image to latex
1.0.0
Une application qui mappe une image d'une équation mathématique en latex au code de latex.
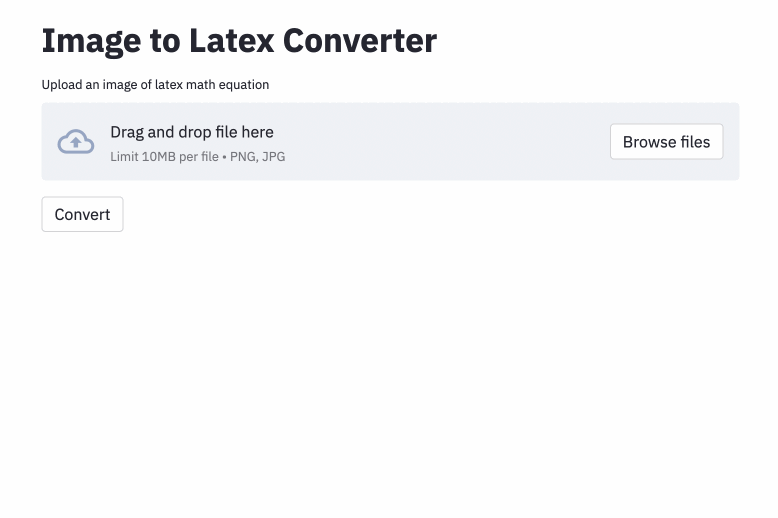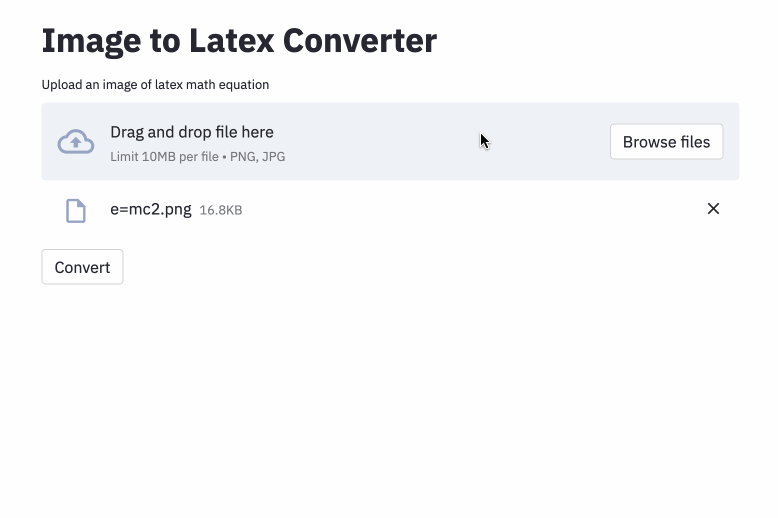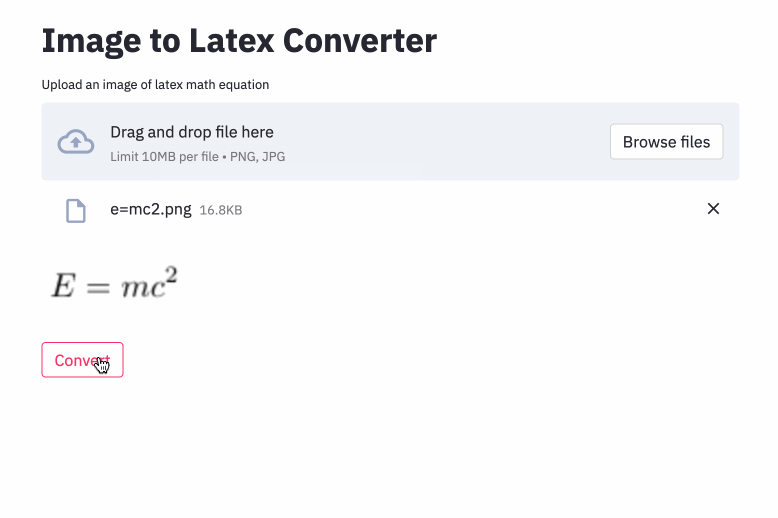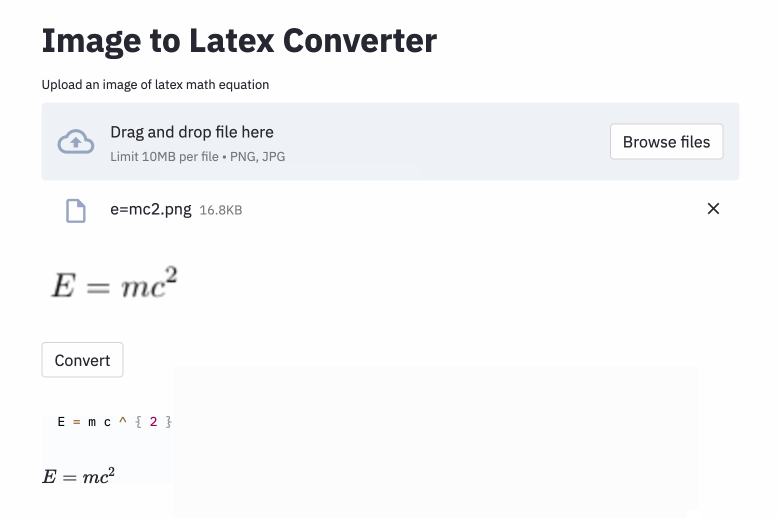
Le problème de la génération d'image à markup a été tenté par Deng et al. (2016). Ils ont extrait environ 100 000 formules en analysant les sources de latex de papiers de l'ARXIV. Ils ont rendu les formules à l'aide de PDFlatex et ont converti les fichiers PDF rendus au format PNG. Les versions brutes et prétraitées de leur ensemble de données sont disponibles en ligne. Dans leur modèle, un CNN est d'abord utilisé pour extraire les caractéristiques de l'image. Les lignes des fonctionnalités sont ensuite codées à l'aide d'un RNN. Enfin, les