image to latex
1.0.0
Una aplicación que mapea una imagen de una ecuación de matemáticas de látex al código de látex.
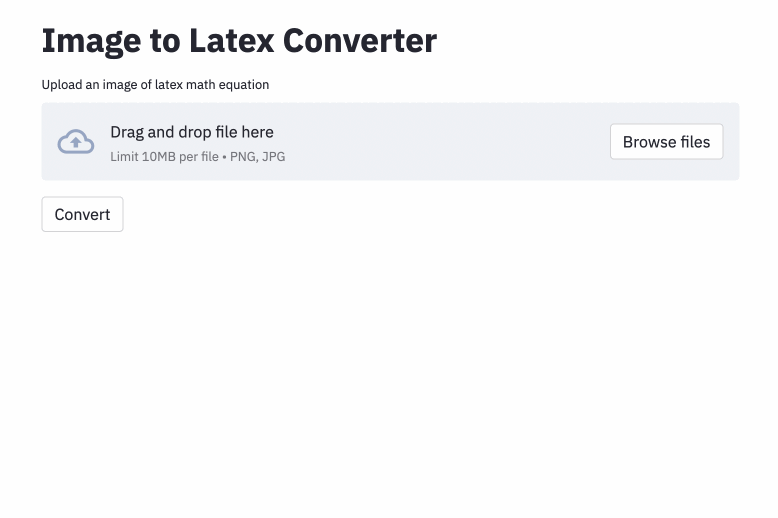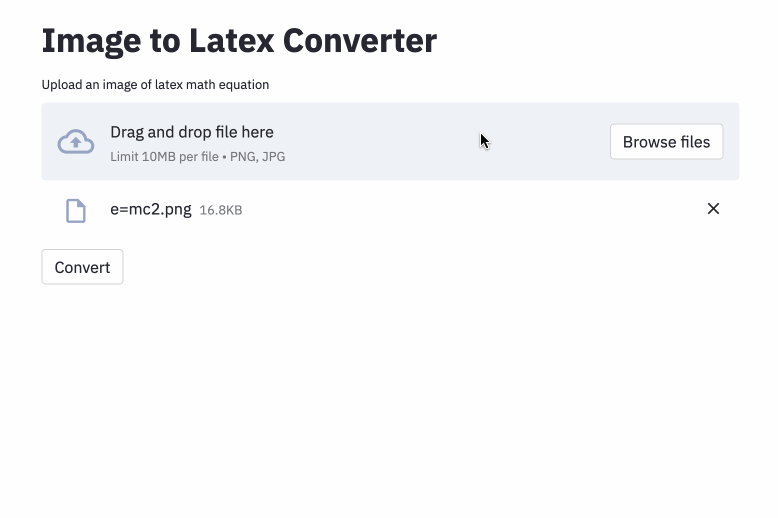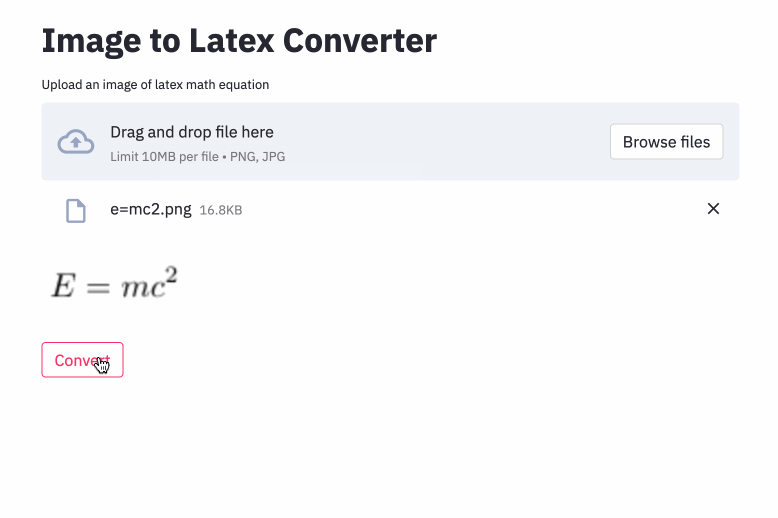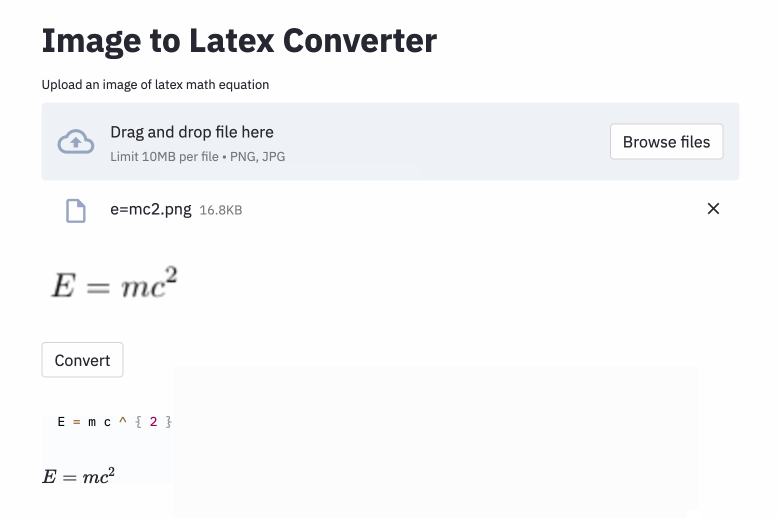
Deng et al. Intentó el problema de la generación de imagen a markup. (2016). Extrajaron unas 100k fórmulas al analizar las fuentes de látex de los documentos del ARXIV. Renderizaron las fórmulas usando PDFLATEX y convirtieron los archivos PDF renderizados en formato PNG. Las versiones en bruto y preprocesadas de su conjunto de datos están disponibles en línea. En su modelo, se utiliza un CNN para extraer características de imagen. Las filas de las características se codifican usando un RNN. Finalmente, las características codificadas