image to latex
1.0.0
Um aplicativo que mapeia uma imagem de uma equação de matemática de látex para o código de látex.
O problema da geração de imagem a markup foi tentado por Deng et al. (2016). Eles extraíram cerca de 100 mil fórmulas analisando fontes de papéis de látex do ARXIV. Eles renderizaram as fórmulas usando PDFlatex e converteram os arquivos PDF renderizados em formato PNG. As versões brutas e pré -processadas de seu conjunto de dados estão disponíveis online. Em seu modelo, uma CNN é usada pela primeira vez para extrair recursos de imagem. As linhas dos recursos são então codificadas usando um RNN. Finalmente, os recursos codificados são usados por um decodificador RNN com um mecanismo de atenção. O modelo possui 9,48 milhões de parâmetros no total. Recentemente, o Transformer ultrapassou o RNN para muitas tarefas de idiomas, então pensei em tentar esse problema.
Usando o conjunto de dados, treinei um modelo que usa Resnet-18 como codificador com codificação posicional 2D e um transformador como decodificador com perda de entropia cruzada. (Semelhante ao descrito em Singh et al. (2021), exceto que eu usei o Resnet apenas até o Bloqueio 3 para reduzir os custos computacionais, e excluí a codificação do número da linha, pois não se aplica a esse problema.) O modelo possui cerca de 3 milhões de parâmetros.
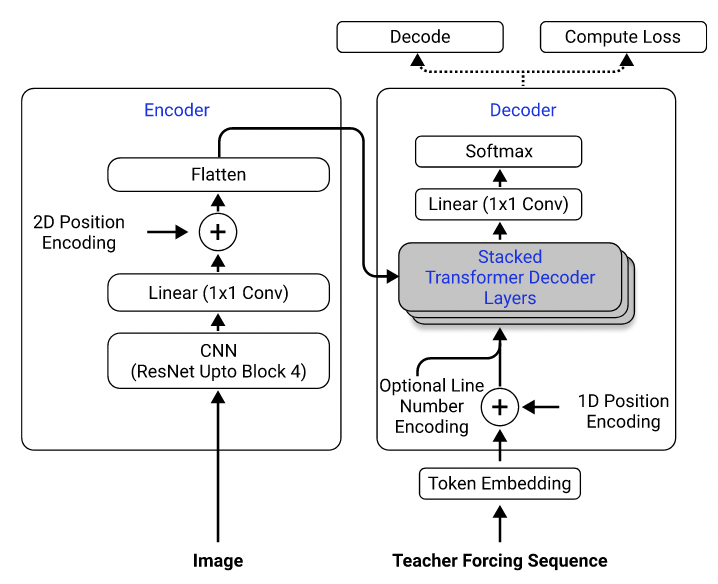
Arquitetura de modelo. Retirado de Singh et al. (2021).
Inicialmente, usei o conjunto de dados pré -processado para treinar meu modelo, porque as imagens pré -processadas são reduzidas para metade de seus tamanhos originais para obter eficiência e são agrupadas e acolchoadas em tamanhos semelhantes para facilitar lotes. No entanto, esse pré -processamento rígido acabou sendo uma enorme limitação. Embora o modelo possa atingir um desempenho razoável no conjunto de testes (que foi pré -processado da mesma maneira que o conjunto de treinamento), ele não generalizou bem para imagens fora do conjunto de dados, provavelmente porque a qualidade da imagem, o preenchimento e o tamanho da fonte são muito diferentes das imagens no conjunto de dados. Esse fenômeno também foi observado por outros que tentaram o mesmo problema usando o mesmo conjunto de dados (por exemplo, este projeto, esse problema e esse problema).
Para isso, usei o conjunto de dados bruto e incluí aumento da imagem (por exemplo, escala aleatória, ruído gaussiano) no meu pipeline de processamento de dados para aumentar a diversidade das amostras. Além disso, ao contrário de Deng et al. (2016), não agrupei imagens por tamanho. Em vez disso, eu os amamos uniformemente e os acolhei para o tamanho da maior imagem do lote, para que o modelo precise aprender a se adaptar a diferentes tamanhos de preenchimento.
