byteps
v0.2
Byteps是高性能和一般分布式培训框架。它支持TensorFlow,Keras,Pytorch和MXNET,并且可以在TCP或RDMA网络上运行。
比较胜过现有的开源分布式培训框架的优于大幅度。例如,在Bert-large训练中,使用256 GPU可以实现〜90%的缩放效率(见下文),这比Horovod+NCCL高得多。在某些情况下,与Horovod+NCCL相比,训练速度可以使训练速度增加一倍。
bpslaunch作为启动任务的命令。pip3 install byteps 我们展示了基于Gluonnlp工具包的Bert-Large训练实验。该模型使用混合精度。
我们使用Tesla V100 32GB GPU,将批量大小等于每GPU 64。每台机器具有8个V100 GPU(32GB内存),并具有NVLINK启用。机器与100 Gbps RDMA网络相互连接。这是您可以在AWS上获得的硬件设置。
Byteps具有256 GPU的BERT-LARGE的缩放效率约为90%。该代码可在此处使用。作为比较,即使在专家参数调谐之后,Horovod+NCCL的缩放效率也只有〜70%。
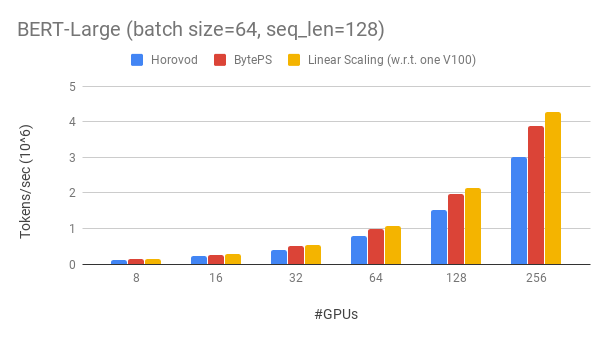
借助较慢的网络,ByTeps提供了更多的性能优势 - 最高2倍Horovod+NCCL。您可以在performance.md上找到更多评估结果。
BOYTEPS如何超越Horovod?主要原因之一是ByTeps是为云和共享簇设计的,并扔掉了MPI。
MPI出生于HPC世界,非常适合一个由均质硬件构建的集群,也可以运行一份工作。但是,云(或内部共享簇)是不同的。
如这里所述,这使我们重新考虑了最佳的沟通策略。简而言之,小节仅在机器内使用NCCL,而重新构想了机间通信。
ByTeps还结合了许多加速技术,例如层次策略,管道张力,张量分区,NUMA了解本地通信,基于优先级的调度等等。
我们为您提供一个基准培训任务的分步教程。最简单的开始方法是使用我们的Docker图像。请参阅文档以获取如何启动分布式作业和更详细的配置。启动byteps之后,请阅读最佳练习以获得最佳性能。
在下面,我们说明如何自己安装字节。有两个选择。
pip3 install byteps
您可以通过直接从主分支机构安装来尝试最新功能:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
上述两个选项的注释:
export BYTEPS_NCCL_HOME=/path/to/nccl指定NCCL路径。默认情况下,它指向/usr/local/nccl 。yum install devtoolset-7 。通常,我们建议使用GCC 4.9进行最佳兼容性(如何固定GCC)。示例文件夹下提供了基本示例。
要在OSDI'20论文中重现端到端评估,请在此存储库中找到代码。
尽管Byteps完全不同,但与Horovod接口高度兼容(谢谢Horovod社区!)。我们选择了Horovod界面,以最大程度地减少您在测试字节上的努力。
如果您的任务仅依赖于Horovod的Alleduce和广播,则应在1分钟内切换到字节。只需将import horovod.tensorflow as hvd import byteps.tensorflow as bps hvd,然后用bps替换代码中的所有hvd 。如果您的代码直接调用hvd.allreduce ,则还应由bps.push_pull替换。
我们的许多例子都是从Horovod复制的,并以这种方式进行了修改。例如,比较字节和horovod的mnist示例。
ByTeps还支持其他本机API,例如Pytorch分布式数据并行和TensorFlow镜像策略。有关使用情况,请参见DistributeDataParallel.MD和MirroredStrategy.md。
字节暂时不支持纯CPU培训。原因之一是,廉价的PS假设不适合CPU培训。因此,您需要CUDA和NCCL才能构建和运行Byteps。
我们希望具有以下功能,并且在Byteps Architecture中实现它们没有根本的困难。但是,它们尚未实施:
[OSDI'20]“在异质GPU/CPU群集中加速分布式DNN培训的统一体系结构”。 Yimin Jiang,Yibo Zhu,Chang Lan,Bairen Yi,Yong Cui,Chuanxiong Guo。
[SOSP'19]“分布式DNN培训加速的通用通信调度程序”。 Yangua Peng,Yibo Zhu,Yangrui Chen,Yixin Bao,Bairen YI,Chang Lan,Chuan Wu,Chuanxiong Guo。 (代码位于Bytescheduler分支)


