image to latex
1.0.0
ラテックス数学方程式の画像をラテックスコードにマッピングするアプリケーション。
画像からマークアップの生成の問題は、Deng et al。によって試みられました。 (2016)。彼らは、Arxivからの論文のラテックス源を解析することにより、約100kの式を抽出しました。 PDFlatexを使用して式をレンダリングし、レンダリングされたPDFファイルをPNG形式に変換しました。データセットの生および前処理されたバージョンは、オンラインで入手できます。モデルでは、CNNは最初に画像機能を抽出するために使用されます。機能の行は、RNNを使用してエンコードされます。最後に、エンコードされた機能は、注意メカニズムを備えたRNNデコーダーによって使用されます。このモデルには、合計948万のパラメーターがあります。最近、Transformerは多くの言語タスクでRNNを追い越したので、この問題で試してみるかもしれないと思いました。
データセットを使用して、2D位置エンコーディングを備えたエンコーダーとしてResNet-18を使用し、エントロピー損失を伴うデコーダーとして変圧器を使用するモデルをトレーニングしました。 (Singh et al。(2021)に記載されているものと同様ですが、計算コストを削減するためにブロック3までのResNetを使用したことを除いて、この問題には適用されないためエンコードを除外しました。)モデルには約300万個のパラメーターがあります。
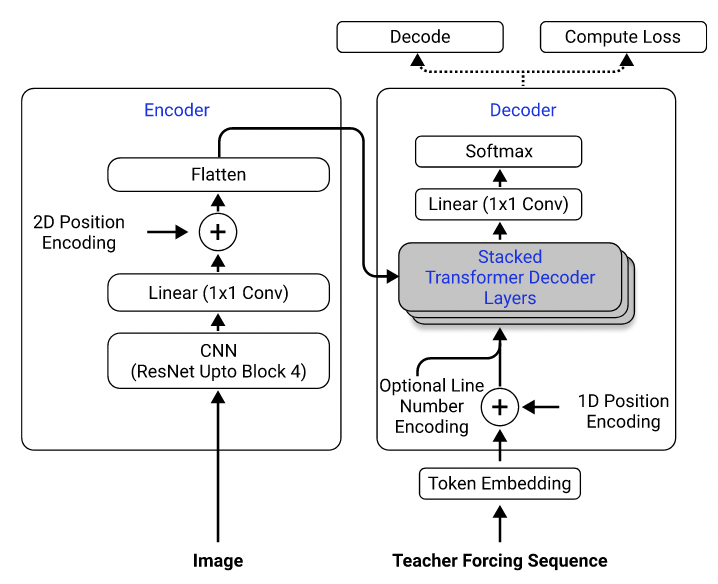
モデルアーキテクチャ。 Singh et alから取った。 (2021)。
最初は、前処理された画像が効率のために元のサイズの半分にダウンサンプリングされ、バッチを容易にするために同様のサイズにグループ化されパッドされているため、前処理されたデータセットを使用してモデルをトレーニングしました。しかし、この硬い前処理は大きな制限であることが判明しました。モデルは、テストセットで合理的なパフォーマンスを実現できますが(トレーニングセットと同じように前処理されました)、データセットの画像、パディング、フォントサイズがデータセットの画像とは大きく異なるため、データセットの外側の画像にはあまり一般化されませんでした。この現象は、同じデータセットを使用して同じ問題を試みた他の人によっても観察されています(たとえば、このプロジェクト、この問題、およびこの問題)。
