byteps
v0.2
Byteps adalah kerangka kerja pelatihan yang didistribusikan dengan kinerja tinggi dan umum. Ini mendukung TensorFlow, Kera, Pytorch, dan MXNet, dan dapat berjalan pada jaringan TCP atau RDMA.
Byteps mengungguli kerangka kerja pelatihan terdistribusi bersumber terbuka dengan margin besar. Misalnya, pada pelatihan Bert-Large, byteps dapat mencapai ~ 90% efisiensi penskalaan dengan 256 GPU (lihat di bawah), yang jauh lebih tinggi dari Horovod+NCCL. Dalam skenario tertentu, bytep dapat menggandakan kecepatan pelatihan dibandingkan dengan Horovod+NCCL.
bpslaunch sebagai perintah untuk meluncurkan tugas.pip3 install byteps Kami menunjukkan eksperimen kami tentang pelatihan Bert-Large, yang didasarkan pada Gluonnlp Toolkit. Model menggunakan presisi campuran.
Kami menggunakan GPU Tesla V100 32GB dan mengatur ukuran batch sama dengan 64 per GPU. Setiap mesin memiliki 8 V100 GPU (memori 32GB) dengan NVLink-Enabled. Mesin saling terhubung dengan jaringan RDMA 100 Gbps. Ini adalah pengaturan perangkat keras yang sama yang bisa Anda dapatkan di AWS.
Byteps mencapai ~ efisiensi penskalaan 90% untuk Bert-Large dengan 256 GPU. Kode tersedia di sini. Sebagai perbandingan, Horovod+NCCL hanya memiliki ~ 70% efisiensi penskalaan bahkan setelah penyetelan parameter ahli.
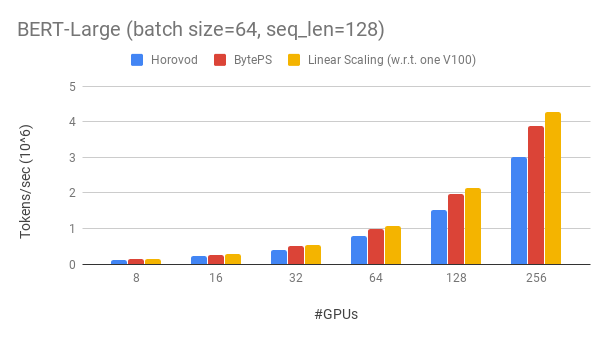
Dengan jaringan yang lebih lambat, Byteps menawarkan lebih banyak keunggulan kinerja - hingga 2x dari Horovod+NCCL. Anda dapat menemukan lebih banyak hasil evaluasi di Performance.md.
Bagaimana byteps bisa mengungguli Horovod dengan begitu banyak? Salah satu alasan utama adalah bahwa Byteps dirancang untuk cloud dan cluster bersama, dan membuang MPI.
MPI lahir di dunia HPC dan baik untuk sekelompok yang dibangun dengan perangkat keras yang homogen dan untuk menjalankan satu pekerjaan. Namun, cloud (atau cluster bersama in-house) berbeda.
Ini mengarahkan kita untuk memikirkan kembali strategi komunikasi terbaik, seperti yang dijelaskan di sini. Singkatnya, byteps hanya menggunakan NCCL di dalam mesin, sambil mengimplementasikan kembali komunikasi antar mesin.
Byteps juga menggabungkan banyak teknik akselerasi seperti strategi hierarkis, pipa, partisi tensor, komunikasi lokal yang sadar num, penjadwalan berbasis prioritas, dll.
Kami memberikan tutorial langkah demi langkah bagi Anda untuk menjalankan tugas pelatihan benchmark. Cara paling sederhana untuk memulai adalah dengan menggunakan gambar Docker kami. Lihat dokumentasi untuk cara meluncurkan pekerjaan terdistribusi dan konfigurasi yang lebih rinci. Setelah Anda dapat memulai byteps, baca praktik terbaik untuk mendapatkan kinerja terbaik.
Di bawah ini, kami menjelaskan cara menginstal bytep sendiri. Ada dua opsi.
pip3 install byteps
Anda dapat mencoba fitur terbaru dengan langsung menginstal dari Master Branch:
git clone --recursive https://github.com/bytedance/byteps
cd byteps
python3 setup.py install
Catatan untuk dua opsi di atas:
export BYTEPS_NCCL_HOME=/path/to/nccl . Secara default itu menunjuk ke /usr/local/nccl .yum install devtoolset-7 sebelum yang lainnya. Secara umum, kami sarankan menggunakan GCC 4.9 untuk kompatibilitas terbaik (cara menyematkan GCC).Contoh dasar disediakan di bawah folder contoh.
Untuk mereproduksi evaluasi ujung ke ujung dalam makalah OSDI'20 kami, temukan kode di repo ini.
Meskipun sama sekali berbeda pada intinya, Byteps sangat kompatibel dengan antarmuka Horovod (terima kasih, komunitas Horovod!). Kami memilih antarmuka Horovod untuk meminimalkan upaya Anda untuk menguji byteps.
Jika tugas Anda hanya mengandalkan Allreduce dan Broadcast Horovod, Anda harus dapat beralih ke byteps dalam 1 menit. Cukup ganti import horovod.tensorflow as hvd dengan import byteps.tensorflow as bps , dan kemudian ganti semua hvd dalam kode Anda dengan bps . Jika kode Anda memanggil hvd.allreduce secara langsung, Anda juga harus menggantinya dengan bps.push_pull .
Banyak contoh kami disalin dari Horovod dan dimodifikasi dengan cara ini. Misalnya, bandingkan contoh MNIST untuk byteps dan Horovod.
BYTEPS juga mendukung API asli lainnya, misalnya, data paralel terdistribusi Pytorch dan strategi cermin TensorFlow. Lihat distributedDataParallel.md dan mirroredstrategy.md untuk penggunaan.
Byteps tidak mendukung pelatihan CPU murni untuk saat ini. Salah satu alasannya adalah bahwa asumsi PS murah dari byteps tidak berlaku untuk pelatihan CPU. Akibatnya, Anda membutuhkan CUDA dan NCCL untuk membangun dan menjalankan byteps.
Kami ingin memiliki fitur di bawah ini, dan tidak ada kesulitan mendasar untuk mengimplementasikannya dalam arsitektur Byteps. Namun, mereka belum diimplementasikan:
[OSDI'20] "Arsitektur terpadu untuk mempercepat pelatihan DNN terdistribusi dalam kelompok GPU/CPU yang heterogen". Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, Chuanxiong Guo.
[SOSP'19] "Penjadwal komunikasi generik untuk akselerasi pelatihan DNN terdistribusi". Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, Chuanxiong Guo. (Kode ada di Cabang Bytescheduler)