son utilizadas por un decodificador RNN con un mecanismo de atención. El modelo tiene 9.48 millones de parámetros en total. Recientemente, Transformer ha superado a RNN para muchas tareas de idiomas, por lo que pensé que podría intentarlo en este problema.
Usando su conjunto de datos, entrené un modelo que utiliza resnet-18 como codificador con codificación posicional 2D y un transformador como decodificador con pérdida de entropía cruzada. (Similar al descrito en Singh et al. (2021), excepto que utilicé REDNET solo hasta el bloque 3 para reducir los costos computacionales, y excluyé el número de línea de codificación, ya que no se aplica a este problema). El modelo tiene alrededor de 3 millones de parámetros.
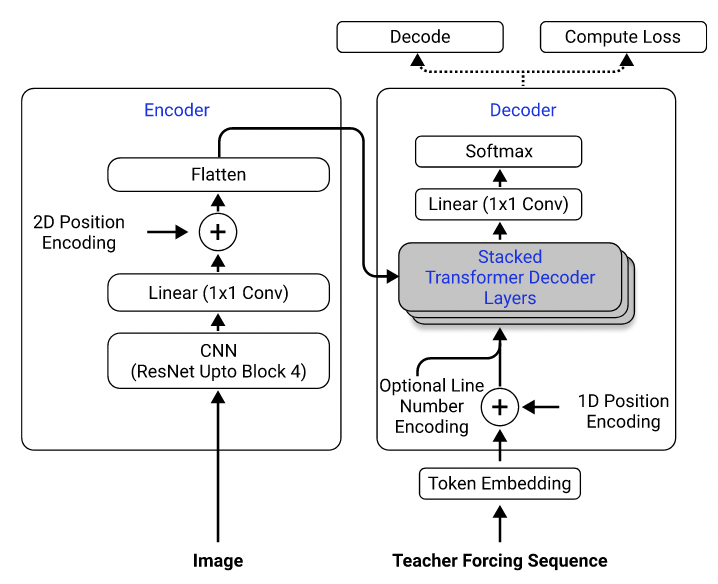
Arquitectura modelo. Tomado de Singh et al. (2021).
