image to latex
1.0.0
라텍스 수학 방정식의 이미지를 라텍스 코드에 매핑하는 응용 프로그램.
Deng et al. (2016). 그들은 Arxiv에서 라텍스 용지 소스를 구문 분석하여 약 100k 공식을 추출했습니다. 그들은 pdflatex를 사용하여 공식을 렌더링하고 렌더링 된 PDF 파일을 PNG 형식으로 변환했습니다. 데이터 세트의 원시 및 전처리 버전은 온라인으로 제공됩니다. 모델에서 CNN은 이미지 기능을 추출하는 데 사용됩니다. 그런 다음 기능 행을 RNN을 사용하여 인코딩합니다. 마지막으로, 인코딩 된 특징은주의 메커니즘을 갖는 RNN 디코더에 의해 사용된다. 이 모델에는 총 948 만 개의 매개 변수가 있습니다. 최근에 Transformer는 많은 언어 작업에 대해 RNN을 추월 했으므로이 문제를 해결할 수 있다고 생각했습니다.
데이터 세트를 사용하여 2D 위치 인코딩이있는 인코더로 RESNET-18을 사용하고 교차 엔트로피 손실이있는 디코더로 변압기를 사용하는 모델을 교육했습니다. (Singh et al. (2021)에 설명 된 것과 유사하게, 계산 비용을 줄이기 위해 RESNET을 Block 3까지 사용 했으며이 문제에 적용되지 않기 때문에 라인 번호 인코딩을 제외했습니다.) 모델에는 약 3 백만 개의 매개 변수가 있습니다.
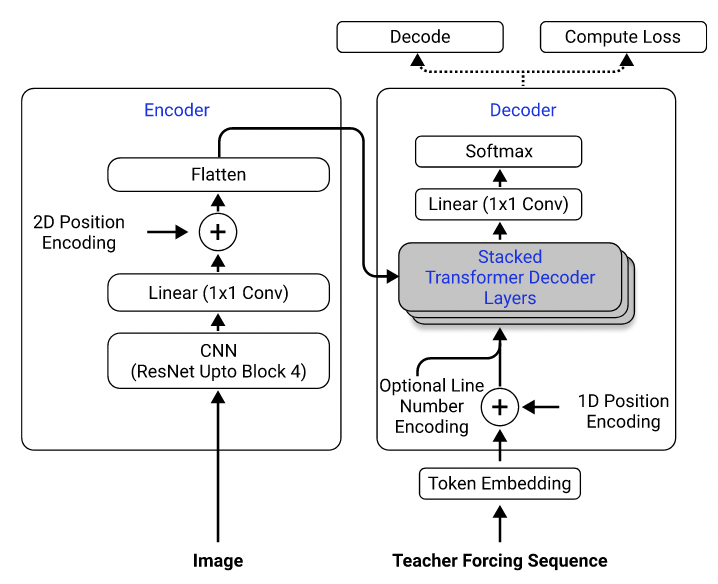
모델 아키텍처. Singh et al. (2021).
처음에는 전처리 된 데이터 세트를 사용하여 모델을 훈련 시켰습니다. 전처리 이미지는 효율성을 위해 원래 크기의 절반으로 다운 샘플링되며 유사한 크기로 그룹화되어 배치를 용이하게합니다. 그러나이 엄격한 전처리는 큰 제한으로 판명되었습니다. 모델은 테스트 세트에서 합리적인 성능을 달성 할 수 있지만 (교육 세트와 동일한 방식으로 전처리 된) 데이터 세트 외부의 이미지에 대해 일반화되지는 않았으며, 이미지 품질, 패딩 및 글꼴 크기가 데이터 세트의 이미지와 크게 다르기 때문에 가능성이 높습니다. 이 현상은 동일한 데이터 세트 (예 :이 프로젝트,이 문제 및이 문제)를 사용하여 동일한 문제를 시도한 다른 사람들에 의해 관찰되었습니다.
이를 위해 데이터 처리 파이프 라인에 원시 데이터 세트를 사용하고 데이터 처리 파이프 라인에 이미지 확대 (예 : 랜덤 스케일링, 가우스 노이즈)를 포함하여 샘플의 다양성을 높였습니다. 또한, Deng et al. (2016), 나는 크기별로 이미지를 그룹화하지 않았다. 오히려, 나는 그것들을 균일하게 샘플링하고 배치에서 가장 큰 이미지의 크기로 패딩하여 모델이 다른 패딩 크기에 적응하는 방법을 배워야합니다.
