image to latex
1.0.0
تطبيق يرسم صورة لمعادلة الرياضيات اللاتكس إلى رمز اللاتكس.
حاول Deng et al مشكلة توليد صورة إلى Markup من قبل Deng et al. (2016). استخرجوا حوالي 100 ألف صيغ عن طريق تحليل مصادر اللاتكس من الأوراق من Arxiv. قاموا بتقديم الصيغ باستخدام pdflatex وتحويل ملفات PDF المقدمة إلى تنسيق PNG. تتوفر الإصدارات الخام والمجددة مسبقًا من مجموعة البيانات الخاصة بهم عبر الإنترنت. في نموذجهم ، يتم استخدام CNN أولاً لاستخراج ميزات الصورة. ثم يتم ترميز صفوف الميزات باستخدام RNN. أخيرًا ، يتم استخدام الميزات المشفرة بواسطة وحدة فك ترميز RNN مع آلية الانتباه. يحتوي النموذج على 9.48 مليون معلمة في المجموع. في الآونة الأخيرة ، تجاوز Transformer RNN للعديد من مهام اللغة ، لذلك اعتقدت أنني قد أجربها في هذه المشكلة.
باستخدام مجموعة البيانات الخاصة بهم ، قمت بتدريب نموذج يستخدم Resnet-18 كمشفر مع تشفير الموضعية ثنائية الأبعاد ومحول كدلالة مع فقدان الإدخال المتقاطع. (على غرار تلك الموصوفة في سينغ وآخرون (2021) ، باستثناء أنني استخدمت RESNET فقط لأعلى للحظر 3 لتقليل التكاليف الحسابية ، واستبعدت رقم الخط الترميز لأنه لا ينطبق على هذه المشكلة.) يحتوي النموذج على حوالي 3 ملايين معلمة.
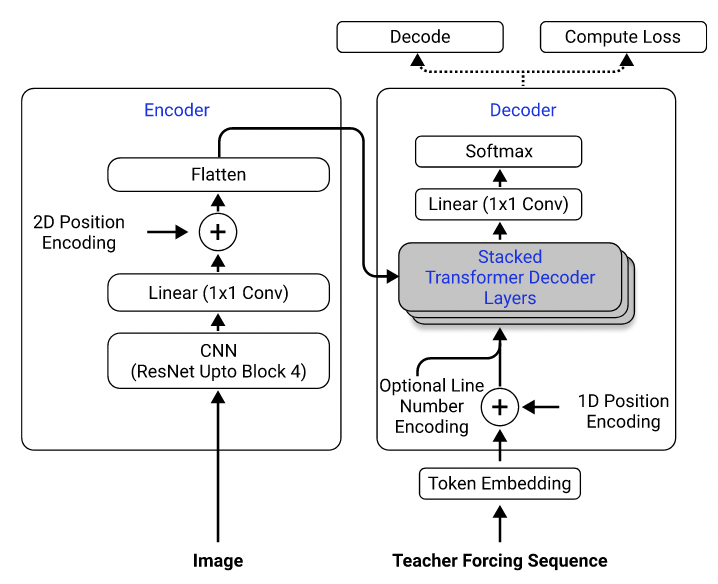
النموذج العمارة. مأخوذة من سينغ وآخرون. (2021).
في البداية ، استخدمت مجموعة البيانات المعالجة مسبقًا لتدريب النموذج الخاص بي ، لأن الصور التي تم تجهيزها مسبقًا تم تخطيها إلى نصف أحجامها الأصلية للكفاءة ، ويتم تجميعها ومبتك عليها في أحجام مماثلة لتسهيل التضليل. ومع ذلك ، تحولت هذه المعالجة المسبقة الصارمة إلى قيود كبيرة. على الرغم من أن النموذج يمكن أن يحقق أداءً معقولًا على مجموعة الاختبار (التي تمت معالجتها مسبقًا بنفس طريقة مجموعة التدريب) ، إلا أنه لم يتم تعميمه جيدًا على الصور خارج مجموعة البيانات ، على الأرجح لأن جودة الصورة والحشو وحجم الخط تختلف تمامًا عن الصور في مجموعة البيانات. وقد لوحظ أيضًا هذه الظاهرة من قبل الآخرين الذين حاولوا نفس المشكلة باستخدام نفس مجموعة البيانات (على سبيل المثال ، هذا المشروع ، هذه المشكلة وهذه المشكلة).