この目的のために、私は生データセットを使用し、データ処理パイプラインに画像の増強(ランダムスケーリング、ガウスノイズなど)を含めて、サンプルの多様性を高めました。さらに、Deng et alとは異なり。 (2016)、私はサイズごとに画像をグループ化しませんでした。むしろ、私はそれらを均一にサンプリングし、それらをバッチ内の最大の画像のサイズにパッドでパッドしたため、モデルはさまざまなパディングサイズに適応する方法を学習する必要があります。
データセットで直面した追加の問題:
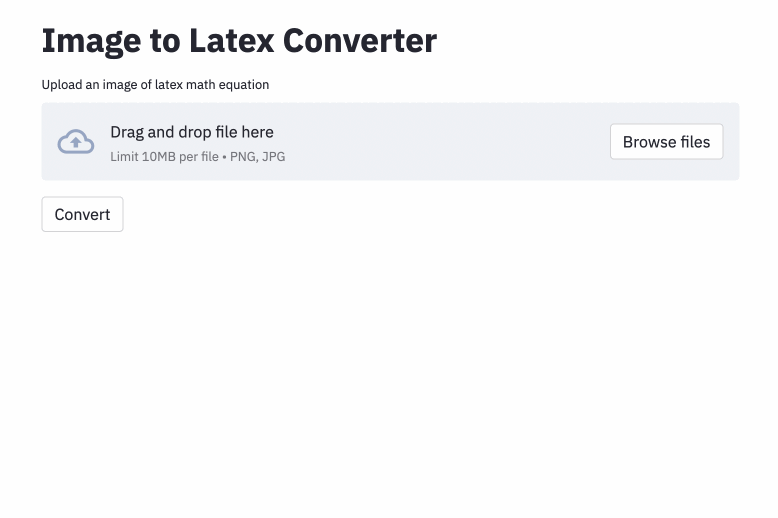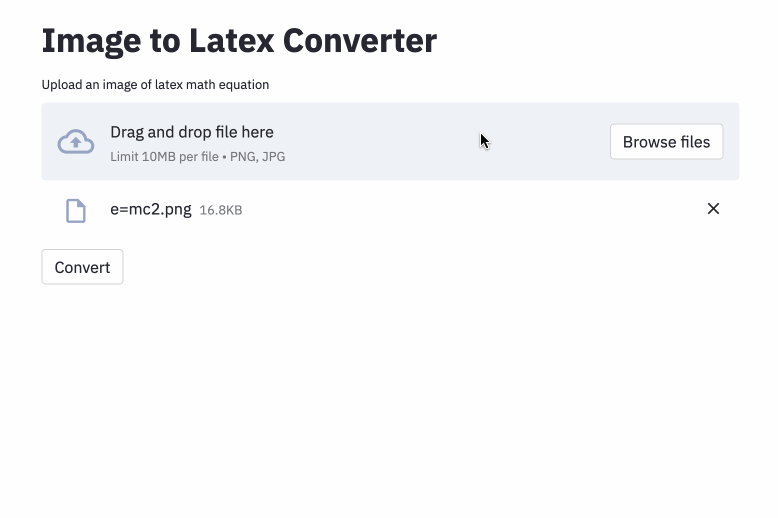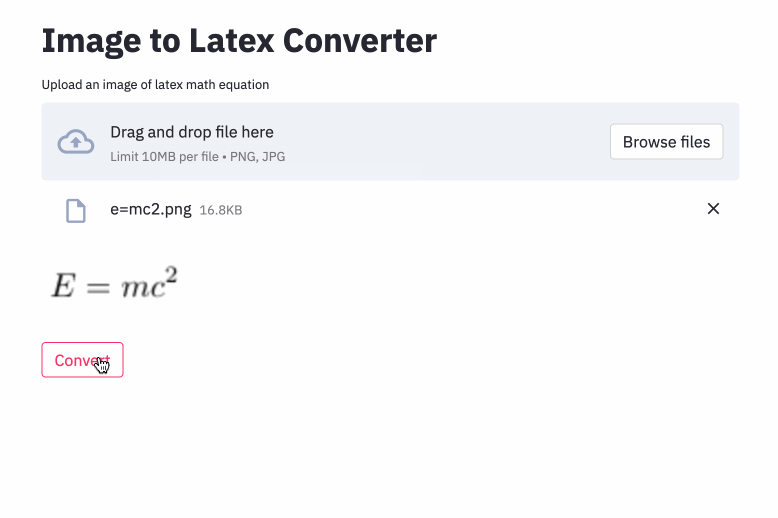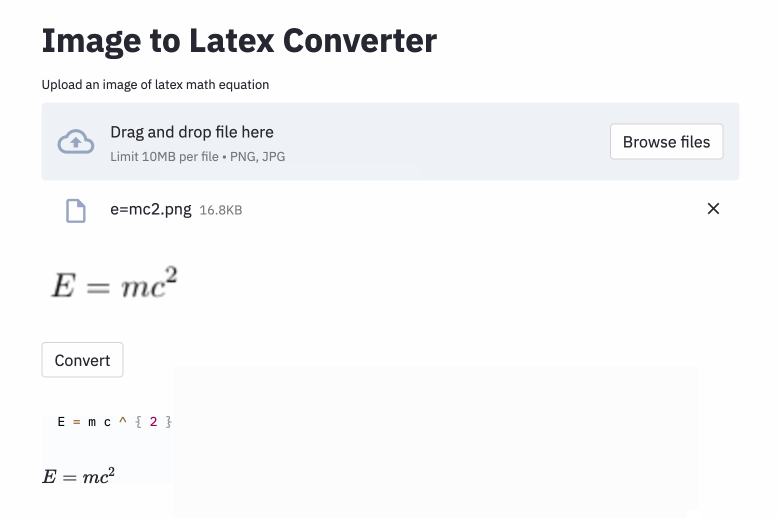
left(およびright)と同じように見える(および) )を生成するため、それらを正規化しました。vspace{2px}およびhspace{0.3mm} )を追加するために使用されます。ただし、スペースの長さは、人間でさえ判断するのが困難です。また、同じ間隔を表現する方法はたくさんあります(例:1 cm = 10 mm)。最後に、モデルが空白の画像にコードを生成したくないので、それらを削除しました。 ( vspaceとhspaceのみを削除しましたが、水平間隔には多くのコマンドがあることがわかりました。エラー分析中にのみ気付きました。以下を参照してください。) Best Runのキャラクターエラー率(CER)は、テストセットで0.17です。テストデータセットの例は次のとおりです。
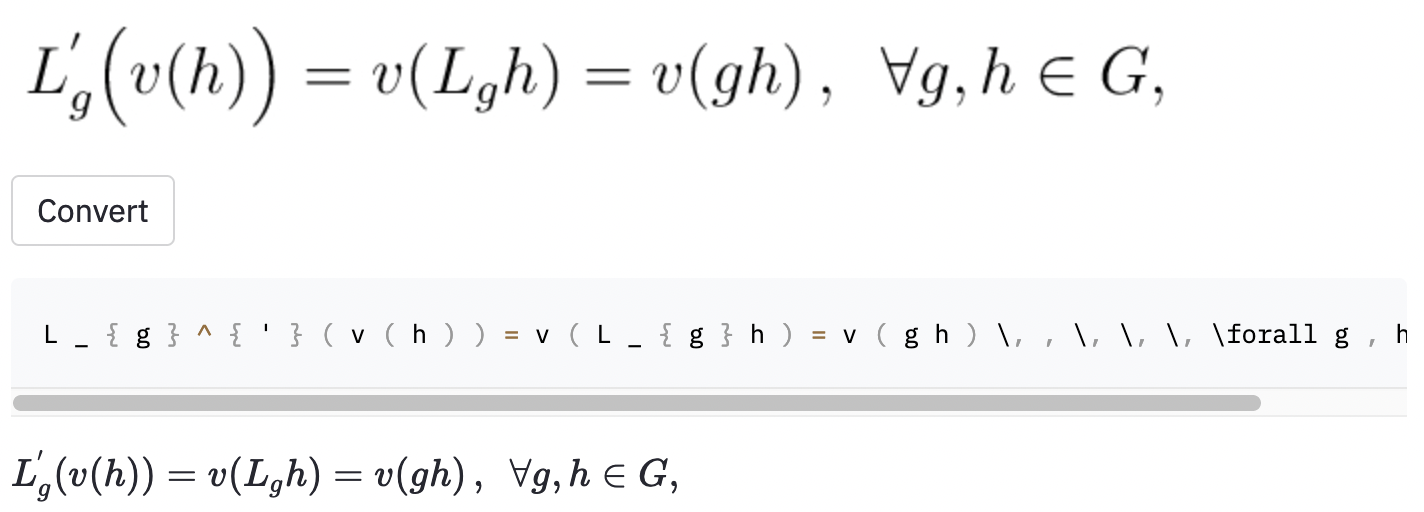
