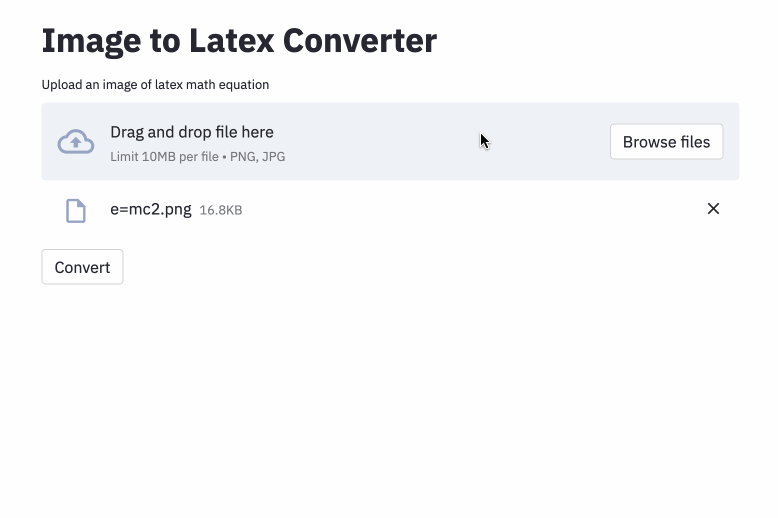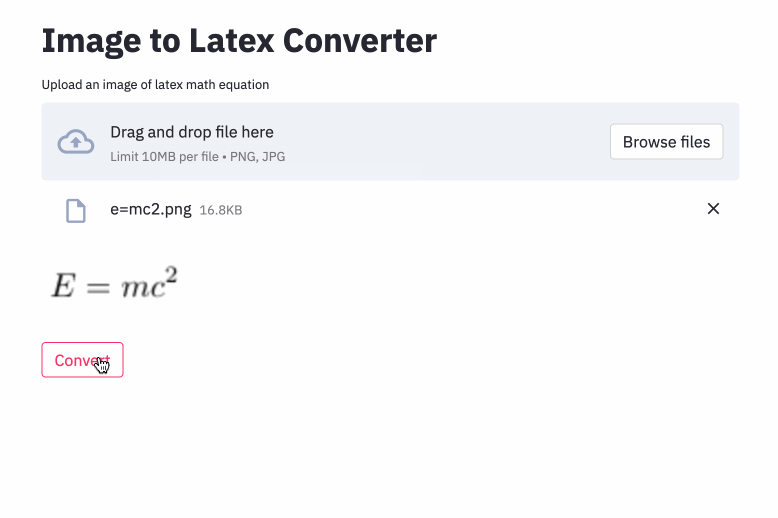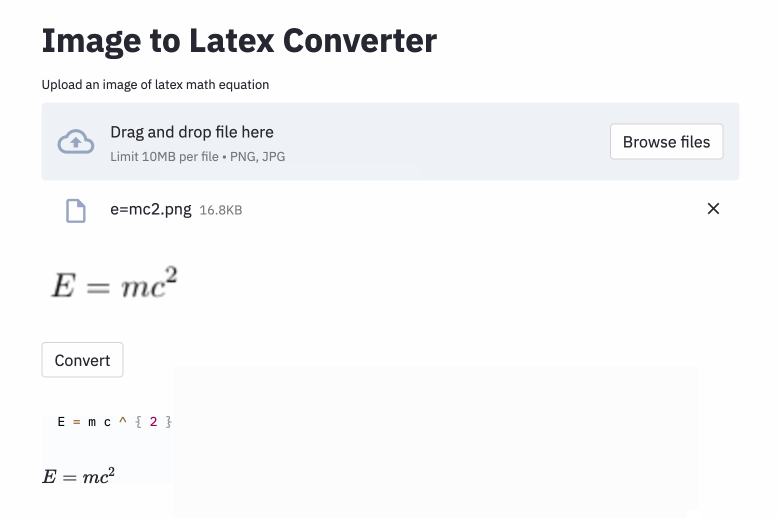
left( и right) выглядит так же, как ( и ) ), поэтому я их нормализовал.vspace{2px} и hspace{0.3mm} ). Тем не менее, длина пространства трудно судить даже для людей. Кроме того, есть много способов выразить то же расстояние (например, 1 см = 10 мм). Наконец, я не хочу, чтобы модель генерировала код на пустых изображениях, поэтому я их удалил. (Я удалил только vspace и hspace , но оказывается, что есть много команд для горизонтального расстояния. Я только понял, что во время анализа ошибок. См. Ниже.) Лучший