데이터 세트에서 직면 한 추가 문제 :
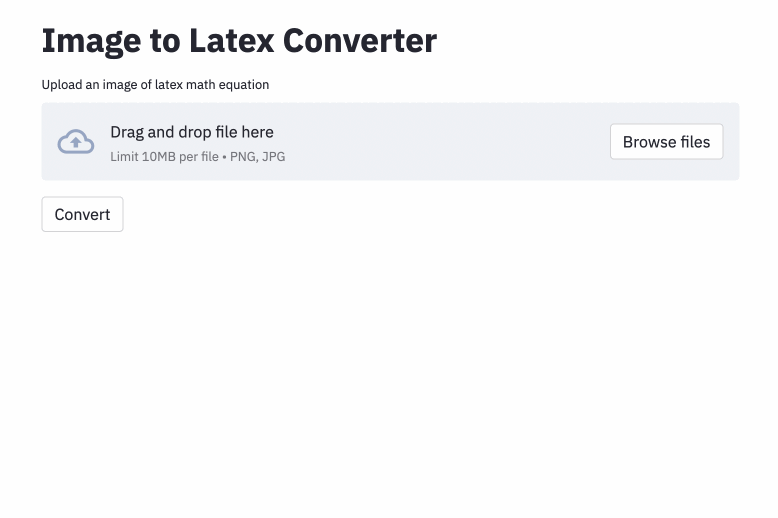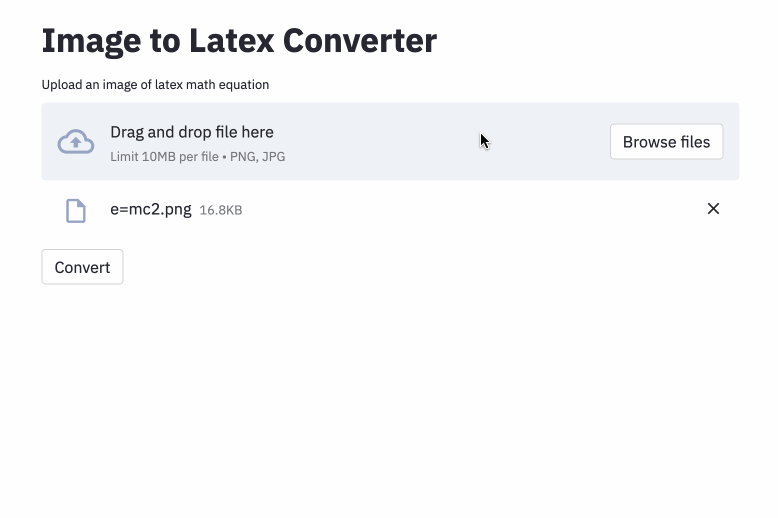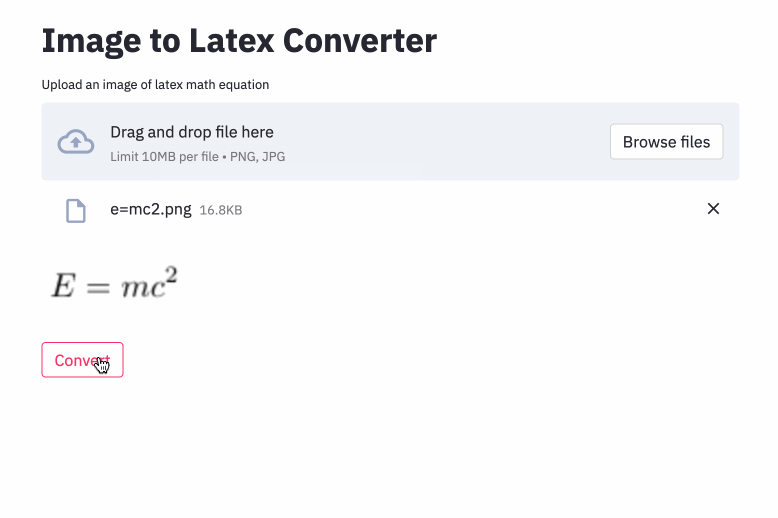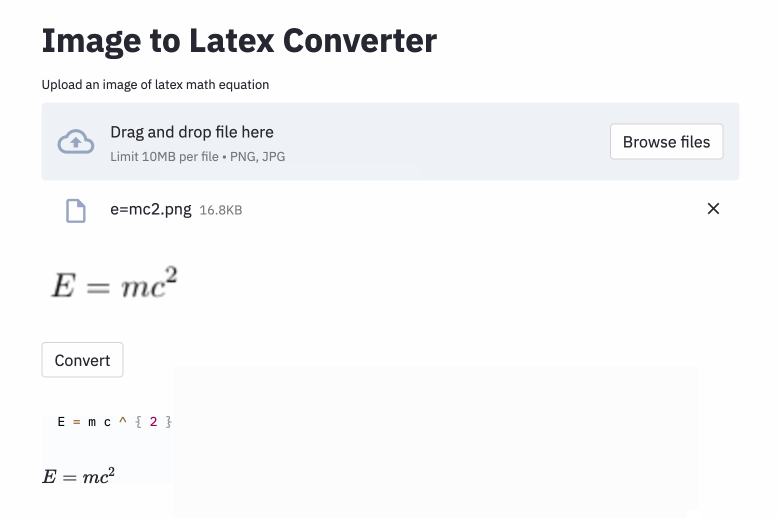
left( 및 right) ( 및 ) 와 동일하게 보이므로 정규화했습니다.vspace{2px} 및 hspace{0.3mm} )을 추가하는 데 사용됩니다. 그러나 공간의 길이는 인간에게도 판단하기가 어렵습니다. 또한 동일한 간격 (예 : 1 cm = 10 mm)을 표현하는 방법에는 여러 가지가 있습니다. 