تحقيقًا لهذه الغاية ، استخدمت مجموعة البيانات الأولية وشملت تكبير الصور (مثل التحجيم العشوائي ، والضوضاء الغوسية) في خط أنابيب معالجة البيانات الخاص بي لزيادة تنوع العينات. علاوة على ذلك ، على عكس Deng et al. (2016) ، لم أجمع الصور حسب الحجم. بدلاً من ذلك ، قمت بأخذ عينات منها بشكل موحد وبطبتها بحجم أكبر صورة في الدفعة ، بحيث يجب أن يتعلم النموذج كيفية التكيف مع أحجام الحشوة المختلفة.
مشاكل إضافية واجهتها في مجموعة البيانات:
left( و right) تبدو كما هي ( و ) ) ، لذلك قمت بتطبيعها.vspace{2px} و hspace{0.3mm} ). ومع ذلك ، فإن طول المساحة هو الصعود للحكم حتى بالنسبة للبشر. أيضا ، هناك العديد من الطرق للتعبير عن نفس التباعد (على سبيل المثال 1 سم = 10 مم). أخيرًا ، لا أريد أن يقوم النموذج بإنشاء رمز على صور فارغة ، لذلك قمت بإزالتها. (لقد قمت فقط بإزالة vspace و hspace ، ولكن اتضح أن هناك الكثير من الأوامر للتباعد الأفقي. أدركت فقط أنه أثناء تحليل الخطأ. انظر أدناه.) يحتوي أفضل تشغيل على معدل خطأ في الأحرف (CER) من 0.17 في مجموعة الاختبار. فيما يلي مثال من مجموعة بيانات الاختبار:
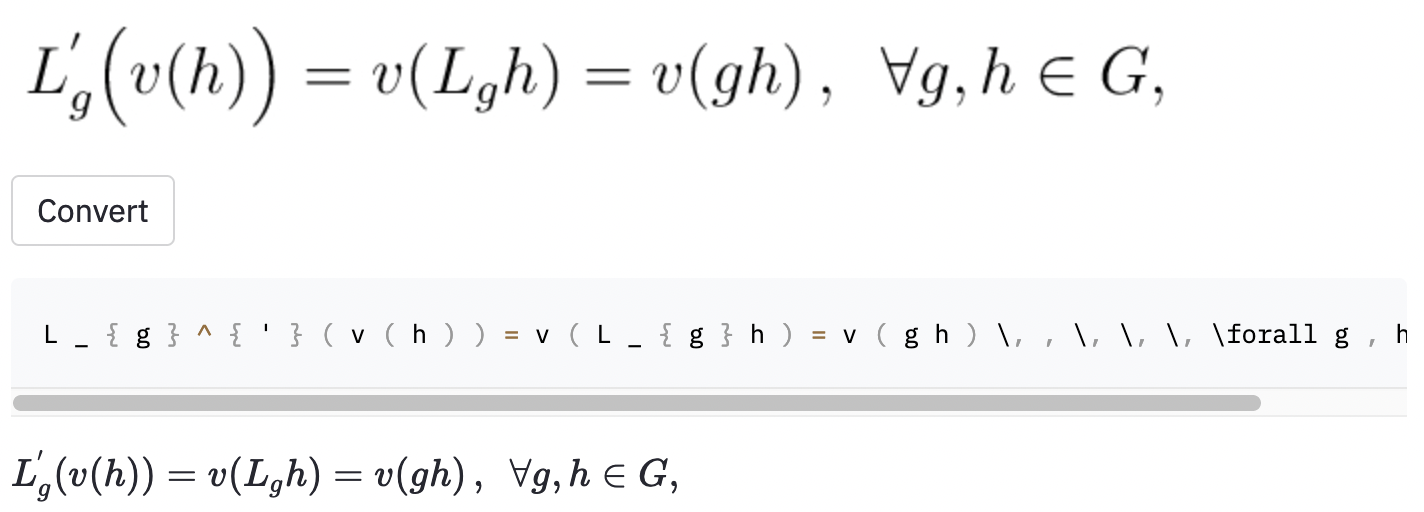