Inicialmente, utilicé el conjunto de datos preprocesado para entrenar mi modelo, porque las imágenes preprocesadas se muestrean a la mitad de sus tamaños originales para la eficiencia, y se agrupan y se acolchan en tamaños similares para facilitar el lotes. Sin embargo, este preprocesamiento rígido resultó ser una gran limitación. Aunque el modelo podría lograr un rendimiento razonable en el conjunto de pruebas (que estaba preprocesado de la misma manera que el conjunto de entrenamiento), no se generalizó bien a las imágenes fuera del conjunto de datos, muy probablemente porque la calidad de imagen, el relleno y el tamaño de la fuente son muy diferentes de las imágenes en el conjunto de datos. Este fenómeno también ha sido observado por otros que han intentado el mismo problema utilizando el mismo conjunto de datos (por ejemplo, este proyecto, este problema y este problema).
Con este fin, utilicé el conjunto de datos sin procesar e incluí el aumento de imagen (por ejemplo, escala aleatoria, ruido gaussiano) en mi tubería de procesamiento de datos para aumentar la diversidad de las muestras. Además, a diferencia de Deng et al. (2016), no agrupé imágenes por tamaño. Más bien, los probé uniformemente y los acolché al tamaño de la imagen más grande en el lote, para que el modelo debe aprender cómo adaptarse a diferentes tamaños de relleno.
Problemas adicionales que enfrenté en el conjunto de datos:
left( y right) se ve igual que ( y ) ), por lo que las normalicé.vspace{2px} y hspace{0.3mm} ). Sin embargo, la longitud del espacio es difícil de juzgar incluso para los humanos. Además, hay muchas formas de expresar el mismo espacio (por ejemplo, 1 cm = 10 mm). Finalmente, no quiero que el modelo genere