마지막으로 모델이 빈 이미지에서 코드를 생성하는 것을 원하지 않으므로 제거했습니다. ( vspace 와 hspace 만 제거했지만 수평 간격에 대한 많은 명령이 밝혀졌습니다. 오류 분석 중에 만 실현했습니다. 아래 참조). Best Run은 테스트 세트에서 0.17의 문자 오류율 (CER)을 가지고 있습니다. 다음은 테스트 데이터 세트의 예입니다.
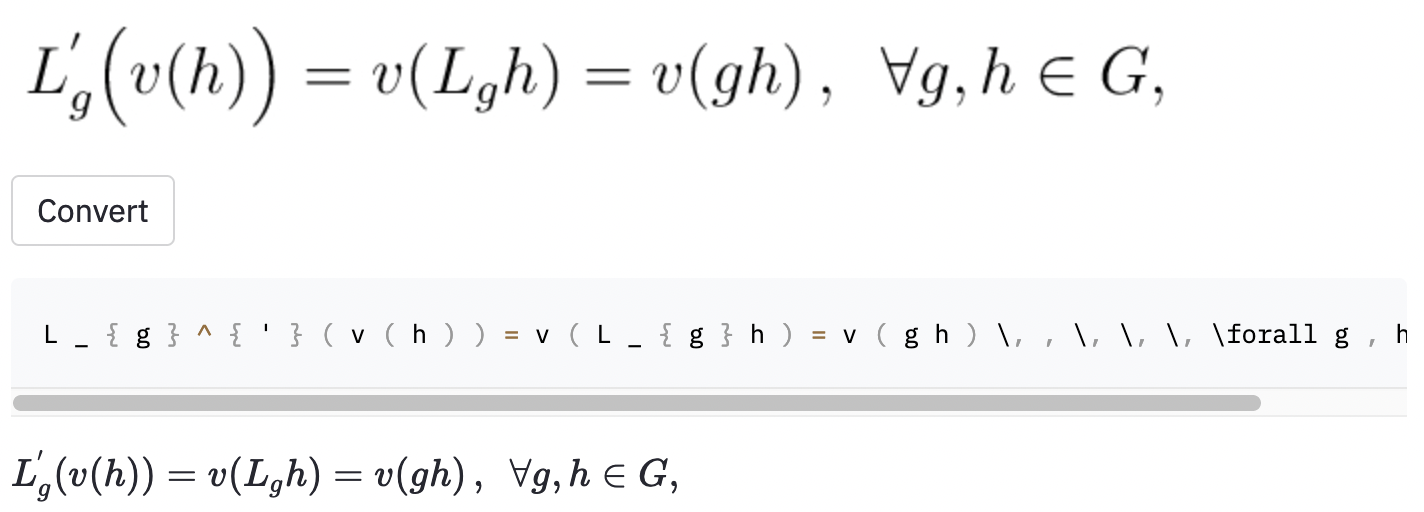
~ 를 사용하여 생성되었지만 모델은 , 사용 했으므로 여전히 오류로 계산되었습니다.또한 임의의 Wikipedia 기사에서 일부 스크린 샷을 가져 와서 모델이 데이터 세트 외부의 이미지로 일반화되는지 여부를 확인했습니다.