~ ، في حين أن النموذج المستخدم , لذلك كان لا يزال يتم حسابه كخطأ.لقد أخذت أيضًا بعض لقطات الشاشة في بعض مقالات ويكيبيديا العشوائية لمعرفة ما إذا كان النموذج يعتمد على الصور خارج مجموعة البيانات:

cal . 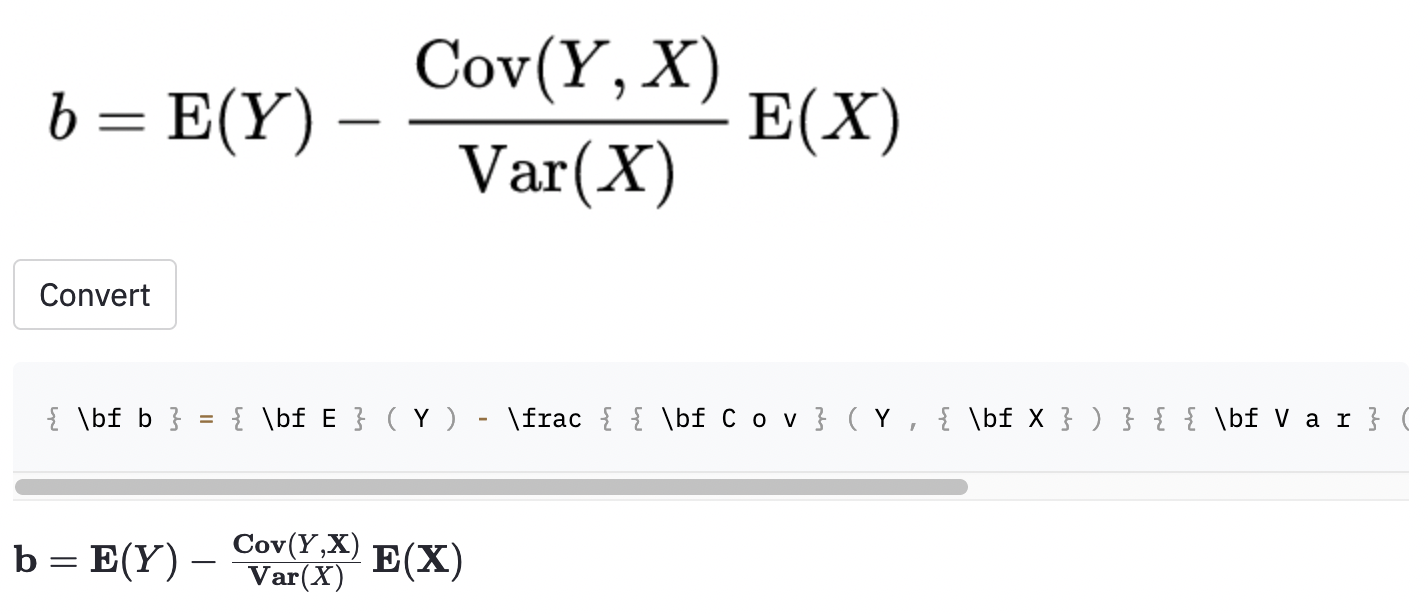
يبدو أن النموذج يعاني أيضًا من بعض المتاعب عندما تكون الصورة أكبر من ما في مجموعة البيانات. ربما كان ينبغي علي زيادة نطاق عامل إعادة القياس في عملية تكبير البيانات.
أعتقد أنه كان ينبغي علي تحديد نطاق المشروع بشكل أفضل:
( ، big( ، Big( ، bigg( ، Bigg( )؟يجب استخدام هذه الأسئلة لتوجيه عملية تنظيف البيانات.
لقد وجدت أداة راسخة تسمى Mathpix Snip التي تحول الصيغ المكتوبة بخط اليد إلى رمز اللاتكس. يبلغ حجم المفردات حوالي 200. باستثناء الأرقام والرسائل الإنجليزية ، فإن عدد أوامر اللاتكس التي يمكن أن تنتجها هو في الواقع أعلى بقليل من 100. (حجم المفردات لـ IM2Latex-100K هو ما يقرب من 500). ويشمل فقط اثنين من أوامر التباعد الأفقي ( quad و qquad ) ، ولا يتعرف على أحجام مختلفة من الأقواس. Perphas يقتصر على مجموعة محدودة من المفردات هو ما كان ينبغي علي فعله ، لأن هناك الكثير من الغموض في اللاتكس في العالم الحقيقي.