Problemas adicionais que enfrentei no conjunto de dados:
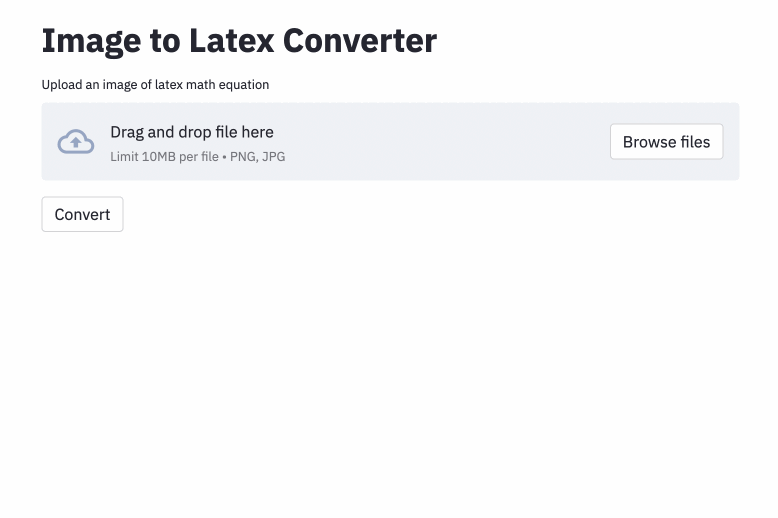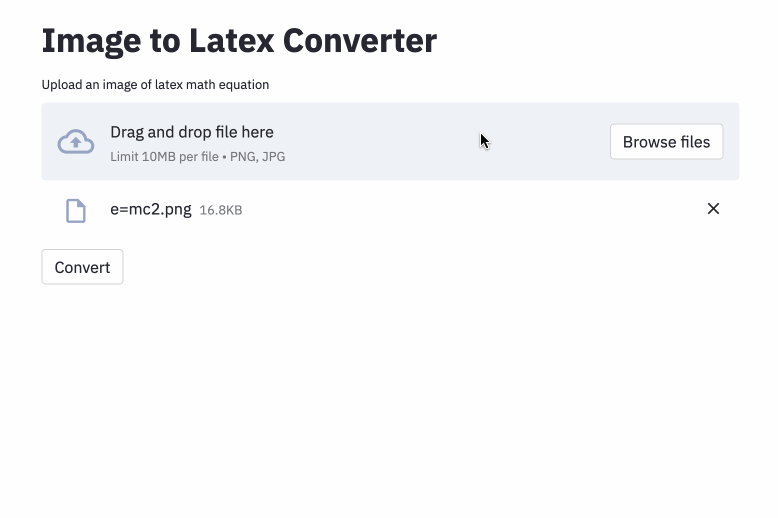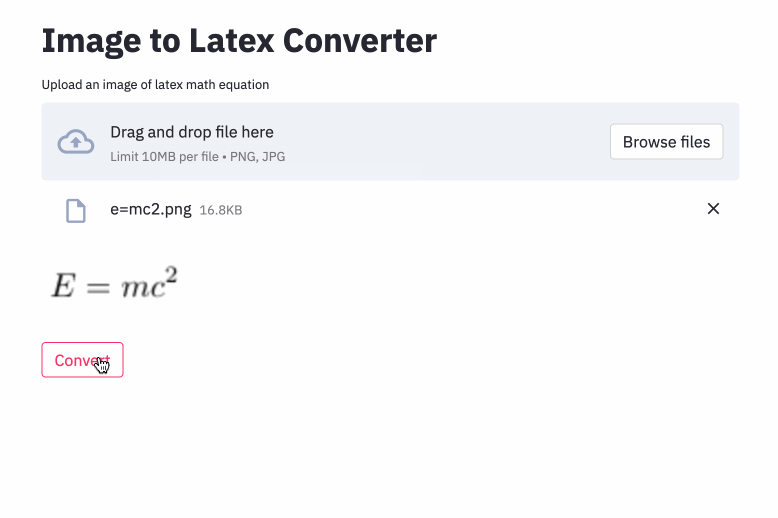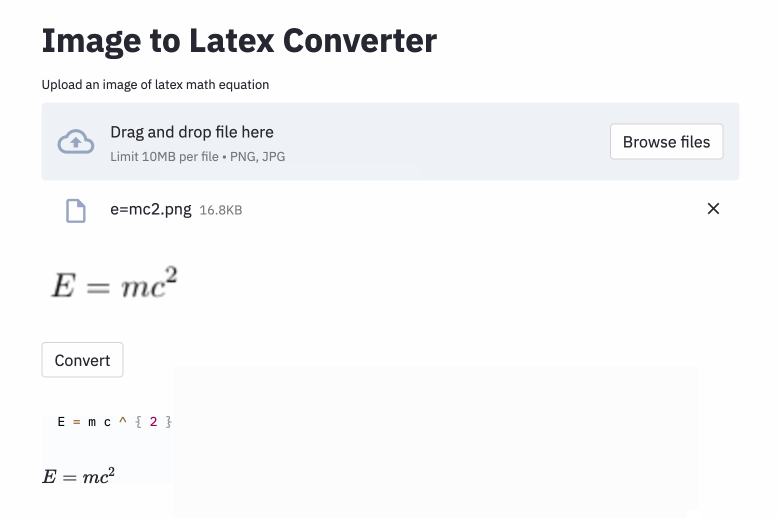
left( e right) parecem a mesma que ( e ) ), então eu os normalizei.vspace{2px} e hspace{0.3mm} ). No entanto, a duração do espaço é difícil de julgar até para os seres humanos. Além disso, existem muitas maneiras de expressar o mesmo espaçamento (por exemplo, 1 cm = 10 mm). Finalmente, não quero que o modelo gere código em imagens em branco, então as removi. (Eu apenas removi vspace e hspace , mas acaba por haver muitos comandos para o espaçamento horizontal. Só percebi isso durante a análise de erros. Veja