cal 로 코드를 렌더링 할 수 없습니다. 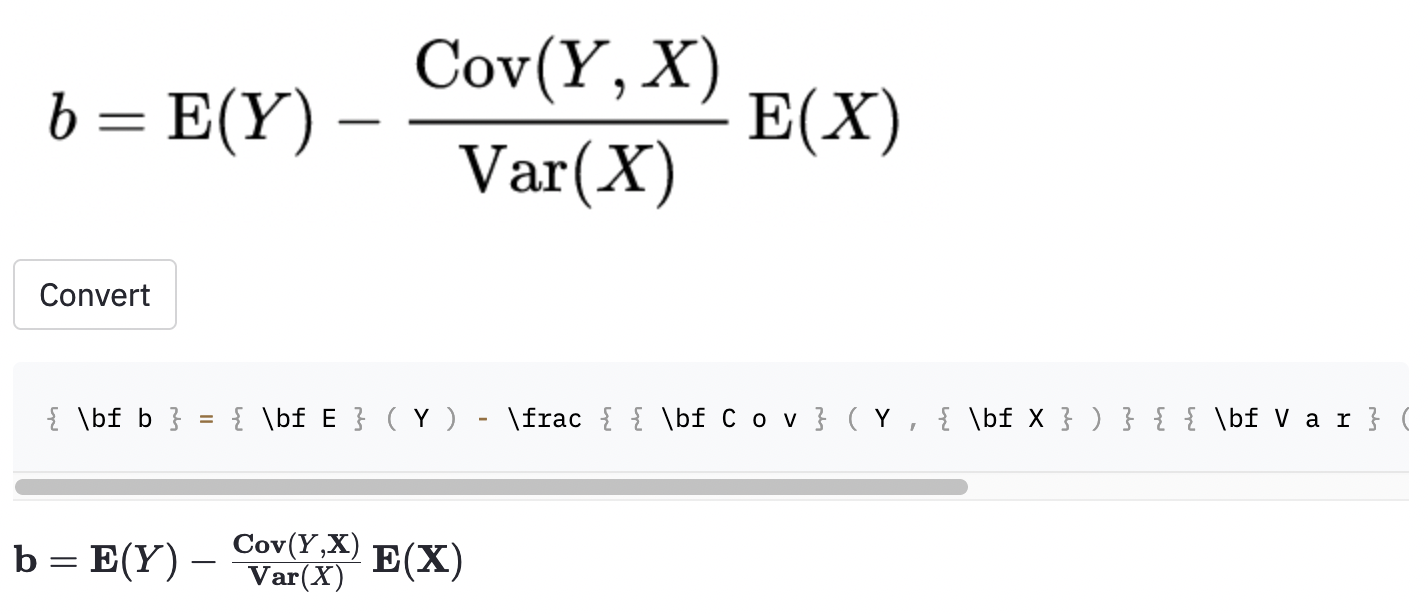
이미지가 이미지가 데이터 세트의 이미지보다 큰 경우 모델이 문제가있는 것 같습니다. 아마도 데이터 확대 프로세스에서 저조 요소의 범위를 증가시켜야했을 것입니다.
프로젝트의 범위를 더 잘 정의해야한다고 생각합니다.
( big (, big( (, Big( bigg( , Bigg( ))의 차이를 알려주기를 원합니까?이러한 질문은 데이터 정리 프로세스를 안내하는 데 사용해야합니다.
필기 공식을 라텍스 코드로 변환하는 MathPix Snip이라는 꽤 확립 된 도구를 발견했습니다. 어휘 크기는 약 200 개입니다. 숫자와 영어 문자를 제외하고, 생산할 수있는 라텍스 명령의 수는 실제로 100 이상입니다 (IM2LATEX-100K의 어휘 크기는 거의 500입니다). 여기에는 두 개의 수평 간격 명령 ( quad 및 qquad ) 만 포함되며 괄호의 다양한 크기를 인식하지 못합니다. 제한된 어휘에 한정되는 페르 파는 실제 라텍스에 많은 모호성이 있기 때문에 내가해야 할 일입니다.