прогон имеет частоту ошибок символа (CER) 0,17 в испытательном наборе. Вот пример из тестового набора данных:
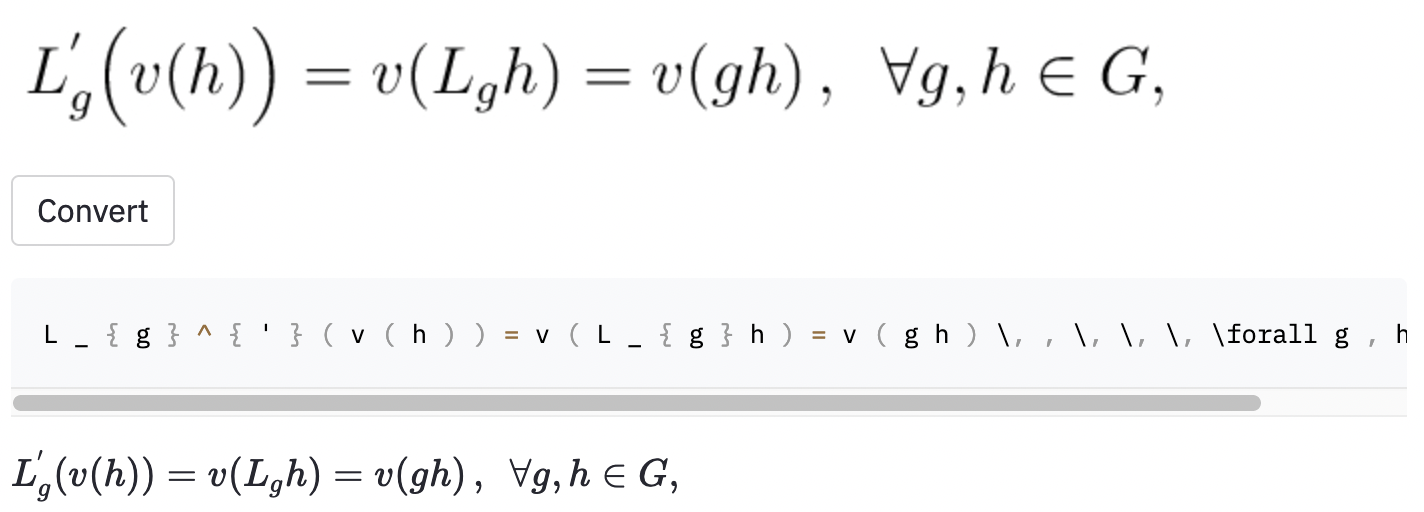
~ , тогда как модель использовалась , так что это все еще считалось ошибкой.Я также сделал несколько скриншотов в некоторых случайных статьях Википедии, чтобы увидеть, обобщает ли модель на изображения за пределами набора данных:

cal . 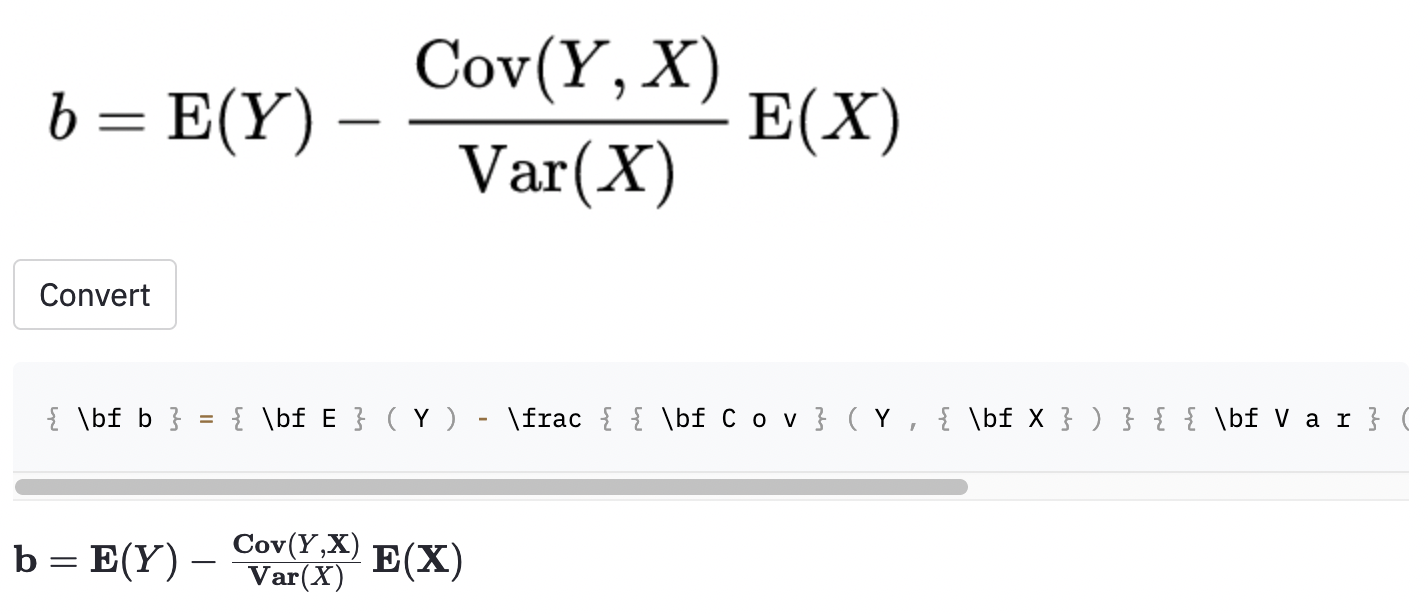
Модель также, кажется, испытывает некоторые проблемы, когда изображение больше, чем то, что в наборе данных. Возможно, я должен был увеличить диапазон изменения фактора в процессе увеличения данных.