~を使用して作成されましたが、モデルは,使用したため、これはまだエラーとしてカウントされました。また、いくつかのランダムなウィキペディアの記事でいくつかのスクリーンショットを撮影して、モデルがデータセットの外側の画像に一般化するかどうかを確認しました。

calでコードをレンダリングできません。 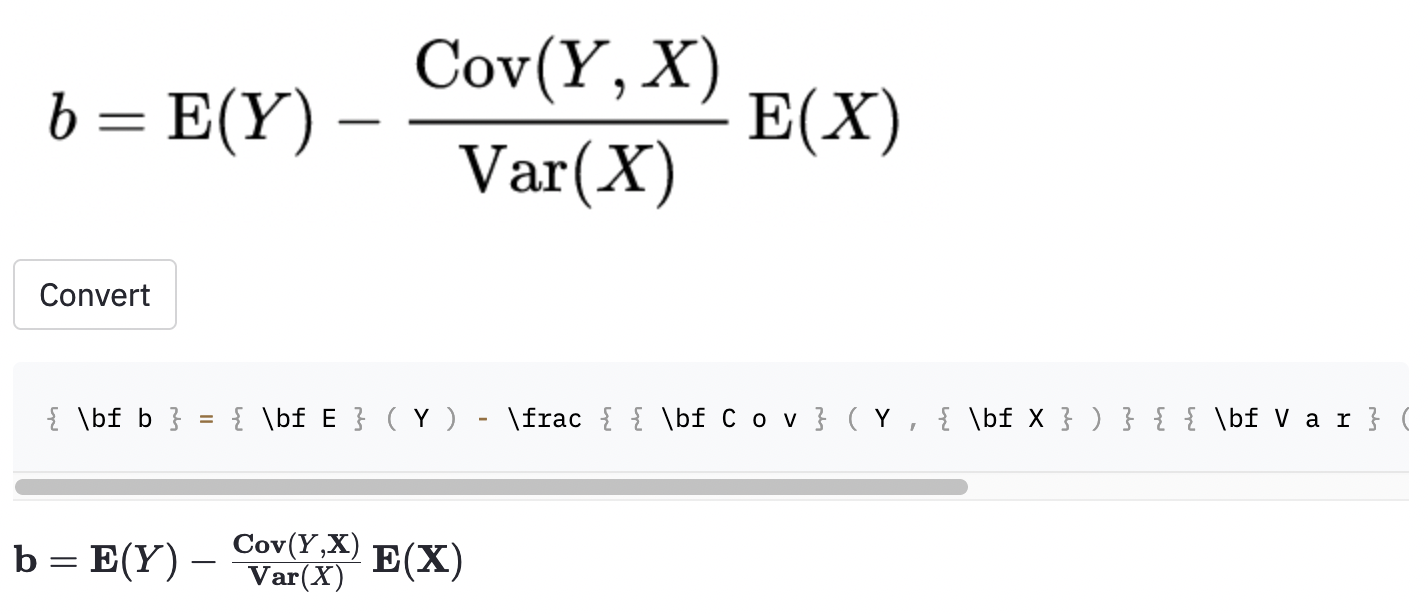
モデルは、画像がデータセットにあるものよりも大きい場合に問題があるようです。おそらく、データ増強プロセスの再スケーリング因子の範囲を増やす必要がありました。
私はプロジェクトの範囲をより良く定義すべきだったと思います:
( 、 big( 、 Big( bigg( 、 Bigg( )?)これらの質問は、データクリーニングプロセスをガイドするために使用する必要があります。
手書きの式をLaTexコードに変換するMathPix Snipと呼ばれるかなり確立されたツールを見つけました。その語彙サイズは約200です。数字と英語の文字を除くと、生成できるラテックスコマンドの数は実際には100をわずかに上回ります(IM2Latex-100Kの語彙サイズはほぼ500です)。 2つの水平間隔コマンド( quadとqquad )のみが含まれており、括弧のサイズが異なることを認識していません。現実世界のラテックスには非常に多くの曖昧さがあるので、限られた語彙セットに限定された語彙セットに閉じ込められているパーファは、私がすべきだったことです。
この作業の明らかな改善には、(1)より多くのエポックのモデルのトレーニング(時間のために、15エポックのモデルのみを訓練しましたが、検証損失はまだダウンしています)、(2)ビーム検索のみを使用して(私は貪欲な検索を実装しました)(3)大規模なモデルを使用して(例:ResNet-8の代わりにResNet-34を使用)、およびHypermeterの調整を使用します。計算リソースが限られていたので、これらのいずれもしませんでした(Google Colabを使用していました)。しかし、最終的には、曖昧なラベルを持たないデータを持っていて、より多くのデータ増強を行うことが、この問題の成功の鍵であると思います。