caractéristiques codées sont utilisées par un décodeur RNN avec un mécanisme d'attention. Le modèle a 9,48 millions de paramètres au total. Récemment, Transformer a dépassé le RNN pour de nombreuses tâches linguistiques, donc j'ai pensé que je pourrais l'essayer dans ce problème.
À l'aide de leur ensemble de données, j'ai formé un modèle qui utilise RESNET-18 comme encodeur avec codage de position 2D et un transformateur comme décodeur avec une perte d'entrée croisée. (Semblable à celui décrit dans Singh et al. (2021), sauf que j'ai utilisé Resnet uniquement jusqu'au bloc 3 pour réduire les coûts de calcul, et j'ai exclu le codage du numéro de ligne car il ne s'applique pas à ce problème.) Le modèle a environ 3 millions de paramètres.
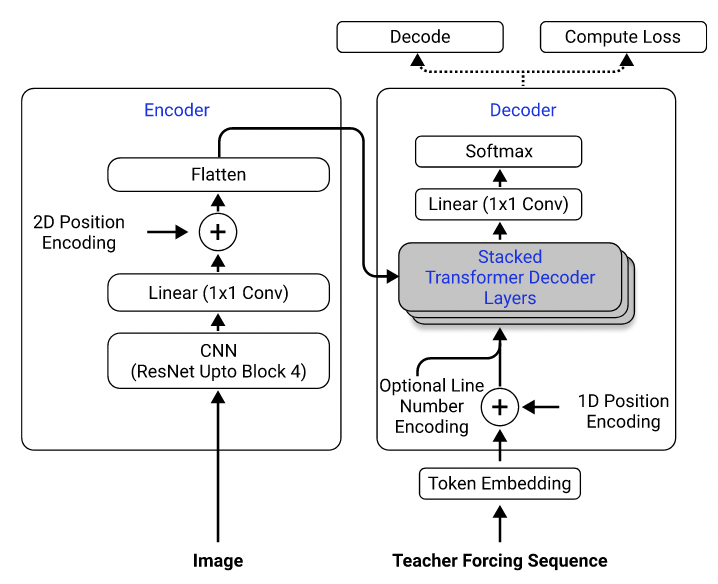
Architecture modèle. Pris de Singh et al. (2021).