Я думаю, что я должен был лучше определить масштаб проекта:
( , big( , Big( , bigg( , Bigg( )?Эти вопросы должны использоваться для руководства процессом очистки данных.
Я нашел довольно созданный инструмент под названием Mathpix Snip, который преобразует рукописные формулы в латексный код. Его размер словарного запаса составляет около 200. За исключением чисел и английских букв, количество команд латекса, которую он может создать, на самом деле чуть выше 100. (Размер словарного запаса im2latex-100K почти 500). Он включает только две горизонтальные команды интервалов ( quad и qquad ), и не распознает разные размеры скобок. Я должен был сделать Perphas, ограниченный ограниченным набором словарного запаса, поскольку в реальном латексе так много неясностей.
Очевидные возможные улучшения этой работы включают (1) обучение модели для большего количества эпох (ради времени, я только обучил модель только для 15 эпох, но потери проверки все еще снижаются), (2) использование поиска луча (я реализовал только жадный поиск), (3) с использованием более крупной модели (например, использование Resnet-34, вместо Resnet-18 и выполнение некоторого гипер-настройки. Я не делал ничего из этого, потому что у меня были ограниченные вычислительные ресурсы (я использовал Google Colab). Но в конечном счете, я считаю, что наличие данных, которые не имеют двусмысленных меток, и увеличение количества данных - это ключ к успеху этой проблемы.
Модель Performacne не так хороша, как я хочу, но я надеюсь, что уроки, которые я извлек из этого проекта, полезны для тех, кто хочет решить подобные проблемы в будущем.
Клонировать репозиторий к вашему компьютеру и поместите свою командную строку в папке репозитория:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
Затем создайте виртуальную среду с именем venv и установите необходимые пакеты:
make venv
make install-dev
Запустите следующую команду, чтобы загрузить набор данных im2latex-100K и выполнить всю предварительную обработку. (Шаг обрезки изображения может занять более часа.)
python scripts/prepare_data.py
Пример команды для начала тренировочной сессии:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
Конфигурации могут быть изменены в conf/config.yaml или в командной строке. Смотрите документацию Hydra, чтобы узнать больше.
Лучшая контрольная точка модели будет загружена в Weights & Biases (W & B) автоматически (вам будет предложено зарегистрировать или войти в W & B до начала обучения). Вот пример команды для загрузки обученной контрольной точки модели с W & B:
python scripts/download_checkpoint.py RUN_PATH
Замените run_path на пути вашего бега. Путь прогона должен быть в формате <entity>/<project>/<run_id> . Чтобы найти путь запуска для конкретного запуска эксперимента, перейдите на вкладку «Обзор» на приборной панели.
Например, вы можете использовать следующую команду для загрузки моего лучшего запуска
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
Контрольная точка будет загружена в папку с именем artifacts в рамках каталога проекта.
Следующие инструменты используются для оборки кодовой базы:
isort : сортировки и форматы импортируют заявления в сценариях Python.
black : форматер кода, который придерживается PEP8.
flake8 : кодовый линтер, который сообщает о стилистических проблемах в сценариях Python.
mypy : выполняет проверку статического типа в сценариях Python.
Используйте следующую команду, чтобы запустить все шашки и форматер:
make lint
См. pyproject.toml и setup.cfg в корневом каталоге для их конфигураций.
Аналогичные проверки проводятся автоматически в рамках предварительной связи, когда сделан коммит. Проверьте .pre-commit-config.yaml для конфигураций.
API создается для прогноза с использованием обученной модели. Используйте следующую команду, чтобы запустить сервер:
make api
Вы можете исследовать API через сгенерированную документацию по адресу http://0.0.0.0:8000/docs.
Чтобы запустить приложение Streamlit, создайте новое окно терминала и используйте следующую команду:
make streamlit
Приложение должно быть автоматически открыто в вашем браузере. Вы также можете открыть его, посетив http: // localhost: 8501. Чтобы приложение работало, вам нужно загрузить артефакты экспериментального запуска (см. Выше) и использовать API.
Чтобы создать изображение Docker для API:
make docker
Этот проект вдохновлен разделом «Идеи проекта» в окончательных руководящих принципах проекта полного курса полного обучения в UC Berkely. Некоторые из кода приняты из его лабораторий.
MLOPS - Сделано с ML для введения Makefile, Pre -Commit, GitHub Actions и Python Packaging.
Harvardnlp/im2markup для набора данных im2latex-100K.