تشمل التحسينات المحتملة الواضحة لهذا العمل (1) تدريب النموذج لمزيد من الحقبة (من أجل الوقت ، قمت بتدريب النموذج فقط على 15 عصرًا ، لكن فقدان التحقق من الصحة لا يزال ينخفض) ، (2) باستخدام بحث الشعاع (قمت فقط بالبحث الجشع) ، (3) باستخدام نموذج أكبر (على سبيل المثال ، استخدم Resnet-34 بدلاً من resnet-18). لم أفعل أيًا من هذه الأشياء ، لأنني حصلت على موارد حسابية محدودة (كنت أستخدم Google Colab). لكن في النهاية ، أعتقد أن وجود بيانات ليس لديها ملصقات غامضة والقيام بمزيد من زيادة البيانات هي مفاتيح نجاح هذه المشكلة.
لا يعد Model PerformAcne جيدًا كما أريد ، لكنني آمل أن تكون الدروس التي تعلمتها من هذا المشروع مفيدة لشخص ما يريد معالجة مشاكل مماثلة في المستقبل.
استنساخ المستودع لجهاز الكمبيوتر الخاص بك ووضع سطر الأوامر الخاص بك داخل مجلد المستودع:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
ثم ، قم بإنشاء بيئة افتراضية تسمى venv وتثبيت الحزم المطلوبة:
make venv
make install-dev
قم بتشغيل الأمر التالي لتنزيل مجموعة بيانات IM2Latex-100K وقم بكل المعالجة المسبقة. (قد تستغرق خطوة زراعة الصورة أكثر من ساعة.)
python scripts/prepare_data.py
مثال على الأمر لبدء جلسة تدريبية:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
يمكن تعديل التكوينات في conf/config.yaml أو في سطر الأوامر. انظر وثائق Hydra لمعرفة المزيد.
سيتم تحميل أفضل نقطة تفتيش نموذج إلى الأوزان والتحيزات (W&B) تلقائيًا (سيُطلب منك التسجيل أو تسجيل الدخول إلى W&B قبل بدء التدريب). فيما يلي أمر مثال لتنزيل نقطة تفتيش طراز مدرب من W & B:
python scripts/download_checkpoint.py RUN_PATH
استبدل run_path بمسار تشغيلك. يجب أن يكون مسار التشغيل بتنسيق <entity>/<project>/<run_id> . للعثور على مسار التشغيل لتشغيل تجربة معينة ، انتقل إلى علامة التبويب نظرة عامة في لوحة القيادة.
على سبيل المثال ، يمكنك استخدام الأمر التالي لتنزيل أفضل تشغيل
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
سيتم تنزيل نقطة التفتيش إلى مجلد يسمى artifacts ضمن دليل المشروع.
تُستخدم الأدوات التالية لتربط قاعدة الشفرة:
isort : فرز وتنسيقات عبارات استيراد في برامج نصية بيثون.
black : رمز ينسيق يلتزم بـ PEP8.
flake8 : رمز linter الذي يبلغ عن مشاكل الأسلوب في البرامج النصية Python.
mypy : يقوم بالتحقق من النوع الثابت في البرامج النصية للثعبان.
استخدم الأمر التالي لتشغيل جميع الداما والتنسيق:
make lint
انظر pyproject.toml و setup.cfg في دليل الجذر لتكويناتها.
يتم إجراء فحوصات مماثلة تلقائيًا عن طريق إطار عمل ما قبل الالتزام عند التزام. تحقق من .pre-commit-config.yaml للتكوينات.
يتم إنشاء واجهة برمجة تطبيقات لجعل التنبؤات باستخدام النموذج المدرب. استخدم الأمر التالي للحصول على الخادم وتشغيله:
make api
يمكنك استكشاف API عبر الوثائق التي تم إنشاؤها على http://0.0.0.0:8000/docs.
لتشغيل تطبيق SPEREMLIT ، قم بإنشاء نافذة طرفية جديدة واستخدم الأمر التالي:
make streamlit
يجب فتح التطبيق في متصفحك تلقائيًا. يمكنك أيضًا فتحه عن طريق زيارة http: // localhost: 8501. لكي يعمل التطبيق ، تحتاج إلى تنزيل القطع الأثرية لتجربة التجربة (انظر أعلاه) وتشغيل واجهة برمجة التطبيقات.
لإنشاء صورة Docker لواجهة برمجة التطبيقات:
make docker
هذا المشروع مستوحى من قسم أفكار المشروع في إرشادات المشروع النهائي للدورة التدريبية الكاملة التعلم العميق في جامعة كاليفورنيا في بيركلي. تم اعتماد بعض الكود من مختبراتها.
MLOPS - مصنوعة من ML لتقديم تصرفات Makefile و Pre -Commit و Github وتعبئة Python.
HarvardNLP/IM2Markup لمجموعة بيانات IM2Latex-100K.