이 작업의 명백한 개선에는 (1) 더 많은 시대에 대한 모델을 훈련시키는 것 (시간을 위해 15 개의 에포크에 대한 모델을 훈련 시켰지만 유효성 검색 손실은 여전히 줄어들고 있습니다), (2) 빔 검색 (greedy search 만 구현), (예 : RESNET-18 대신 RESNET-34를 사용) 및 일부 hyperparameter 튜닝을 수행합니다. 계산 리소스가 제한되어 있기 때문에 (Google Colab을 사용하고 있었기 때문에)이 작업을 수행하지 않았습니다. 그러나 궁극적으로, 나는 모호한 라벨이없고 더 많은 데이터 확대를 수행하는 데이터 가이 문제의 성공의 열쇠라고 생각합니다.
모델 Performacne은 내가 원하는만큼 좋지는 않지만이 프로젝트에서 배운 교훈이 미래에 비슷한 문제를 해결하기를 원하기를 바랍니다.
저장소를 컴퓨터로 복제하고 명령 줄을 저장소 폴더 내부에 배치하십시오.
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
그런 다음 venv 라는 가상 환경을 만들고 필요한 패키지를 설치하십시오.
make venv
make install-dev
다음 명령을 실행하여 IM2LATEX-100K 데이터 세트를 다운로드하고 모든 전처리를 수행하십시오. (이미지 자르기 단계는 1 시간 이상 걸릴 수 있습니다.)
python scripts/prepare_data.py
교육 세션을 시작하기위한 예제 명령 :
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
구성은 conf/config.yaml 또는 명령 줄에서 수정할 수 있습니다. 자세한 내용은 Hydra의 문서를 참조하십시오.
최고의 모델 체크 포인트는 가중치 및 바이어스 (W & B)에 자동으로 업로드됩니다 (교육이 시작되기 전에 W & B에 등록하거나 로그인하라는 요청을받습니다). 다음은 W & B에서 숙련 된 모델 체크 포인트를 다운로드하는 예제 명령입니다.
python scripts/download_checkpoint.py RUN_PATH
run_path를 실행 경로로 교체하십시오. 실행 경로는 <entity>/<project>/<run_id> 형식이어야합니다. 특정 실험 실행의 실행 경로를 찾으려면 대시 보드의 개요 탭으로 이동하십시오.
예를 들어 다음 명령을 사용하여 내 Best Run을 다운로드 할 수 있습니다.
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
체크 포인트는 프로젝트 디렉토리의 artifacts 라는 폴더로 다운로드됩니다.
다음 도구는 코드베이스를 보풀하는 데 사용됩니다.
isort : 파이썬 스크립트의 정렬 및 형식 가져 오기 문.
black : PEP8에 부착되는 코드 포맷터.
flake8 : 파이썬 스크립트에서 문체 문제를보고하는 코드 라이터.
mypy : 파이썬 스크립트에서 정적 유형 확인을 수행합니다.
다음 명령을 사용하여 모든 체커와 형성자를 실행하십시오.
make lint
구성은 루트 디렉토리의 pyproject.toml 및 setup.cfg 참조하십시오.
커밋이 이루어질 때 사전 커밋 프레임 워크에 의해 비슷한 점검이 자동으로 수행됩니다. 구성은 .pre-commit-config.yaml 확인하십시오.
훈련 된 모델을 사용하여 예측을하기 위해 API가 만들어졌습니다. 다음 명령을 사용하여 서버를 작동시키고 실행하십시오.
make api
생성 된 문서를 통해 http://0.0.0:8000/docs를 통해 API를 탐색 할 수 있습니다.
Streamlit 앱을 실행하려면 새 터미널 창을 작성하고 다음 명령을 사용하십시오.
make streamlit
앱은 브라우저에서 자동으로 열려야합니다. http : // localhost : 8501을 방문하여 열 수 있습니다. 앱이 작동하려면 실험 실행의 아티팩트 (위 참조)를 다운로드하고 API를 업 및 실행해야합니다.
API 용 Docker 이미지를 작성하려면 :
make docker
이 프로젝트는 UC Berkely의 코스 풀 스택 딥 러닝의 최종 프로젝트 가이드 라인에서 프로젝트 아이디어 섹션에서 영감을 얻었습니다. 일부 코드는 실험실에서 채택되었습니다.
Mlops- Makefile, Pre -Commit, Github 액션 및 Python 포장을 도입하기 위해 ML로 제작되었습니다.
IM2LATEX-100K 데이터 세트 용 HarvardNlp/IM2Markup.