Initialement, j'ai utilisé l'ensemble de données prétraité pour former mon modèle, car les images prétraitées sont réduites à la moitié de leurs tailles d'origine pour l'efficacité, et sont regroupées et rembourrées dans des tailles similaires pour faciliter le lot. Cependant, ce prétraitement rigide s'est avéré être une énorme limitation. Bien que le modèle puisse atteindre une performance raisonnable sur l'ensemble de tests (qui a été prétraité de la même manière que l'ensemble de formation), il n'a pas bien généralisé aux images en dehors de l'ensemble de données, très probablement parce que la qualité d'image, le rembourrage et la taille des polices sont si différents des images de l'ensemble de données. Ce phénomène a également été observé par d'autres qui ont tenté le même problème en utilisant le même ensemble de données (par exemple, ce projet, ce problème et ce problème).
À cette fin, j'ai utilisé l'ensemble de données brut et inclus l'augmentation de l'image (par exemple, l'échelle aléatoire, le bruit gaussien) dans mon pipeline de traitement des données pour augmenter la diversité des échantillons. De plus, contrairement à Deng et al. (2016), je n'ai pas regroupé d'images par taille. Au contraire, je les ai échantillonnés uniformément et les ai rembourrés à la taille de la plus grande image du lot, afin que le modèle doit apprendre à s'adapter à différentes tailles de rembourrage.
Problèmes supplémentaires auxquels j'ai été confronté dans l'ensemble de données:
left( et right) la même chose que ( et ) ), donc je les ai normalisées.vspace{2px} et hspace{0.3mm} ). Cependant, la longueur de l'espace est difficile à juger même pour les humains. De plus, il existe de nombreuses façons d'exprimer le même espacement (par exemple 1 cm = 10 mm). Enfin, je ne veux