byteps
v0.2
BYTEPS es un marco de capacitación distribuido de alto rendimiento y de alto rendimiento. Admite TensorFlow, Keras, Pytorch y MXNet, y puede ejecutarse en la red TCP o RDMA.
BYTEPS supera a los marcos de capacitación distribuidos de origen abierto existentes por un gran margen. Por ejemplo, en el entrenamiento de Bert-Large, los byteps pueden lograr una eficiencia de escala de ~ 90% con 256 GPU (ver más abajo), que es mucho más alto que Horovod+NCCL. En ciertos escenarios, los byteps pueden duplicar la velocidad de entrenamiento en comparación con Horovod+NCCL.
bpslaunch como comando para iniciar tareas.pip3 install byteps Mostramos nuestro experimento en el entrenamiento de Bert-Large, que se basa en Gluonnlp Toolkit. El modelo utiliza precisión mixta.
Utilizamos Tesla V100 32GB GPU y establecemos el tamaño de lotes igual a 64 por GPU. Cada máquina tiene 8 GPU V100 (memoria de 32 GB) con NVLink habilitado. Las máquinas están interconectadas con una red RDMA de 100 Gbps. Esta es la misma configuración de hardware que puede obtener en AWS.
BYTEPS logra ~ 90% de eficiencia de escala para Bert-Large con 256 GPU. El código está disponible aquí. Como comparación, Horovod+NCCL tiene solo ~ 70% de eficiencia de escala incluso después de un sintonización de parámetros expertos.
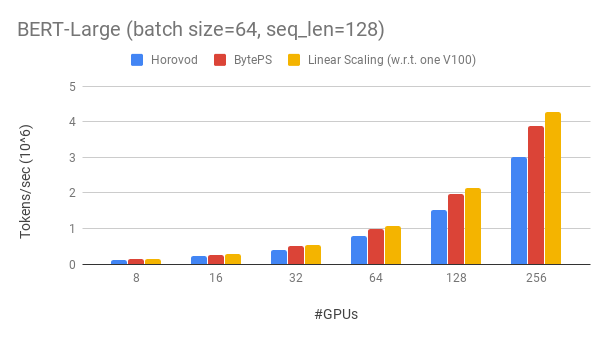
Con una red más lenta, BYTEPS ofrece aún más ventajas de rendimiento: hasta 2 veces más de Horovod+NCCL. Puede encontrar más resultados de evaluación en el rendimiento.md.
¿Cómo pueden los byteps superar a Horovod por tanto? Una de las principales razones es que ByTEPS está diseñado para clústeres de nubes y compartidos, y tira MPI.
MPI nació en el mundo de HPC y es bueno para un clúster construido con hardware homogéneo y para ejecutar un solo trabajo. Sin embargo, la nube (o grupos compartidos internos) es diferente.
Esto nos lleva a repensar la mejor estrategia de comunicación, como se explica aquí. En resumen, BYTEPS solo usa NCCL dentro de una máquina, mientras que vuelve a implementar la comunicación entre máquinas.
BYTEPS también incorpora muchas técnicas de aceleración, como estrategia jerárquica, canalización, partición tensorial, comunicación local con conocimiento, programación basada en prioridades, etc.
Proporcionamos un tutorial paso a paso para que ejecute tareas de capacitación de referencia. La forma más sencilla de comenzar es usar nuestras imágenes Docker. Consulte documentos sobre cómo lanzar trabajos distribuidos y configuraciones más detalladas. Después de que pueda iniciar byteps, lea las mejores prácticas para obtener el mejor rendimiento.
A continuación, explicamos cómo instalar byteps usted mismo. Hay dos opciones.
pip3 install byteps
Puede probar las últimas funciones instalando directamente desde Master Branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
Notas para las dos opciones anteriores:
export BYTEPS_NCCL_HOME=/path/to/nccl . Por defecto, apunta a /usr/local/nccl .yum install devtoolset-7 antes de todo lo demás. En general, recomendamos usar GCC 4.9 para la mejor compatibilidad (cómo fijar el GCC).Se proporcionan ejemplos básicos en la carpeta de ejemplo.
Para reproducir la evaluación de extremo a extremo en nuestro artículo OSDI'20, encuentre el código en este repositorio.
Aunque es totalmente diferente en su núcleo, Byteps es altamente compatible con las interfaces de Horovod (¡gracias, Comunidad Horovod!). Elegimos interfaces Horovod para minimizar sus esfuerzos para probar byteps.
Si sus tareas solo se basan en la Allreduce y la transmisión de Horovod, debería poder cambiar a byteps en 1 minuto. Simplemente reemplace import horovod.tensorflow as hvd por import byteps.tensorflow as bps , y luego reemplace todo hvd en su código por bps . Si su código invoca hvd.allreduce directamente, también debe reemplazarlo por bps.push_pull .
Muchos de nuestros ejemplos fueron copiados de Horovod y modificados de esta manera. Por ejemplo, compare el ejemplo MNIST para Byteps y Horovod.
BYTEPS también es compatible con otras API nativas, por ejemplo, datos distribuidos de Pytorch paralelos y estrategia reflejada con flujo tensor. Ver DistributedDataparallel.md y MirroredStrategy.md para su uso.
BYTEPS no es compatible con la capacitación pura de CPU por ahora. Una razón es que la suposición de PS barata de byteps no se mantiene para el entrenamiento de CPU. En consecuencia, necesita CUDA y NCCL para construir y ejecutar byteps.
Nos gustaría tener a continuación características, y no hay dificultad fundamental para implementarlas en la arquitectura de Byteps. Sin embargo, aún no se implementan:
[OSDI'20] "Una arquitectura unificada para acelerar el entrenamiento DNN distribuido en grupos de GPU/CPU heterogéneos". Yimin Jiang, Yibo Zhu, Chang Lan, Bairen YI, Yong Cui, Chuanxiong Guo.
[Sosp'19] "Un programador de comunicación genérico para la aceleración de capacitación DNN distribuida". Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen YI, Chang Lan, Chuan Wu, Chuanxiong Guo. (El código está en la rama de Bytescheduler)