モデルPerformacneは私が望んでいたほど良くありませんが、このプロジェクトから学んだ教訓が、将来同様の問題に取り組みたい人にとって有用であることを願っています。
リポジトリをコンピューターにクローンし、コマンドラインをリポジトリフォルダー内に配置します。
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
次に、 venvという名前の仮想環境を作成し、必要なパッケージをインストールします。
make venv
make install-dev
次のコマンドを実行して、IM2Latex-100Kデータセットをダウンロードし、すべての前処理を行います。 (画像のトリミングステップには1時間以上かかる場合があります。)
python scripts/prepare_data.py
トレーニングセッションを開始するための例コマンド:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
構成はconf/config.yamlまたはコマンドラインで変更できます。詳細については、Hydraのドキュメントを参照してください。
最適なモデルチェックポイントは、重量とバイアス(W&B)に自動的にアップロードされます(トレーニングが開始される前にW&Bに登録またはログインするように求められます)。 W&Bからトレーニングされたモデルチェックポイントをダウンロードするための例コマンドを次に示します。
python scripts/download_checkpoint.py RUN_PATH
run_pathを実行のパスに置き換えます。実行パスは<entity>/<project>/<run_id>の形式である必要があります。特定の実験実行の実行パスを見つけるには、ダッシュボードの[概要]タブに移動します。
たとえば、次のコマンドを使用して私のベストランをダウンロードできます
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
チェックポイントは、プロジェクトディレクトリの下にあるartifactsという名前のフォルダーにダウンロードされます。
