byteps
v0.2
Byteps est un cadre de formation haute performance et général distribué. Il prend en charge TensorFlow, Keras, Pytorch et MXNET, et peut fonctionner sur le réseau TCP ou RDMA.
Byteps surpasse les cadres de formation distribués open source existants par une grande marge. Par exemple, lors de l'entraînement Bert-Large, les byteps peuvent atteindre une efficacité de mise à l'échelle de ~ 90% avec 256 GPU (voir ci-dessous), ce qui est beaucoup plus élevé que Horovod + NCCL. Dans certains scénarios, les byteps peuvent doubler la vitesse d'entraînement par rapport à Horovod + NCCL.
bpslaunch comme commande pour lancer des tâches.pip3 install byteps Nous montrons notre expérience sur la formation Bert-Garg, qui est basée sur la boîte à outils GluonnLP. Le modèle utilise une précision mixte.
Nous utilisons des GPU Tesla V100 32 Go et définissons la taille du lot égale à 64 par GPU. Chaque machine dispose de 8 GPU V100 (mémoire 32 Go) avec NvLink compatible. Les machines sont interconnectées avec un réseau RDMA de 100 Gbps. Il s'agit de la même configuration matérielle que vous pouvez obtenir sur AWS.
Les byteps atteignent une efficacité de mise à l'échelle de ~ 90% pour Bert-Garg avec 256 GPU. Le code est disponible ici. À titre de comparaison, Horovod + NCCL n'a que l'efficacité de mise à l'échelle de ~ 70% même après le tunning des paramètres experts.
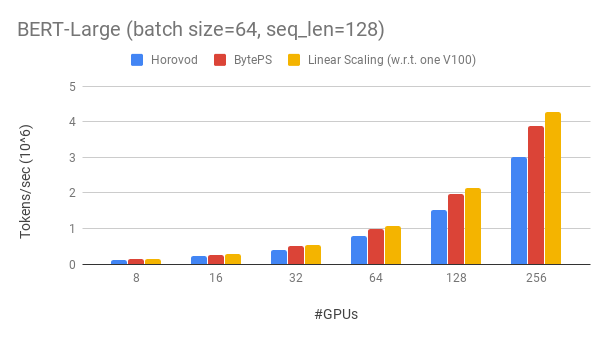
Avec un réseau plus lent, Byteps offre encore plus d'avantages de performances - jusqu'à 2x de Horovod + NCCL. Vous pouvez trouver plus de résultats d'évaluation sur Performance.md.
Comment les byteps peuvent-ils surpasser tellement Horovod? L'une des principales raisons est que Byteps est conçu pour les clusters cloud et partagé, et jette MPI.
MPI est né dans le monde du HPC et est bon pour un cluster construit avec du matériel homogène et pour exécuter un seul travail. Cependant, le cloud (ou les clusters partagés en interne) sont différents.
Cela nous amène à repenser la meilleure stratégie de communication, comme expliqué ici. En bref, les byteps n'utilisent que le NCCL à l'intérieur d'une machine, tout en réimplémentant la communication inter-machine.
Byteps intègre également de nombreuses techniques d'accélération telles que la stratégie hiérarchique, le pipeline, le partitionnement du tenseur, la communication locale Awa-Aware, la planification basée sur la priorité, etc.
Nous fournissons un tutoriel étape par étape pour que vous puissiez exécuter des tâches de formation de référence. La façon la plus simple de commencer est d'utiliser nos images Docker. Reportez-vous à des documents pour lancer des travaux distribués et des configurations plus détaillées. Une fois que vous pouvez commencer Byteps, lisez les meilleures pratiques pour obtenir les meilleures performances.
Ci-dessous, nous expliquons comment installer les byteps par vous-même. Il y a deux options.
pip3 install byteps
Vous pouvez essayer les dernières fonctionnalités en installant directement à partir de Master Branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
Remarques pour deux options ci-dessus:
export BYTEPS_NCCL_HOME=/path/to/nccl . Par défaut, il pointe vers /usr/local/nccl .yum install devtoolset-7 avant tout le reste. En général, nous vous recommandons d'utiliser GCC 4.9 pour une meilleure compatibilité (comment épingler GCC).Des exemples de base sont fournis dans l'exemple de dossier.
Pour reproduire l'évaluation de bout en bout dans notre article OSDI'20, trouvez le code de ce dépôt.
Bien qu'il soit totalement différent à la base, Byteps est très compatible avec les interfaces Horovod (merci, communauté Horovod!). Nous avons choisi les interfaces Horovod afin de minimiser vos efforts pour tester les bytes.
Si vos tâches ne reposent que sur Allreduce et diffusion d'Horovod, vous devriez pouvoir passer à des byteps en 1 minute. Remplacez simplement import horovod.tensorflow as hvd par import byteps.tensorflow as bps , puis remplacez tous hvd dans votre code par bps . Si votre code invoque directement hvd.allreduce , vous devez également le remplacer par bps.push_pull .
Beaucoup de nos exemples ont été copiés à partir de Horovod et modifiés de cette manière. Par exemple, comparez l'exemple MNIST pour les byteps et Horovod.
BytePS prend également en charge d'autres API natives, par exemple, des données distribuées Pytorch parallèles et une stratégie en miroir TensorFlow. Voir DistributedDataparallel.md et MirroredStrategy.md pour l'utilisation.
Byteps ne prend pas en charge la formation pure du processeur pour l'instant. L'une des raisons est que l'hypothèse PS bon marché des byteps ne tient pas pour la formation du processeur. Par conséquent, vous avez besoin de CUDA et NCCL pour construire et exécuter des byteps.
Nous aimerions avoir des fonctionnalités ci-dessous, et il n'y a pas de difficulté fondamentale pour les mettre en œuvre dans l'architecture Byteps. Cependant, ils ne sont pas encore mis en œuvre:
[OSDI'20] "Une architecture unifiée pour accélérer la formation DNN distribuée dans les grappes hétérogènes GPU / CPU". Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo.
[SOSP'19] "Un planificateur de communication générique pour l'accélération de formation DNN distribuée". Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo. (Le code est à Bytescheduler Branch)


