byteps
v0.2
Byteps ist eine hohe Leistung und ein allgemeiner verteilter Trainingsrahmen. Es unterstützt TensorFlow, Keras, Pytorch und MXNET und kann entweder im TCP- oder im RDMA -Netzwerk ausgeführt werden.
Byteps übertrifft vorhandene Open-Sourcing-Schulungsrahmen mit einem großen Vorsprung. Zum Beispiel können Byteps beim Bert-Large-Training ~ 90% Skalierungseffizienz mit 256 GPUs (siehe unten) erreichen, was viel höher ist als Horovod+NCCL. In bestimmten Szenarien können Byteps die Trainingsgeschwindigkeit im Vergleich zu Horovod+NCCL verdoppeln.
bpslaunch als Befehl hinzu, um Aufgaben zu starten.pip3 install byteps Wir zeigen unser Experiment zum Bert-Large-Training, das auf Gluonnlp Toolkit basiert. Das Modell verwendet gemischte Präzision.
Wir verwenden Tesla V100 32 GB GPUs und setzen die Chargengröße von 64 pro GPU. Jede Maschine verfügt über 8 V100-GPUs (32 GB Speicher) mit NVLink-fähig. Maschinen sind mit einem 100-Gbit / s-RDMA-Netzwerk miteinander verbunden. Dies ist das gleiche Hardware -Setup, das Sie auf AWS erhalten können.
Byteps erreicht ~ 90% Skalierungseffizienz für Bert-Large mit 256 GPUs. Der Code ist hier verfügbar. Zum Vergleich hat Horovod+NCCL auch nach der Messung von Expertenparametern nur ~ 70% Skalierungseffizienz.
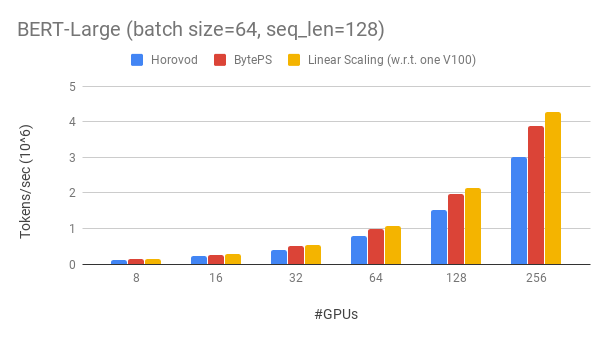
Mit einem langsameren Netzwerk bietet Byteps noch mehr Leistungsvorteile - bis zu 2x Horovod+NCCL. Sie können mehr Bewertungsergebnisse bei der Leistung finden.md.
Wie können Byteps Horovod um so viel übertreffen? Einer der Hauptgründe ist, dass Byteps für Cloud- und gemeinsame Cluster ausgelegt ist und MPI wegwirft.
MPI wurde in der HPC -Welt geboren und ist gut für einen Cluster, der mit homogener Hardware gebaut wurde und einen einzigen Job ausführt. Die Cloud (oder intern geteilte Cluster) ist jedoch unterschiedlich.
Dies führt uns dazu, die beste Kommunikationsstrategie zu überdenken, wie hier erläutert. Kurz gesagt, Byteps verwendet NCCL nur in einer Maschine, während die Kommunikation zwischen den Maschinen erneut implementiert wird.
Byteps umfasst auch viele Beschleunigungstechniken wie hierarchische Strategie, Pipelinierung, Tensor-Partitionierung, lokale Kommunikation mit Numa-bewährt, vorrangige Planung usw.
Wir bieten ein Schritt-für-Schritt-Tutorial für Sie, um Benchmark-Trainingsaufgaben auszuführen. Der einfachste Weg, um zu beginnen, besteht darin, unsere Docker -Bilder zu verwenden. Unter Dokumentationen finden Sie in der Art und Weise, wie Sie verteilte Jobs und detailliertere Konfigurationen starten. Nachdem Sie Byteps beginnen können, lesen Sie die Best Practice, um die beste Leistung zu erzielen.
Im Folgenden erklären wir, wie Sie Byteps selbst installieren. Es gibt zwei Optionen.
pip3 install byteps
Sie können die neuesten Funktionen ausprobieren, indem Sie direkt aus Master Branch installieren:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
Anmerkungen für oben genannte Optionen:
export BYTEPS_NCCL_HOME=/path/to/nccl angeben. Standardmäßig zeigt es auf /usr/local/nccl .yum install devtoolset-7 . Im Allgemeinen empfehlen wir GCC 4.9 für die beste Kompatibilität (wie man GCC annimmt).Grundlegende Beispiele finden Sie im Beispielordner.
Um die End-to-End-Bewertung in unserem OSDI'20-Papier zu reproduzieren, finden Sie den Code in diesem Repo.
Byteps ist zwar in seinem Kern völlig anders, aber mit Horovod -Schnittstellen kompatibel (danke, Horovod -Community!). Wir haben uns für Horovod -Schnittstellen entschieden, um Ihre Bemühungen zum Testen von Byteps zu minimieren.
Wenn Ihre Aufgaben nur auf Horovods Allreduce und Sendung beruhen, sollten Sie in 1 Minute in Byteps umstellen können. Ersetzen Sie einfach import horovod.tensorflow as hvd durch import byteps.tensorflow as bps und ersetzen Sie dann alle hvd in Ihrem Code durch bps . Wenn Ihr Code hvd.allreduce direkt aufgerufen hat, sollten Sie ihn auch durch bps.push_pull ersetzen.
Viele unserer Beispiele wurden von Horovod kopiert und auf diese Weise modifiziert. Vergleichen Sie beispielsweise das MNIST -Beispiel für Byteps und Horovod.
Byteps unterstützt auch andere native APIs, z. B. Pytorch Distributed Data Parallele und TensorFlow Spiegelte Strategie. Siehe DistributedDataparallel.md und Mirred Strategy.md für die Verwendung.
Byteps unterstützt vorerst das reine CPU -Training nicht. Ein Grund dafür ist, dass die billige PS -Annahme von Byteps nicht für das CPU -Training gilt. Folglich brauchen Sie CUDA und NCCL, um Byteps zu bauen und zu betreiben.
Wir möchten unten die Funktionen haben, und es gibt keine grundlegenden Schwierigkeiten, sie in der Byteps -Architektur zu implementieren. Sie werden jedoch noch nicht implementiert:
[OSDI'20] "Eine einheitliche Architektur zur Beschleunigung des verteilten DNN -Trainings in heterogenen GPU/CPU -Clustern". Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo.
[Sosp'19] "Ein generischer Kommunikationsplaner für verteilte DNN -Schulungsbeschleunigung". Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo. (Code befindet sich in Bytesscheduler Branch)