次のツールを使用して、コードベースを並べます。
isort :Pythonスクリプトに登録ステートメントをソートとフォーマットします。
black :PEP8に付着するコードフォーマッタ。
flake8 :Pythonスクリプトのスタイルの問題を報告するコードリナー。
mypy :Pythonスクリプトで静的タイプチェックを実行します。
次のコマンドを使用して、すべてのチェッカーとフォーマッタを実行します。
make lint
構成については、ルートディレクトリのpyproject.tomlおよびsetup.cfg参照してください。
同様のチェックは、コミットが行われたときに、コミット前のフレームワークによって自動的に行われます。構成については.pre-commit-config.yamlをご覧ください。
APIは、訓練されたモデルを使用して予測を行うために作成されます。次のコマンドを使用して、サーバーをアップして実行します。
make api
http://0.0.0.0:8000/docsで生成されたドキュメントを介してAPIを探索できます。
retrylitアプリを実行するには、新しい端末ウィンドウを作成し、次のコマンドを使用します。
make streamlit
アプリはブラウザで自動的に開かれる必要があります。 http:// localhost:8501にアクセスして開くこともできます。アプリが動作するには、実験実行のアーティファクトをダウンロードし(上記を参照)、APIを稼働させる必要があります。
APIのDocker画像を作成するには:
make docker
このプロジェクトは、UC Berkelyでのコースフルスタックディープラーニングの最終プロジェクトガイドラインのプロジェクトアイデアセクションに触発されています。コードの一部は、ラボから採用されています。
MLOPS -MAKEFILE、PRE -Commit、GitHub Actions、Pythonパッケージを紹介するためにMLで作られています。
IM2Latex-100KデータセットのHarvardnlp/IM2Markup。