abaixo.) A melhor execução tem uma taxa de erro de caractere (CER) de 0,17 no conjunto de testes. Aqui está um exemplo do conjunto de dados de teste:
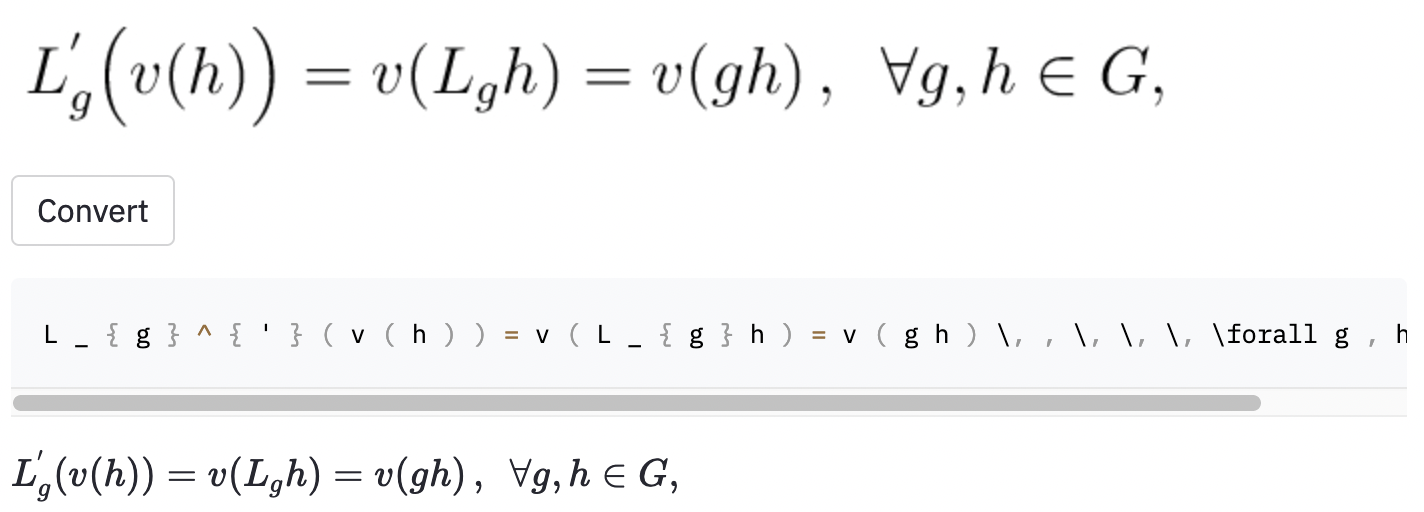
~ , enquanto o modelo usado , então isso ainda foi contado como um erro.Também tirei algumas capturas de tela em alguns artigos da Wikipedia aleatória para verificar se o modelo generaliza para imagens fora do conjunto de dados:

cal . 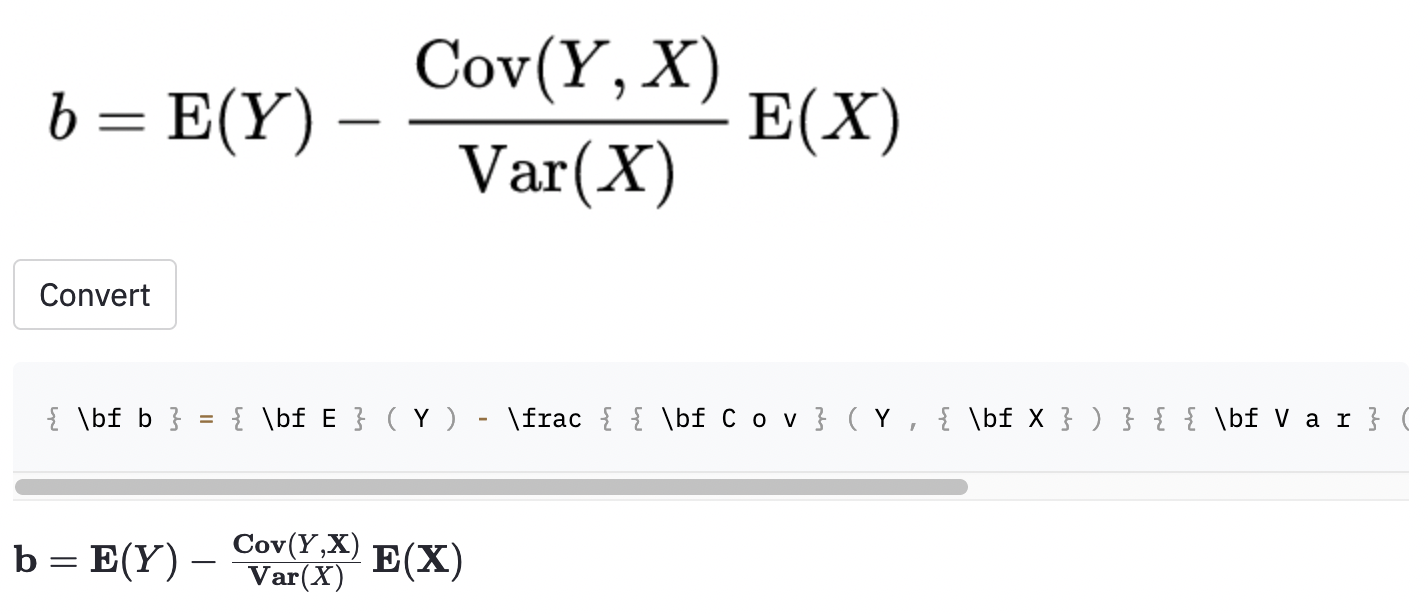
O modelo também parece ter algum problema quando a imagem é maior do que aqueles no conjunto de dados. Talvez eu deva ter aumentado a faixa de fator de reimaling no processo de aumento de dados.
Eu acho que deveria ter definido melhor o escopo do projeto:
( , big( , Big( , bigg( , Bigg( )?Essas perguntas devem ser usadas para orientar o processo de limpeza de dados.
Encontrei uma ferramenta bastante estabelecida chamada Mathpix SNIP que converte fórmulas manuscritas em código de látex. Seu tamanho de vocabulário é de cerca de 200. Excluindo números e letras em inglês, o número de comandos de látex que ele pode produzir está logo acima de 100. (O tamanho do vocabulário do IM2LATEX-100K é quase 500). Ele inclui apenas dois comandos de espaçamento horizontal ( quad e qquad ) e não reconhece tamanhos diferentes de parênteses. Perfas confinando a um conjunto limitado de vocabulário é o que eu deveria ter feito, já que existem tantas ambiguidades no látex do mundo real.
