byteps
v0.2
BYTEPSは、高性能で一般的な分散トレーニングフレームワークです。 Tensorflow、Keras、Pytorch、およびMxNetをサポートし、TCPまたはRDMAネットワークで実行できます。
バイテップは、既存のオープンソース分散トレーニングフレームワークを大きなマージンで上回ります。たとえば、Bert-Largeトレーニングでは、BYTEPは256 GPUで約90%のスケーリング効率を達成できます(以下を参照)。これはHorovod+NCCLよりもはるかに高くなっています。特定のシナリオでは、BYTEPはHorovod+NCCLと比較してトレーニング速度を2倍にできます。
bpslaunch追加します。pip3 install byteps GluonnLP Toolkitに基づいたBert-Largeトレーニングに関する実験を示します。モデルは混合精度を使用します。
Tesla V100 32GB GPUを使用し、GPUあたり64に等しいバッチサイズを設定します。各マシンには、NVLink対応の8つのV100 GPU(32GBメモリ)があります。マシンは、100 Gbps RDMAネットワークと相互接続されています。これは、AWSで取得できるのと同じハードウェアセットアップです。
Bytepsは、256 GPUでBert-Largeで約90%のスケーリング効率を達成します。コードはこちらから入手できます。比較として、Horovod+NCCLは、エキスパートパラメーターのチューニング後でも、約70%のスケーリング効率を持っています。
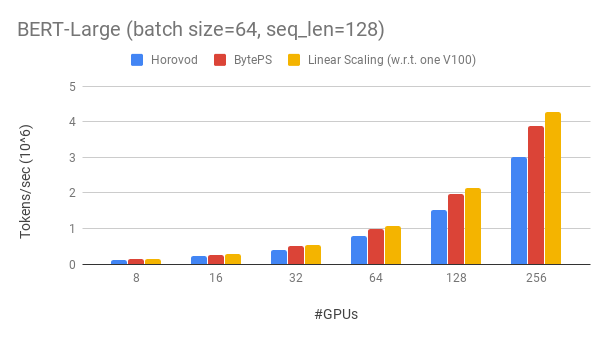
ネットワークが遅いため、BYTEPSはさらに2倍のHorovod+NCCLです。 Performance.mdでより多くの評価結果を見つけることができます。
バイテップはどのようにしてホロボドをそんなに上回ることができますか?主な理由の1つは、BYTEPSがクラウドと共有クラスター用に設計されており、MPIを捨てることです。
MPIはHPCの世界で生まれ、均質なハードウェアで構築されたクラスターと単一のジョブを実行するのに適しています。ただし、クラウド(または社内共有クラスター)は異なります。
これにより、ここで説明されているように、最良のコミュニケーション戦略を再考することになります。要するに、BYTEPSはマシン内でNCCLのみを使用し、マシン間通信を再インプレクトします。
BYTEPSには、階層戦略、パイプライン、テンソルパーティション、NUMA認識ローカルコミュニケーション、優先順位ベースのスケジューリングなど、多くの加速技術も組み込まれています。
ベンチマークトレーニングタスクを実行するための段階的なチュートリアルを提供します。開始する最も簡単な方法は、Docker画像を使用することです。分散ジョブを起動する方法とより詳細な構成については、ドキュメントを参照してください。 Bytepsを開始できたら、ベストプラクティスを読んで最高のパフォーマンスを得ることができます。
以下では、自分でBYTEPSをインストールする方法について説明します。 2つのオプションがあります。
pip3 install byteps
マスターブランチから直接インストールして、最新の機能を試すことができます。
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
2つ以上のオプションのメモ:
export BYTEPS_NCCL_HOME=/path/to/ncclでNCCLパスを指定する必要があります。デフォルトでは/usr/local/ncclを指します。yum install devtoolset-7他のすべてのものに試すことができます。一般に、GCC 4.9を使用して最適な互換性(GCCをピン留めする方法)を使用することをお勧めします。基本的な例は、サンプルフォルダーの下に記載されています。
OSDI'20ペーパーでエンドツーエンドの評価を再現するには、このレポでコードを見つけます。
BYTEPSは、そのコアがまったく違いますが、Horovodインターフェイスと非常に互換性があります(Horovod Community!)。バイトをテストするための努力を最小限に抑えるために、Horovodインターフェイスを選択しました。
タスクがHorovodのAllReduceと放送のみに依存している場合は、1分でバイトに切り替えることができるはずです。 import byteps.tensorflowによってimport horovod.tensorflow as hvd置き換えるだけで、 import byteps.tensorflow as bpsを使用してから、 bpsでコード内のすべてのhvdを置き換えます。コードがhvd.allreduceを直接呼び出した場合は、 bps.push_pullに置き換える必要があります。
私たちの例の多くはHorovodからコピーされ、この方法で修正されました。たとえば、bytepsとhorovodのmnistの例を比較してください。
BYTEPSは、他のネイティブAPI、例えば、Pytorch分散データの並列およびTensorflowミラー戦略もサポートしています。使用方法については、distributedDatapar Allecl.mdおよびmirroredstrategy.mdを参照してください。
BYTEPSは、今のところ純粋なCPUトレーニングをサポートしていません。理由の1つは、BYTEPの安価なPSの仮定がCPUトレーニングには当てはまらないことです。その結果、BYTEPSを構築および実行するには、CUDAとNCCLが必要です。
以下の機能を紹介したいと考えていますが、BYTEPSアーキテクチャにそれらを実装する根本的な困難はありません。ただし、まだ実装されていません。
[OSDI'20]「不均一なGPU/CPUクラスターでの分散DNNトレーニングを加速するための統一されたアーキテクチャ」。 Yimin Jiang、Yibo Zhu、Chang Lan、Bairen Yi、Yong Cui、Chuanxiong Guo。
[SOSP'19]「分散DNNトレーニング加速のための一般的な通信スケジューラ」。 Yanghua Peng、Yibo Zhu、Yangrui Chen、Yixin Bao、Bairen Yi、Chang Lan、Chuan Wu、Chuanxiong Guo。 (コードはByteschedulerブランチにあります)