código en imágenes en blanco, así que las eliminé. (Solo eliminé vspace y hspace , pero resulta que hay muchos comandos para el espaciado horizontal. Solo me di cuenta de que durante el análisis de errores. Ver más abajo). La mejor ejecución tiene una tasa de error de caracteres (CER) de 0.17 en el conjunto de pruebas. Aquí hay un ejemplo del conjunto de datos de prueba:
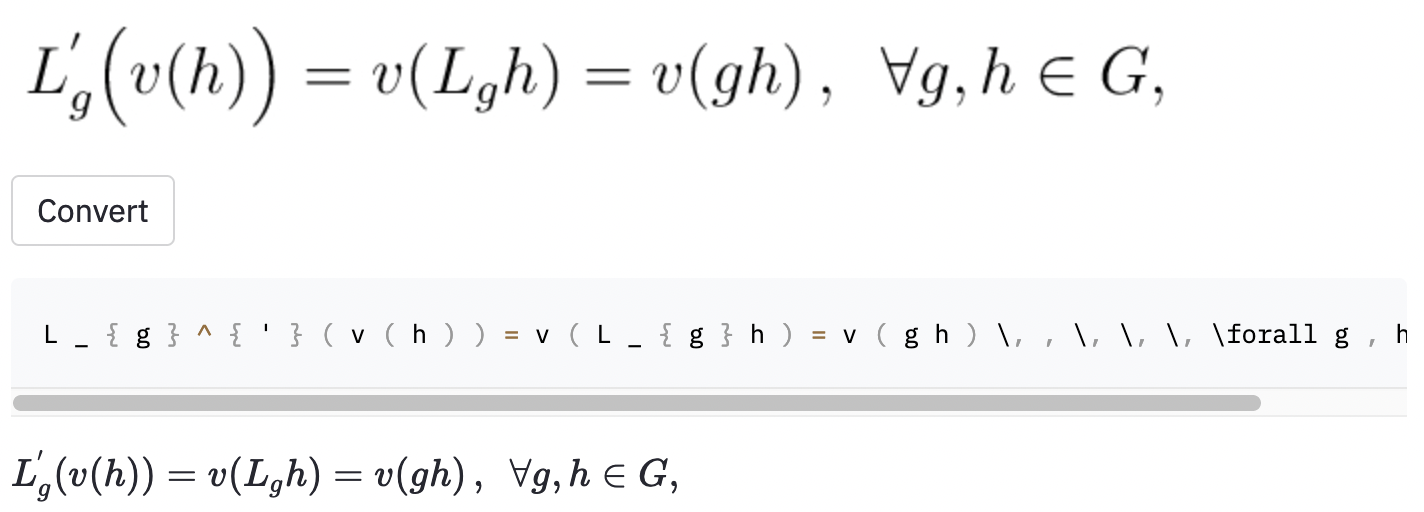
~ , mientras que el modelo utilizado , por lo que esto todavía se contó como un error.También tomé algunas capturas de pantalla en algunos artículos de Wikipedia aleatorios para ver si el modelo se generaliza a las imágenes fuera del conjunto de datos:

cal . 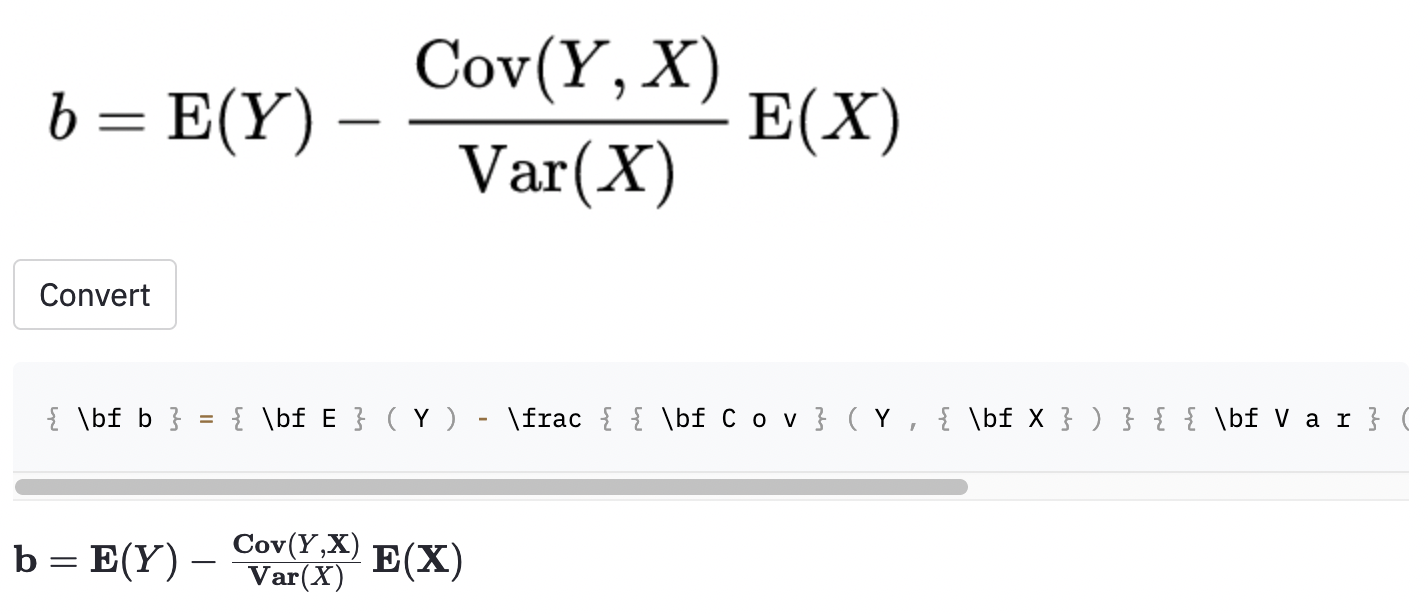
El modelo también parece tener algunos problemas cuando la imagen es más grande que las del conjunto de datos. Quizás debería haber aumentado el rango de factor de reescalado en el proceso de aumento de datos.
Creo que debería haber definido mejor el alcance del proyecto:
( , big( , Big( , bigg( , Bigg( )?Estas preguntas deben usarse para guiar el proceso de limpieza de datos.
Encontré una herramienta bastante establecida llamada Snip MathPix que convierte fórmulas escritas a mano en código de látex. Su tamaño de vocabulario es de alrededor de 200. Excluyendo números y letras en inglés, el número de comandos de látex que puede producir es en realidad solo por encima de 100. (El tamaño de vocabulario de IM2Latex-100k es casi 500). Solo incluye dos comandos de espaciado horizontal ( quad y qquad ), y no reconoce diferentes tamaños de paréntesis. Las perhas que confinan a un conjunto limitado de vocabulario es lo que debería haber hecho, ya que hay tantas ambigüedades en el látex del mundo real.
