byteps
v0.2
Byteps - это высокая производительность и общая распределенная учебная рамка. Он поддерживает Tensorflow, Keras, Pytorch и MxNet и может работать в сети TCP или RDMA.
Byteps превосходит существующие распределенные учебные рамки с открытым исходным кодом с большим отрывом. Например, при обучении BERT-Large байоты могут достигать эффективности масштабирования ~ 90% с 256 графическими процессорами (см. Ниже), что намного выше, чем Horovod+NCCL. В определенных сценариях байозы могут удвоить скорость тренировок по сравнению с Horovod+NCCL.
bpslaunch в качестве команды для запуска задач.pip3 install byteps Мы показываем наш эксперимент по обучению Bert-Large, который основан на инструментарии Gluonnlp. Модель использует смешанную точность.
Мы используем графические процессоры Tesla V100 32 ГБ и устанавливаем размер партии, равный 64 на графический процессор. Каждая машина имеет 8 V100 графических процессоров (память 32 ГБ) с помощью NVLink с поддержкой. Машины взаимосвязаны с сетью RDMA 100 Гбит / с. Это та же самая настройка оборудования, которую вы можете получить на AWS.
Byteps достигает эффективности масштабирования ~ 90% для Bert-Large с 256 графическими процессорами. Код доступен здесь. Для сравнения, Horovod+NCCL обладает эффективностью масштабирования ~ 70% даже после экспертного настройки параметров.
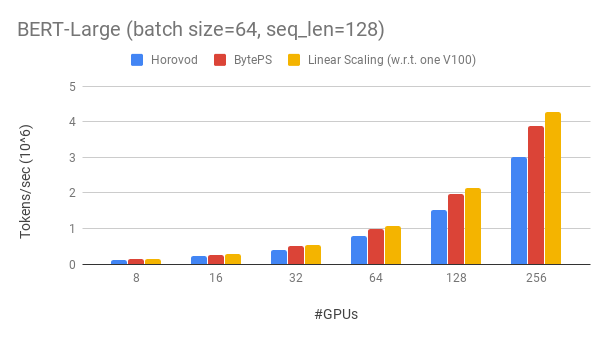
Благодаря более медленной сети Byteps предлагает еще больше преимуществ производительности - до 2x of Horovod+NCCL. Вы можете найти больше результатов оценки на производительности.md.
Как Byteps может так много превзойти Horovod? Одна из основных причин заключается в том, что Byteps предназначено для облачных и общих кластеров и выбрасывает MPI.
MPI родился в мире HPC и хорош для кластера, построенного с однородным оборудованием, и для выполнения одной работы. Тем не менее, облако (или внутренние общие кластеры) отличается.
Это заставляет нас переосмыслить лучшую коммуникационную стратегию, как объяснено здесь. Короче говоря, Byteps использует только NCCL внутри машины, в то же время переосмысливая межмачиновую связь.
Byteps также включает в себя множество методов ускорения, таких как иерархическая стратегия, трубопроводы, тензорное разделение, локальное общение NUMA, планирование на основе приоритетов и т. Д.
Мы предоставляем пошаговое учебное пособие для вас, чтобы выполнить эталонные учебные задачи. Самый простой способ начать - использовать наши изображения Docker. Обратитесь к документациям о том, как запустить распределенные задания и более подробные конфигурации. После того, как вы сможете начать байторы, прочитайте лучшую практику, чтобы получить наилучшую производительность.
Ниже мы объясняем, как установить байторы самостоятельно. Есть два варианта.
pip3 install byteps
Вы можете попробовать последние функции, непосредственно установив из Master Branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
Примечания для двух вышеупомянутых вариантов:
export BYTEPS_NCCL_HOME=/path/to/nccl . По умолчанию он указывает на /usr/local/nccl .yum install devtoolset-7 перед всем остальным. В целом, мы рекомендуем использовать GCC 4.9 для лучшей совместимости (как прикрепить GCC).Основные примеры приведены в папке примера.
Чтобы воспроизвести сквозную оценку в нашей статье Osdi'20, найдите код в этом репо.
Несмотря на то, что они совершенно разные, Byteps очень совместим с интерфейсами Horovod (спасибо, сообщество Horovod!). Мы выбрали интерфейсы Horovod, чтобы минимизировать ваши усилия по тестированию байтов.
Если ваши задачи полагаются только на Allreduce и трансляцию Horovod, вы сможете переключиться на байозы за 1 минуту. Просто замените import horovod.tensorflow as hvd на import byteps.tensorflow as bps , а затем замените все hvd в вашем коде bps . Если ваш код вызывает hvd.allreduce напрямую, вы также должны заменить его на bps.push_pull .
Многие из наших примеров были скопированы из Horovod и модифицированы таким образом. Например, сравните пример MNIST для байторов и Horovod.
Byteps также поддерживает другие нативные API, например, Pytorch Распределенные данные параллельны и стратегию Tensorflow. См. DistributedDataparallel.md и MirroredStrategy.md для использования.
Byteps пока не поддерживает чистое обучение процессора. Одна из причин заключается в том, что дешевое предположение PS о байепах не поддерживается для обучения процессоров. Следовательно, вам нужны CUDA и NCCL, чтобы построить и запустить байтоны.
Мы хотели бы иметь функции ниже, и нет никаких фундаментальных трудностей для их реализации в архитектуре Byteps. Однако они еще не реализованы:
[OSDI'20] «Объединенная архитектура для ускорения распределенного обучения DNN в гетерогенных кластерах GPU/процессора». Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo.
[SOSP'19] «Общий планировщик связи для распределенного ускорения обучения DNN». Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo. (Код находится в филиале Bytescheduler)


