byteps
v0.2
Byteps是高性能和一般分佈式培訓框架。它支持TensorFlow,Keras,Pytorch和MXNET,並且可以在TCP或RDMA網絡上運行。
比較勝過現有的開源分佈式培訓框架的優於大幅度。例如,在Bert-large訓練中,使用256 GPU可以實現〜90%的縮放效率(見下文),這比Horovod+NCCL高得多。在某些情況下,與Horovod+NCCL相比,訓練速度可以使訓練速度增加一倍。
bpslaunch作為啟動任務的命令。pip3 install byteps 我們展示了基於Gluonnlp工具包的Bert-Large訓練實驗。該模型使用混合精度。
我們使用Tesla V100 32GB GPU,將批量大小等於每GPU 64。每台機器具有8個V100 GPU(32GB內存),並具有NVLINK啟用。機器與100 Gbps RDMA網絡相互連接。這是您可以在AWS上獲得的硬件設置。
Byteps具有256 GPU的BERT-LARGE的縮放效率約為90%。該代碼可在此處使用。作為比較,即使在專家參數調諧之後,Horovod+NCCL的縮放效率也只有〜70%。
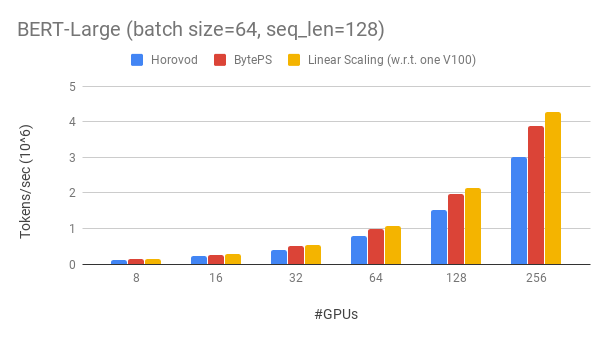
借助較慢的網絡,ByTeps提供了更多的性能優勢 - 最高2倍Horovod+NCCL。您可以在performance.md上找到更多評估結果。
BOYTEPS如何超越Horovod?主要原因之一是ByTeps是為雲和共享簇設計的,並扔掉了MPI。
MPI出生於HPC世界,非常適合一個由均質硬件構建的集群,也可以運行一份工作。但是,雲(或內部共享簇)是不同的。
如這裡所述,這使我們重新考慮了最佳的溝通策略。簡而言之,小節僅在機器內使用NCCL,而重新構想了機間通信。
ByTeps還結合了許多加速技術,例如層次策略,管道張力,張量分區,NUMA了解本地通信,基於優先級的調度等等。
我們為您提供一個基準培訓任務的分步教程。最簡單的開始方法是使用我們的Docker圖像。請參閱文檔以獲取如何啟動分佈式作業和更詳細的配置。啟動byteps之後,請閱讀最佳練習以獲得最佳性能。
在下面,我們說明如何自己安裝字節。有兩個選擇。
pip3 install byteps
您可以通過直接從主分支機構安裝來嘗試最新功能:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
上述兩個選項的註釋:
export BYTEPS_NCCL_HOME=/path/to/nccl指定NCCL路徑。默認情況下,它指向/usr/local/nccl 。yum install devtoolset-7 。通常,我們建議使用GCC 4.9進行最佳兼容性(如何固定GCC)。示例文件夾下提供了基本示例。
要在OSDI'20論文中重現端到端評估,請在此存儲庫中找到代碼。
儘管Byteps完全不同,但與Horovod接口高度兼容(謝謝Horovod社區!)。我們選擇了Horovod界面,以最大程度地減少您在測試字節上的努力。
如果您的任務僅依賴於Horovod的Alleduce和廣播,則應在1分鐘內切換到字節。只需將import horovod.tensorflow as hvd import byteps.tensorflow as bps hvd,然後用bps替換代碼中的所有hvd 。如果您的代碼直接調用hvd.allreduce ,則還應由bps.push_pull替換。
我們的許多例子都是從Horovod複製的,並以這種方式進行了修改。例如,比較字節和horovod的mnist示例。
ByTeps還支持其他本機API,例如Pytorch分佈式數據並行和TensorFlow鏡像策略。有關使用情況,請參見DistributeDataParallel.MD和MirroredStrategy.md。
字節暫時不支持純CPU培訓。原因之一是,廉價的PS假設不適合CPU培訓。因此,您需要CUDA和NCCL才能構建和運行Byteps。
我們希望具有以下功能,並且在Byteps Architecture中實現它們沒有根本的困難。但是,它們尚未實施:
[OSDI'20]“在異質GPU/CPU群集中加速分佈式DNN培訓的統一體系結構”。 Yimin Jiang,Yibo Zhu,Chang Lan,Bairen Yi,Yong Cui,Chuanxiong Guo。
[SOSP'19]“分佈式DNN培訓加速的通用通信調度程序”。 Yangua Peng,Yibo Zhu,Yangrui Chen,Yixin Bao,Bairen YI,Chang Lan,Chuan Wu,Chuanxiong Guo。 (代碼位於Bytescheduler分支)