pas que le modèle génére du code sur des images vierges, donc je les ai supprimées. (Je n'ai supprimé vspace et hspace , mais il s'avère qu'il y a beaucoup de commandes pour l'espacement horizontal. Je n'ai réalisé que pendant l'analyse des erreurs. Voir ci-dessous.) La meilleure exécution a un taux d'erreur de caractère (CER) de 0,17 en jeu de test. Voici un exemple de l'ensemble de données de test:
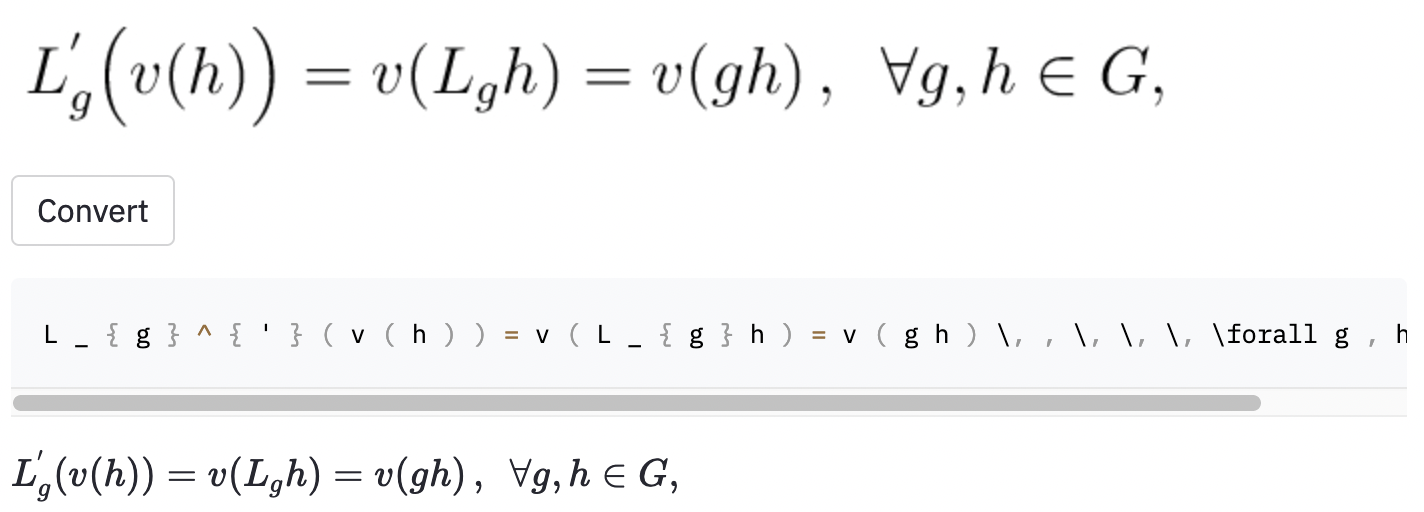
~ , tandis que le modèle utilisé , donc cela a toujours été compté comme une erreur.J'ai également pris quelques captures d'écran dans certains articles aléatoires Wikipedia pour voir si le modèle se généralise aux images en dehors de l'ensemble de données:

cal . 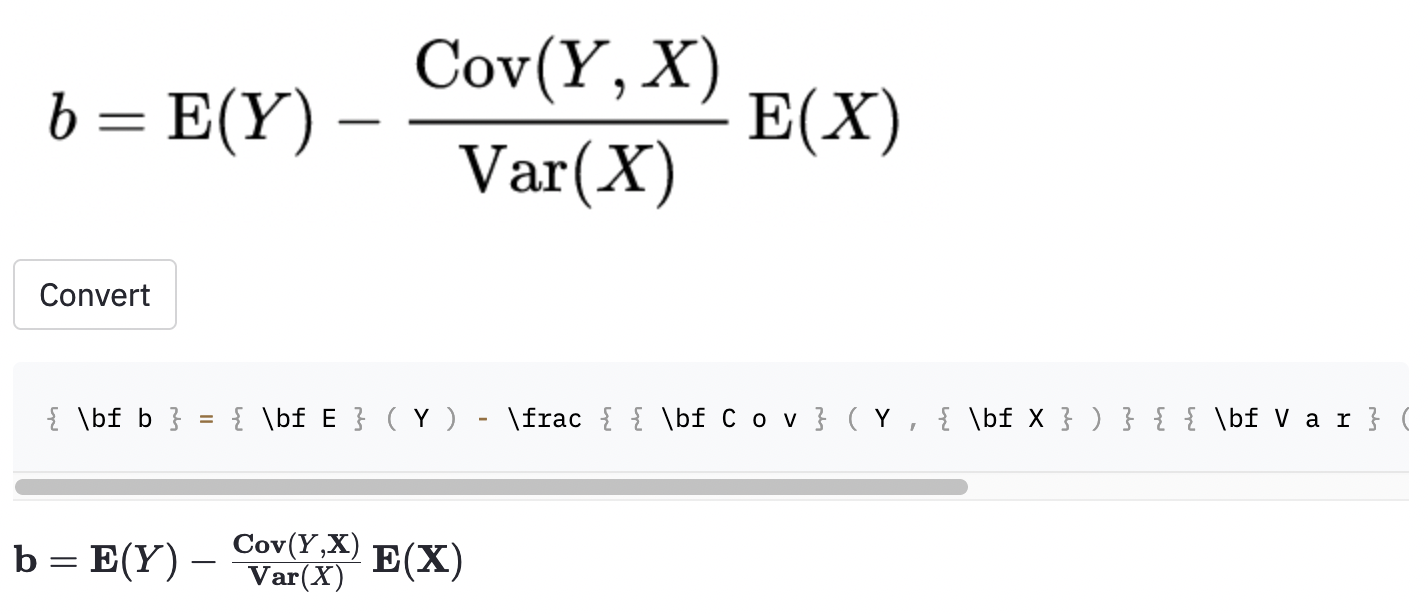
Le modèle semble également avoir des problèmes lorsque l'image est plus grande que celles de l'ensemble de données. J'aurais peut-être dû augmenter la gamme de facteurs de rediffusion dans le processus d'augmentation des données.
Je pense que j'aurais dû mieux définir la portée du projet:
( , big( , Big( , bigg( , Bigg( )?Ces questions doivent être utilisées pour guider le processus de nettoyage des données.
J'ai trouvé un outil assez établi appelé MathPix Snip qui convertit les formules manuscrites en code de latex. Sa taille de vocabulaire est d'environ 200. En excluant les nombres et les lettres anglaises, le nombre de commandes de latex qu'il peut produire est en fait juste au-dessus de 100. (La taille du vocabulaire de IM2LATEX-100K est de près de 500). Il ne comprend que deux commandes d'espacement horizontal ( quad et qquad ), et il ne reconnaît pas différentes tailles de parenthèses. Les perphas se limitent à un ensemble limité de vocabulaire est ce que j'aurais dû faire, car il y a tellement d'ambiguïtés dans le latex réel.