Las mejoras obvias posibles de este trabajo incluyen (1) capacitar el modelo para más épocas (por el tiempo del tiempo, solo capacité el modelo para 15 épocas, pero la pérdida de validación aún está disminuyendo), (2) usando la búsqueda de haz (solo implementé una búsqueda codiciosa), (3) usando un modelo más grande (EG, use resnet-34 en lugar de resnet-18) y realicé un poco de hyperparameter. No hice ninguno de estos, porque tenía recursos computacionales limitados (estaba usando Google Colab). Pero en última instancia, creo que tener datos que no tienen etiquetas ambiguas y hacer más aumentos de datos son las claves para el éxito de este problema.
El modelo PerformaCne no es tan bueno como quiero ser, pero espero que las lecciones que aprendí de este proyecto sean útiles para alguien que quiere abordar problemas similares en el futuro.
Clonar el repositorio de su computadora y colocar su línea de comando dentro de la carpeta del repositorio:
git clone https://github.com/kingyiusuen/image-to-latex.git
cd image-to-latex
Luego, cree un entorno virtual llamado venv e instale los paquetes requeridos:
make venv
make install-dev
Ejecute el siguiente comando para descargar el conjunto de datos IM2Latex-100k y hacer todo el preprocesamiento. (El paso de recorte de imagen puede tomar más de una hora).
python scripts/prepare_data.py
Un comando de ejemplo para comenzar una sesión de entrenamiento:
python scripts/run_experiment.py trainer.gpus=1 data.batch_size=32
Las configuraciones se pueden modificar en conf/config.yaml o en la línea de comando. Vea la documentación de Hydra para obtener más información.
El mejor punto de control modelo se cargará en pesas y sesgos (W&B) automáticamente (se le pedirá que se registre o inicie sesión en W&B antes de que comience la capacitación). Aquí hay un comando de ejemplo para descargar un punto de control de modelo capacitado de W&B:
python scripts/download_checkpoint.py RUN_PATH
Reemplace run_path con la ruta de su ejecución. La ruta de ejecución debe estar en el formato de <entity>/<project>/<run_id> . Para encontrar la ruta de ejecución para un experimento en particular, vaya a la pestaña Descripción general en el tablero.
Por ejemplo, puede usar el siguiente comando para descargar mi mejor ejecución
python scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1
El punto de control se descargará en una carpeta llamada artifacts en el directorio del proyecto.
Las siguientes herramientas se utilizan para pelear la base de código:
isort : las tipos y formatos importan declaraciones en scripts de Python.
black : un formato de código que se adhiere a Pep8.
flake8 : un enlace de código que informa problemas estilísticos en los scripts de Python.
mypy : realiza la verificación de tipo estático en los scripts de Python.
Use el siguiente comando para ejecutar todos los damas y formatorios:
make lint
Consulte pyproject.toml y setup.cfg en el directorio raíz para sus configuraciones.
Las verificaciones similares se realizan automáticamente por el marco previo al compromiso cuando se realiza una confirmación. Consulte .pre-commit-config.yaml para ver las configuraciones.
Se crea una API para hacer predicciones utilizando el modelo entrenado. Use el siguiente comando para poner en funcionamiento el servidor:
make api
Puede explorar la API a través de la documentación generada en http://0.0.0.0:8000/docs.
Para ejecutar la aplicación Streamlit, cree una nueva ventana de terminal y use el siguiente comando:
make streamlit
La aplicación debe abrirse en su navegador automáticamente. También puede abrirlo visitando http: // localhost: 8501. Para que la aplicación funcione, debe descargar los artefactos de un experimento ejecutado (ver arriba) y tener la API en funcionamiento.
Para crear una imagen Docker para la API:
make docker
Este proyecto está inspirado en la sección Ideas del proyecto en las directrices finales del proyecto del curso de aprendizaje profundo de la pila completa en UC Berkely. Parte del código se adopta de sus laboratorios.
MLOPS - Hecho con ML para introducir Makefile, Precomitar, Github Actions y Python Packaging.
Harvardnlp/IM2Markup para el conjunto de datos IM2Latex-100k.


