byteps
v0.2
O BYTEPS é uma estrutura de treinamento distribuída em alto desempenho e distribuição geral. Ele suporta tensorflow, keras, pytorch e mxnet e pode ser executado na rede TCP ou RDMA.
Os byteps superaem as estruturas de treinamento distribuídas de código aberto existentes por uma grande margem. Por exemplo, no treinamento de Bert-Large, os bytops podem atingir ~ 90% de eficiência de escala com 256 GPUs (veja abaixo), que é muito maior que o Horovod+NCCL. Em certos cenários, os bytops podem dobrar a velocidade de treinamento em comparação com o Horovod+NCCL.
bpslaunch como o comando para iniciar tarefas.pip3 install byteps Mostramos nosso experimento no treinamento Bert-Large, que é baseado no kit de ferramentas Gluonnlp. O modelo usa precisão mista.
Usamos GPUs Tesla V100 32 GB e definimos o tamanho do lote igual a 64 por GPU. Cada máquina possui 8 GPUs V100 (memória de 32 GB) com habilitado para NVLink. As máquinas estão interconectadas com a rede RDMA de 100 Gbps. Esta é a mesma configuração de hardware que você pode obter na AWS.
Os byteps atingem ~ 90% de eficiência de escala para Bert-Large com 256 GPUs. O código está disponível aqui. Como comparação, o HOROVOD+NCCL tem apenas ~ 70% de eficiência de escala, mesmo após o ajuste dos parâmetros de especialistas.
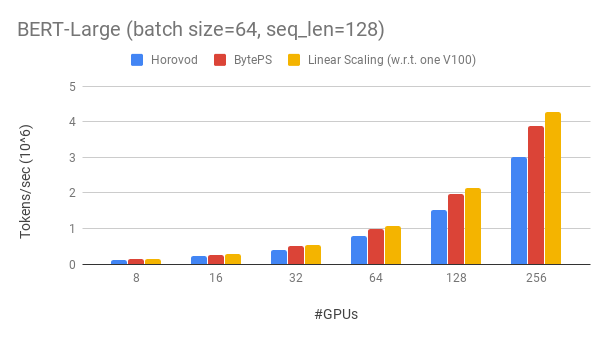
Com uma rede mais lenta, o ByTeps oferece ainda mais vantagens de desempenho - até 2x de Horovod+NCCL. Você pode encontrar mais resultados de avaliação no desempenho.md.
Como os byteps podem superar o Horovod por tanto? Uma das principais razões é que o bytops foi projetado para clusters em nuvem e compartilhado e joga fora o MPI.
O MPI nasceu no mundo do HPC e é bom para um cluster construído com hardware homogêneo e para administrar um único emprego. No entanto, a nuvem (ou clusters compartilhados internos) é diferente.
Isso nos leva a repensar a melhor estratégia de comunicação, conforme explicado aqui. Em resumo, o ByTeps usa apenas o NCCL dentro de uma máquina, enquanto reimplementa a comunicação entre máquinas.
Os byteps também incorporam muitas técnicas de aceleração, como estratégia hierárquica, pipelining, particionamento tensor, comunicação local com reconhecimento de NUMA, agendamento baseado em prioridade etc.
Fornecemos um tutorial passo a passo para você executar tarefas de treinamento de referência. A maneira mais simples de começar é usar nossas imagens do Docker. Consulte documentações sobre como iniciar trabalhos distribuídos e configurações mais detalhadas. Depois de iniciar o ByTeps, leia as melhores práticas para obter o melhor desempenho.
Abaixo, explicamos como instalar bytops sozinho. Existem duas opções.
pip3 install byteps
Você pode experimentar os recursos mais recentes instalando diretamente no Master Branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
Notas para acima de duas opções:
export BYTEPS_NCCL_HOME=/path/to/nccl . Por padrão, ele aponta para /usr/local/nccl .yum install devtoolset-7 antes de tudo. Em geral, recomendamos o uso do GCC 4.9 para obter a melhor compatibilidade (como fixar o GCC).Exemplos básicos são fornecidos na pasta Exemplo.
Para reproduzir a avaliação de ponta a ponta em nosso artigo OSDI'20, encontre o código neste repo.
Embora seja totalmente diferente em sua essência, o ByTeps é altamente compatível com as interfaces Horovod (obrigado, comunidade Horovod!). Escolhemos interfaces Horovod para minimizar seus esforços para testar byteps.
Se suas tarefas dependem apenas do Allreduce e da Broadcast de Horovod, você poderá mudar para byteps em 1 minuto. Basta substituir import horovod.tensorflow as hvd por import byteps.tensorflow as bps e, em seguida, substitua todo hvd no seu código pelo bps . Se o seu código invocar hvd.allreduce diretamente, você também deverá substituí -lo por bps.push_pull .
Muitos de nossos exemplos foram copiados de Horovod e modificados dessa maneira. Por exemplo, compare o exemplo mnist para byteps e Horovod.
Os byteps também suportam outras APIs nativas, por exemplo, Pytorch distribuiu dados paralelos e tensorflow espelhou a estratégia. Consulte DistributedDataparallel.md e MirroredStrategy.md para uso.
ByTeps não suporta treinamento puro da CPU por enquanto. Uma razão é que a suposição barata do PS de byteps não se mantém para o treinamento da CPU. Consequentemente, você precisa de CUDA e NCCL para construir e executar byteps.
Gostaríamos de ter os recursos abaixo, e não há dificuldade fundamental para implementá -los na arquitetura de byteps. No entanto, eles ainda não foram implementados:
[Osdi'20] "Uma arquitetura unificada para acelerar o treinamento de DNN distribuído em clusters heterogêneos de GPU/CPU". Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo.
[SOSP'19] "Um agendador de comunicação genérica para a aceleração de treinamento da DNN distribuída". Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo. (O código está no ByteScheduler Branch)