Des améliorations possibles possibles de ce travail incluent (1) la formation du modèle pour plus d'époches (pour le temps, je n'ai formé le modèle que pour 15 époques, mais la perte de validation baisse toujours), (2) en utilisant la recherche de faisceau (je n'ai implémenté que la recherche gourmand), (3) en utilisant un modèle plus grand (par exemple, Utilisez le Resnet-34 au lieu de Resnet-18) et en faisant du tunage hyperparamètre. Je n'ai fait aucun de ces éléments, car j'avais des ressources de calcul limitées (j'utilisais Google Colab). Mais en fin de compte, je crois que le fait d'avoir des données qui n'ont pas d'étiquettes ambiguës et de faire plus d'augmentation de données sont les clés du succès de ce problème.
Le modèle PerformAcne n'est pas aussi bon que je le souhaite, mais j'espère que les leçons que j'ai apprises de ce projet sont utiles à quelqu'un qui veut s'attaquer à des problèmes similaires à l'avenir.
Clone le référentiel sur votre ordinateur et positionnez votre ligne de commande dans le dossier du référentiel:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
Ensuite, créez un environnement virtuel nommé venv et installez les packages requis:
make venv
make install-dev
Exécutez la commande suivante pour télécharger le jeu de données IM2LateX-100K et faire tout le prétraitement. (L'étape de recadrage d'image peut prendre plus d'une heure.)
python scripts/prepare_data.py
Un exemple de commande pour démarrer une session de formation:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
Les configurations peuvent être modifiées dans conf/config.yaml ou en ligne de commande. Voir la documentation d'Hydra pour en savoir plus.
Le meilleur point de contrôle du modèle sera téléchargé sur les poids et les biais (W&B) automatiquement (il vous sera demandé de vous inscrire ou de vous connecter à W&B avant le début de la formation). Voici un exemple de commande pour télécharger un point de contrôle de modèle formé à partir de W&B:
python scripts/download_checkpoint.py RUN_PATH
Remplacez Run_path par le chemin de votre course. Le chemin d'exécution doit être dans le format de <entity>/<project>/<run_id> . Pour trouver le chemin d'exécution pour une expérience d'expérience particulière, accédez à l'onglet Présentation du tableau de bord.
Par exemple, vous pouvez utiliser la commande suivante pour télécharger ma meilleure course
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
Le point de contrôle sera téléchargé dans un dossier nommé artifacts dans le répertoire du projet.
Les outils suivants sont utilisés pour mettre au lit la base de code:
isort : Trie et formats Importer des instructions dans les scripts Python.
black : un formateur de code qui adhère à pep8.
flake8 : un linter de code qui rapporte des problèmes stylistiques dans les scripts Python.
mypy : effectue une vérification de type statique dans les scripts Python.
Utilisez la commande suivante pour exécuter tous les vérificateurs et formateurs:
make lint
Voir pyproject.toml et setup.cfg au répertoire racine pour leurs configurations.
Des vérifications similaires sont effectuées automatiquement par le cadre pré-engagement lorsqu'un engagement est effectué. Consultez .pre-commit-config.yaml pour les configurations.
Une API est créée pour faire des prédictions en utilisant le modèle formé. Utilisez la commande suivante pour faire fonctionner le serveur:
make api
Vous pouvez explorer l'API via la documentation générée à http://0.0.0.0:8000/docs.
Pour exécuter l'application Streamlit, créez une nouvelle fenêtre de terminal et utilisez la commande suivante:
make streamlit
L'application doit être ouverte automatiquement dans votre navigateur. Vous pouvez également l'ouvrir en visitant http: // localhost: 8501. Pour que l'application fonctionne, vous devez télécharger les artefacts d'une expérience d'expérience (voir ci-dessus) et avoir l'API en cours d'exécution.
Pour créer une image Docker pour l'API:
make docker
Ce projet est inspiré par la section des idées de projet dans les directives finales du projet du cours Full Stack Deep Learning à UC Berkely. Une partie du code est adoptée à partir de ses laboratoires.
MOLPS - Fabriqué avec ML pour introduire MakeFile, pré-Commit, GitHub Actions et Python Packaging.
Harvardnlp / im2markup pour l'ensemble de données IM2Latex-100K.