Melhorias possíveis óbvias deste trabalho incluem (1) treinando o modelo para mais épocas (por uma questão de tempo, treinei apenas o modelo para 15 épocas, mas a perda de validação ainda está diminuindo), (2) usando a pesquisa de feixes (eu implementei apenas a pesquisa gananciosa) e o modelo de uso de um modelo de resnegação e resnegagem de resnET-34 em vez de resnn. Eu não fiz nada disso, porque tinha recursos computacionais limitados (eu estava usando o Google Colab). Mas, em última análise, acredito que ter dados que não têm rótulos ambíguos e fazendo mais aumento de dados são as chaves para o sucesso desse problema.
O modelo de desempenho não é tão bom quanto eu quero, mas espero que as lições que aprendi com esse projeto sejam úteis para alguém queira enfrentar problemas semelhantes no futuro.
Clone o repositório no seu computador e posicione sua linha de comando dentro da pasta do repositório:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
Em seguida, crie um ambiente virtual chamado venv e instale os pacotes necessários:
make venv
make install-dev
Execute o seguinte comando para baixar o conjunto de dados IM2LATEX-100K e faça todo o pré-processamento. (A etapa de corte de imagem pode levar mais de uma hora.)
python scripts/prepare_data.py
Um comando de exemplo para iniciar uma sessão de treinamento:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
As configurações podem ser modificadas em conf/config.yaml ou na linha de comando. Veja a documentação da Hydra para saber mais.
O melhor ponto de verificação do modelo será enviado para pesos e vieses (W&B) automaticamente (você será solicitado a se registrar ou fazer login na W&B antes do início do treinamento). Aqui está um comando de exemplo para baixar um ponto de verificação de modelo treinado da W&B:
python scripts/download_checkpoint.py RUN_PATH
Substitua Run_Path pelo caminho da sua corrida. O caminho de execução deve estar no formato de <entity>/<project>/<run_id> . Para encontrar o caminho de execução para um experimento específico, vá para a guia Visão geral no painel.
Por exemplo, você pode usar o seguinte comando para baixar minha melhor corrida
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
O ponto de verificação será baixado para uma pasta chamada artifacts no diretório do projeto.
As seguintes ferramentas são usadas para conectar a base de código:
isort : Classifica e formatos importam instruções em scripts Python.
black : um formatador de código que adere ao pep8.
flake8 : um linhador de código que relata problemas estilísticos em scripts Python.
mypy : executa a verificação do tipo estático em scripts Python.
Use o comando a seguir para executar todos os damas e formatados:
make lint
Consulte pyproject.toml e setup.cfg no diretório raiz para suas configurações.
Verificações semelhantes são feitas automaticamente pela estrutura de pré-compromisso quando uma confirmação é feita. Confira .pre-commit-config.yaml para obter as configurações.
Uma API é criada para fazer previsões usando o modelo treinado. Use o seguinte comando para colocar o servidor em funcionamento:
make api
Você pode explorar a API através da documentação gerada em http://0.0.0.0:8000/docs.
Para executar o aplicativo StreamLit, crie uma nova janela do terminal e use o seguinte comando:
make streamlit
O aplicativo deve ser aberto no seu navegador automaticamente. Você também pode abri -lo visitando http: // localhost: 8501. Para que o aplicativo funcione, você precisa baixar os artefatos de um experimento (veja acima) e ter a API em funcionamento.
Para criar uma imagem do Docker para a API:
make docker
Este projeto é inspirado na seção de idéias do projeto nas diretrizes finais do projeto do curso de aprendizado profundo da UC Berkely. Parte do código é adotado em seus laboratórios.
MLOPS - Feito com ML para a introdução de ações makefile, pré -comprometimento, Github e embalagem Python.
Harvardnlp/IM2Markup para o conjunto de dados IM2LATEX-100K.


